Activation functions introduce non-linearity into neural networks, enabling them to model complex patterns by transforming input signals within each neuron. Loss functions measure the difference between predicted outputs and actual targets, guiding the optimization process to improve model accuracy. Together, these functions play distinct but complementary roles in training effective artificial intelligence models.
Table of Comparison
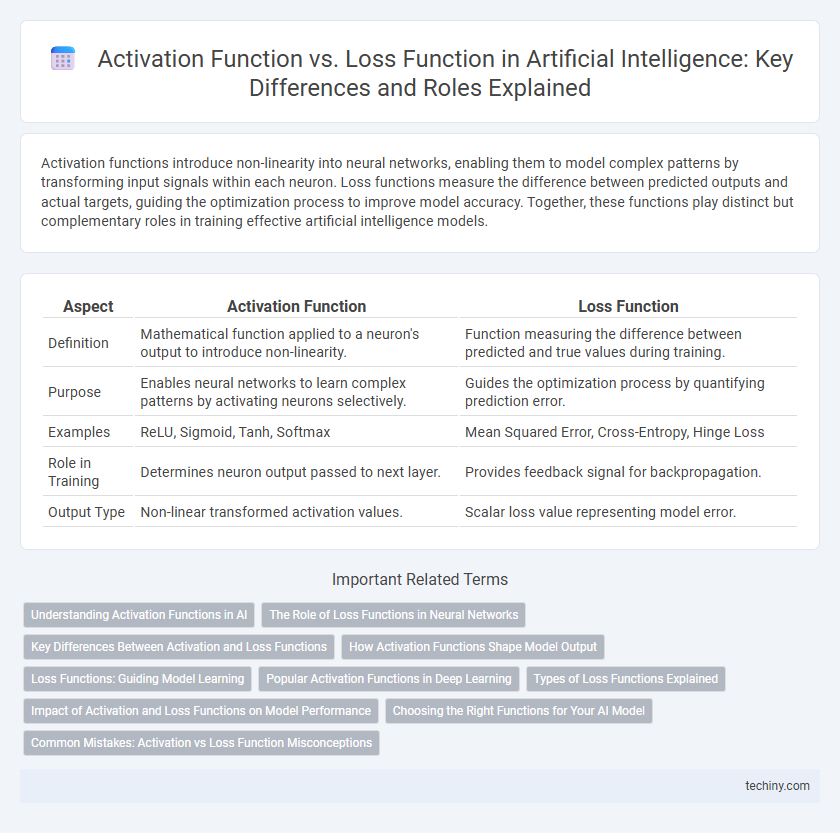
| Aspect | Activation Function | Loss Function |
|---|---|---|
| Definition | Mathematical function applied to a neuron's output to introduce non-linearity. | Function measuring the difference between predicted and true values during training. |
| Purpose | Enables neural networks to learn complex patterns by activating neurons selectively. | Guides the optimization process by quantifying prediction error. |
| Examples | ReLU, Sigmoid, Tanh, Softmax | Mean Squared Error, Cross-Entropy, Hinge Loss |
| Role in Training | Determines neuron output passed to next layer. | Provides feedback signal for backpropagation. |
| Output Type | Non-linear transformed activation values. | Scalar loss value representing model error. |
Understanding Activation Functions in AI
Activation functions in AI determine the output of neural network nodes by introducing non-linearity, enabling models to learn complex patterns. Common types include ReLU, Sigmoid, and Tanh, each impacting convergence speed and model accuracy differently. Proper selection of activation functions is essential for optimizing neural network performance and ensuring effective gradient propagation during training.
The Role of Loss Functions in Neural Networks
Loss functions in neural networks quantify the difference between the predicted output and the actual target, guiding the optimization process by signaling how well the model performs. They are essential for training algorithms like gradient descent, as they provide the error metric that is minimized to improve model accuracy. Common loss functions include Mean Squared Error for regression tasks and Cross-Entropy Loss for classification problems, each playing a pivotal role in shaping the network's learning process.
Key Differences Between Activation and Loss Functions
Activation functions introduce non-linearity to neural networks by transforming input signals within neurons, enabling complex pattern recognition, while loss functions quantify the difference between predicted outputs and actual targets to guide model optimization. Key differences include their roles--activation functions operate at each neuron during forward propagation, whereas loss functions evaluate overall model performance after predictions. Activation functions affect signal processing internally, whereas loss functions drive parameter updates by measuring prediction errors during training.
How Activation Functions Shape Model Output
Activation functions in artificial intelligence determine the output of neural network nodes by introducing non-linearity, which enables models to capture complex patterns in data. Common activation functions like ReLU, sigmoid, and tanh directly influence the range and distribution of model outputs, shaping how information propagates through layers. By transforming weighted inputs, activation functions control the model's ability to learn intricate features, contrasting with loss functions that evaluate prediction errors during training.
Loss Functions: Guiding Model Learning
Loss functions play a critical role in guiding model learning by quantifying the difference between predicted outputs and actual targets, enabling the adjustment of model parameters during training. Common loss functions like Mean Squared Error (MSE) for regression and Cross-Entropy Loss for classification provide measurable feedback that drives optimization algorithms such as gradient descent. Selecting an appropriate loss function ensures efficient convergence and improves model accuracy by aligning training objectives with specific problem goals.
Popular Activation Functions in Deep Learning
Popular activation functions in deep learning include ReLU (Rectified Linear Unit), Sigmoid, and Tanh, each serving to introduce non-linearity into neural networks, enabling them to learn complex patterns. ReLU is favored for its simplicity and efficiency in mitigating the vanishing gradient problem, whereas Sigmoid and Tanh are often used in specific scenarios such as binary classification and sequence modeling. These activation functions work alongside loss functions, which measure prediction errors, but serve fundamentally different purposes in training deep learning models.
Types of Loss Functions Explained
Loss functions quantify the difference between predicted and actual outputs, guiding model optimization through minimization. Common types of loss functions include Mean Squared Error (MSE) for regression tasks, Cross-Entropy Loss for classification problems, and Hinge Loss used in support vector machines. Each type plays a critical role in shaping the accuracy and efficiency of artificial neural networks by providing specific error metrics tailored to different machine learning objectives.
Impact of Activation and Loss Functions on Model Performance
Activation functions such as ReLU, sigmoid, and tanh play a crucial role in introducing non-linearity into neural networks, enabling models to learn complex patterns and improve accuracy. Loss functions like cross-entropy and mean squared error directly influence the optimization process by quantifying prediction errors, guiding weight updates to minimize discrepancies between predicted and actual outputs. The combined choice of activation and loss functions significantly affects convergence speed, model generalization, and overall performance in AI-driven tasks.
Choosing the Right Functions for Your AI Model
Selecting the appropriate activation function, such as ReLU for hidden layers or softmax for output layers, directly impacts the model's ability to learn complex patterns and make accurate predictions. Choosing a suitable loss function, like cross-entropy for classification tasks or mean squared error for regression, ensures that the model's training process effectively minimizes errors aligned with the problem type. Balancing the relationship between activation and loss functions optimizes convergence speed and overall performance in AI model training.
Common Mistakes: Activation vs Loss Function Misconceptions
Confusing activation functions with loss functions is a prevalent mistake in artificial intelligence, as activation functions like ReLU or sigmoid control neuron output transformations, while loss functions such as cross-entropy or mean squared error evaluate model prediction errors. Misinterpreting their roles often leads to improper model design, hindering convergence and performance. Understanding that activation functions introduce non-linearity in neural networks, whereas loss functions quantify the discrepancy between predicted and actual outcomes, is essential for effective deep learning implementation.
Activation Function vs Loss Function Infographic