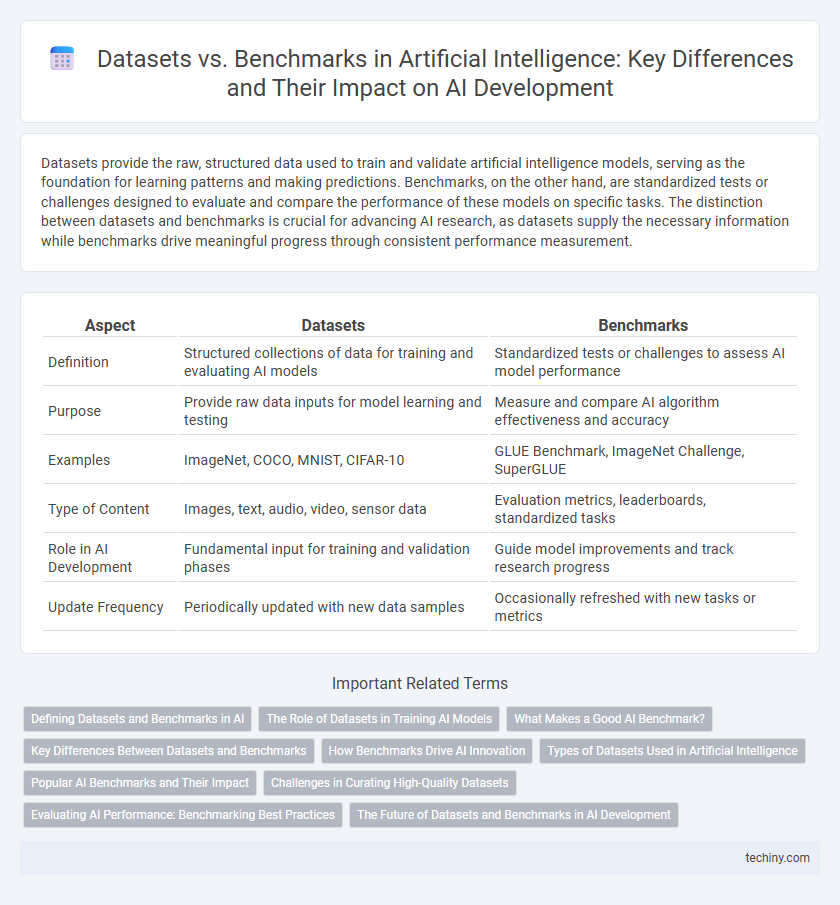
Datasets provide the raw, structured data used to train and validate artificial intelligence models, serving as the foundation for learning patterns and making predictions. Benchmarks, on the other hand, are standardized tests or challenges designed to evaluate and compare the performance of these models on specific tasks. The distinction between datasets and benchmarks is crucial for advancing AI research, as datasets supply the necessary information while benchmarks drive meaningful progress through consistent performance measurement.
Table of Comparison
| Aspect | Datasets | Benchmarks |
|---|---|---|
| Definition | Structured collections of data for training and evaluating AI models | Standardized tests or challenges to assess AI model performance |
| Purpose | Provide raw data inputs for model learning and testing | Measure and compare AI algorithm effectiveness and accuracy |
| Examples | ImageNet, COCO, MNIST, CIFAR-10 | GLUE Benchmark, ImageNet Challenge, SuperGLUE |
| Type of Content | Images, text, audio, video, sensor data | Evaluation metrics, leaderboards, standardized tasks |
| Role in AI Development | Fundamental input for training and validation phases | Guide model improvements and track research progress |
| Update Frequency | Periodically updated with new data samples | Occasionally refreshed with new tasks or metrics |
Defining Datasets and Benchmarks in AI
Datasets in AI consist of structured collections of data used to train, validate, and test machine learning models, typically comprising labeled examples across various domains such as images, text, or sensor readings. Benchmarks are standardized evaluation frameworks that use specific datasets and performance metrics to compare different AI models' effectiveness on defined tasks like image classification or natural language processing. Defining datasets involves curating representative, high-quality data samples, while benchmarks establish consistent protocols and metrics to assess model generalization and robustness.
The Role of Datasets in Training AI Models
Datasets play a crucial role in training AI models by providing the diverse and high-quality data necessary for algorithms to learn patterns and improve accuracy. Large-scale datasets such as ImageNet, COCO, and OpenAI's GPT-3 dataset enable supervised learning, reinforcing model capabilities across image recognition, natural language processing, and other domains. The quality, size, and relevance of these datasets fundamentally influence the generalization and performance of AI systems during deployment.
What Makes a Good AI Benchmark?
A good AI benchmark requires diverse, representative datasets that capture real-world complexity and challenges, ensuring comprehensive model evaluation. High-quality benchmarks offer standardized tasks with clear metrics, enabling valid comparisons across different AI models and fostering reproducibility. Scalability and continuous updates are essential to adapt to evolving AI capabilities and maintain relevance over time.
Key Differences Between Datasets and Benchmarks
Datasets consist of raw, labeled or unlabeled data used to train and validate artificial intelligence models, while benchmarks are standardized evaluation frameworks that test model performance against predefined tasks or criteria. Key differences include that datasets provide the foundational data required for learning, whereas benchmarks assess the effectiveness and generalizability of AI models by comparing results across multiple approaches. Benchmarks often include specific metrics and challenges that promote consistent evaluation, making them essential for measuring progress in AI research.
How Benchmarks Drive AI Innovation
Benchmarks play a critical role in driving AI innovation by providing standardized tasks and metrics that enable researchers to objectively evaluate model performance across diverse datasets. By setting clear performance targets and fostering competition, benchmarks accelerate the development of more accurate, efficient, and generalizable AI algorithms. The continuous evolution of benchmarks stimulates progress in natural language processing, computer vision, and reinforcement learning by highlighting current model limitations and guiding future research directions.
Types of Datasets Used in Artificial Intelligence
In Artificial Intelligence, datasets are categorized into structured, unstructured, and semi-structured types, each crucial for training and evaluating models. Structured datasets, like tabular data in CSV files, support supervised learning algorithms, while unstructured datasets include images, audio, and text essential for deep learning tasks. Semi-structured data formats, such as JSON and XML, offer flexibility by combining organization with heterogeneous data types, facilitating diverse AI applications.
Popular AI Benchmarks and Their Impact
Popular AI benchmarks like ImageNet, GLUE, and COCO have revolutionized the evaluation of machine learning models by providing standardized datasets and metrics that drive innovation and comparability. These benchmarks enable researchers to systematically assess model performance across tasks such as image classification, natural language understanding, and object detection. As a result, they have become critical tools in advancing state-of-the-art AI technologies and fostering reproducible research.
Challenges in Curating High-Quality Datasets
Curating high-quality datasets for artificial intelligence involves addressing challenges such as data bias, incomplete annotations, and ensuring diversity to avoid skewed model performance. Managing large-scale data collection requires rigorous validation protocols to maintain accuracy and relevance while mitigating privacy concerns and ethical considerations. The complexity of balancing dataset size, quality, and representativeness directly impacts the reliability of AI benchmarks used for model evaluation.
Evaluating AI Performance: Benchmarking Best Practices
Evaluating AI performance requires carefully selecting datasets that reflect real-world scenarios and diverse challenges to ensure model robustness. Benchmarks serve as standardized tests that compare AI systems across consistent metrics, enabling objective assessment of improvements and capabilities. Best practices in benchmarking emphasize transparency, reproducibility, and comprehensive coverage of performance dimensions such as accuracy, efficiency, and fairness.
The Future of Datasets and Benchmarks in AI Development
Datasets and benchmarks remain pivotal in advancing AI development by providing structured environments for training and evaluation. The future of AI hinges on increasingly diverse, large-scale datasets that capture complex, real-world scenarios, enhancing model robustness and generalization. Emerging benchmarks will prioritize ethical AI, fairness, and transparency, facilitating more reliable and accountable AI systems across various applications.
Datasets vs Benchmarks Infographic