Word2Vec generates word embeddings by predicting surrounding words in a sentence, capturing contextual relationships through a shallow neural network model. GloVe constructs embeddings based on aggregated global word co-occurrence statistics from a corpus, emphasizing the overall frequency patterns between word pairs. Both methods produce dense vector representations that improve natural language processing tasks but differ in their reliance on local context versus global count information.
Table of Comparison
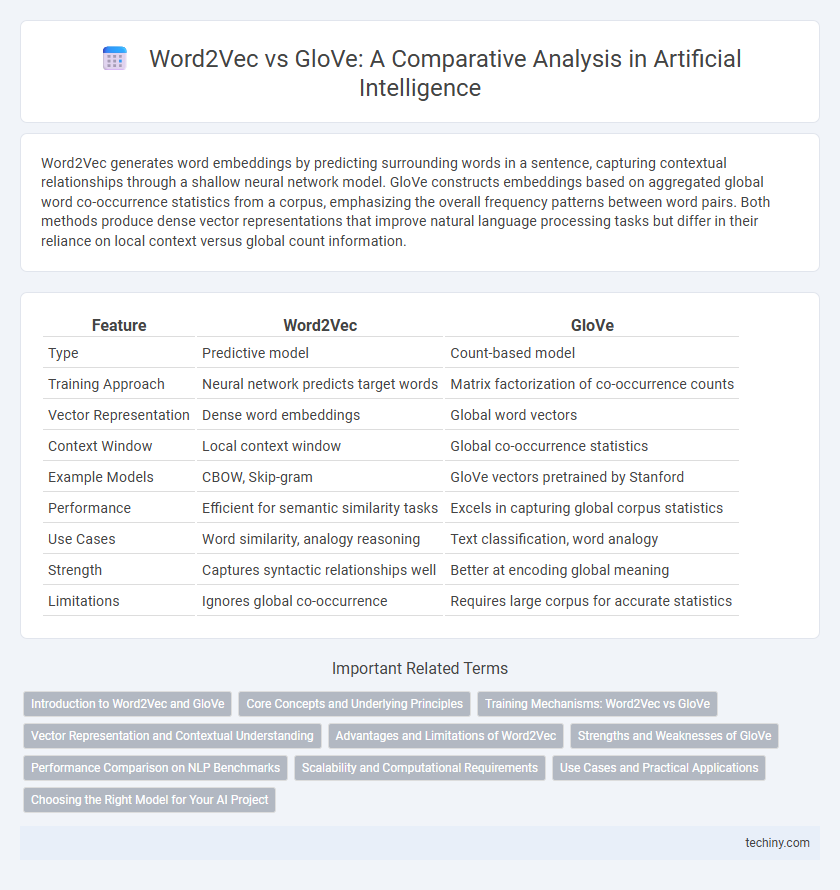
| Feature | Word2Vec | GloVe |
|---|---|---|
| Type | Predictive model | Count-based model |
| Training Approach | Neural network predicts target words | Matrix factorization of co-occurrence counts |
| Vector Representation | Dense word embeddings | Global word vectors |
| Context Window | Local context window | Global co-occurrence statistics |
| Example Models | CBOW, Skip-gram | GloVe vectors pretrained by Stanford |
| Performance | Efficient for semantic similarity tasks | Excels in capturing global corpus statistics |
| Use Cases | Word similarity, analogy reasoning | Text classification, word analogy |
| Strength | Captures syntactic relationships well | Better at encoding global meaning |
| Limitations | Ignores global co-occurrence | Requires large corpus for accurate statistics |
Introduction to Word2Vec and GloVe
Word2Vec is a predictive model that uses neural networks to learn word embeddings by analyzing the context in which words appear, capturing semantic relationships through continuous vector representations. GloVe, or Global Vectors for Word Representation, is a count-based model that constructs word embeddings by leveraging global word co-occurrence statistics in a corpus, emphasizing the overall context frequency. Both techniques generate dense vector spaces enabling improved natural language processing tasks such as word analogy, similarity, and classification.
Core Concepts and Underlying Principles
Word2Vec employs a predictive model using neural networks to learn word embeddings by predicting surrounding words in a context window, capturing semantic relationships through continuous bag-of-words (CBOW) or skip-gram architectures. GloVe, or Global Vectors, combines matrix factorization techniques on word co-occurrence statistics across an entire corpus, emphasizing the global statistical information of word pairs for vector representation. Both models create dense vector spaces but differ as Word2Vec focuses on local context prediction, while GloVe integrates global matrix factorization to encode semantic meaning.
Training Mechanisms: Word2Vec vs GloVe
Word2Vec employs a predictive training mechanism using neural networks to learn word embeddings by predicting surrounding words in a sentence, utilizing either the Continuous Bag of Words (CBOW) or Skip-Gram models. GloVe relies on a count-based approach, constructing a global co-occurrence matrix of the entire corpus and factorizing it to generate word vectors that capture statistical information about word co-occurrences. The differences in training emphasize Word2Vec's local context window optimization versus GloVe's global statistical matrix factorization, impacting the quality and characteristics of the generated word embeddings.
Vector Representation and Contextual Understanding
Word2Vec generates word embeddings by predicting neighboring words using local context windows, capturing semantic relationships through continuous bag-of-words and skip-gram models. GloVe leverages global word co-occurrence matrices to create vector representations that emphasize overall statistical information across entire corpora, enhancing the embedding's ability to reflect global semantics. While Word2Vec excels in modeling local syntactic dependencies, GloVe provides richer contextual understanding by integrating both local and global word occurrence patterns.
Advantages and Limitations of Word2Vec
Word2Vec excels in capturing semantic relationships between words through efficient shallow neural networks, enabling accurate word embeddings that reflect contextual similarities. Its limitation lies in difficulty handling rare words and global corpus statistics, which can reduce embedding quality for infrequent terms. Despite these constraints, Word2Vec remains computationally efficient and effective for many natural language processing tasks.
Strengths and Weaknesses of GloVe
GloVe excels in capturing global co-occurrence statistics by constructing a word-word co-occurrence matrix, enabling it to produce high-quality vector representations that reflect global semantic relationships better than Word2Vec's local context-based approach. Its matrix factorization method efficiently encodes corpus-wide information, leading to robust performance on word analogy and similarity tasks. However, GloVe demands significant memory and computational resources for large vocabularies, which can limit scalability compared to Word2Vec's more lightweight and faster skip-gram or CBOW models.
Performance Comparison on NLP Benchmarks
Word2Vec and GloVe are widely used word embedding models evaluated on NLP benchmarks such as sentiment analysis, named entity recognition, and analogy tasks. Word2Vec excels in capturing local context with higher accuracy on analogy completion tests, while GloVe demonstrates superior performance in semantic similarity and global co-occurrence tasks due to its matrix factorization approach. Benchmark comparisons reveal GloVe's embeddings often achieve better results on large corpora involving global statistical information, whereas Word2Vec performs well in tasks relying on local context window information.
Scalability and Computational Requirements
Word2Vec employs a predictive model that scales efficiently with large datasets using shallow neural networks, resulting in faster training times and lower memory consumption. GloVe, based on matrix factorization of word co-occurrence counts, requires more memory and computational power due to the construction and factorization of large co-occurrence matrices. For applications demanding scalability and quicker training on massive corpora, Word2Vec often outperforms GloVe in computational efficiency.
Use Cases and Practical Applications
Word2Vec excels in capturing contextual relationships between words, making it ideal for natural language processing tasks such as sentiment analysis, machine translation, and recommendation systems. GloVe, leveraging global co-occurrence statistics, performs better in identifying word analogies and semantic similarities, benefiting tasks like information retrieval and document clustering. Both embeddings enhance feature representation in AI models, with Word2Vec preferred for dynamic, contextual applications, while GloVe suits use cases requiring a robust understanding of global word associations.
Choosing the Right Model for Your AI Project
Word2Vec excels in capturing local context through predictive modeling, making it ideal for projects requiring nuanced semantic relationships within smaller datasets. GloVe leverages global co-occurrence statistics, which enhances performance in tasks needing comprehensive word embedding representations from large corpora. Selecting the right model depends on dataset size, project scope, and the specific semantic features critical to your AI application.
Word2Vec vs GloVe Infographic