Data ingestion involves collecting and importing raw data from various sources into a storage system, while data integration focuses on combining and transforming this raw data into a unified, meaningful dataset for analysis. Ingestion handles the initial data flow, ensuring timely and scalable capture, whereas integration addresses data quality, consistency, and usability across multiple systems. Effective Big Data management requires balancing both processes to enable seamless data analytics and decision-making.
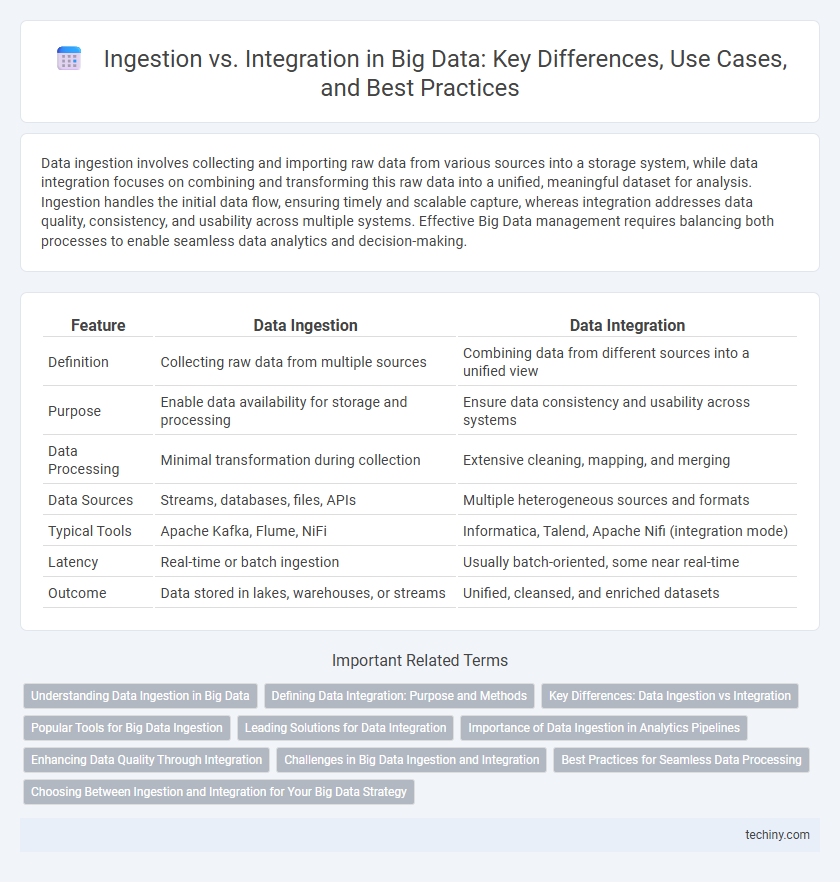
Table of Comparison
| Feature | Data Ingestion | Data Integration |
|---|---|---|
| Definition | Collecting raw data from multiple sources | Combining data from different sources into a unified view |
| Purpose | Enable data availability for storage and processing | Ensure data consistency and usability across systems |
| Data Processing | Minimal transformation during collection | Extensive cleaning, mapping, and merging |
| Data Sources | Streams, databases, files, APIs | Multiple heterogeneous sources and formats |
| Typical Tools | Apache Kafka, Flume, NiFi | Informatica, Talend, Apache Nifi (integration mode) |
| Latency | Real-time or batch ingestion | Usually batch-oriented, some near real-time |
| Outcome | Data stored in lakes, warehouses, or streams | Unified, cleansed, and enriched datasets |
Understanding Data Ingestion in Big Data
Data ingestion in Big Data refers to the process of collecting and importing raw data from various sources into a storage system for immediate or subsequent processing. It focuses on capturing diverse formats and large volumes of data in real-time or batch modes, enabling rapid availability for analysis. Efficient data ingestion ensures scalability and supports downstream integration by preparing data for transformation and consolidation across multiple systems.
Defining Data Integration: Purpose and Methods
Data integration involves combining data from multiple sources to provide a unified view for analysis and decision-making. Its purpose is to ensure data consistency, accuracy, and accessibility across diverse systems through methods like ETL (Extract, Transform, Load), ELT, and data virtualization. Effective data integration supports complex analytics by harmonizing structured and unstructured data within big data environments.
Key Differences: Data Ingestion vs Integration
Data ingestion involves the process of collecting and importing raw data from diverse sources into a storage system for immediate use or processing. Data integration combines and transforms disparate data sets into a unified, coherent format to enable better analysis, reporting, and business intelligence. Unlike ingestion, integration emphasizes data cleansing, harmonization, and consistency to create a single source of truth across platforms.
Popular Tools for Big Data Ingestion
Popular tools for Big Data ingestion include Apache Kafka, Apache Flume, and Amazon Kinesis, which enable efficient real-time data streaming from diverse sources. These ingestion tools are designed to handle large volumes of structured and unstructured data, ensuring high throughput and low latency. Unlike integration tools that focus on combining data from multiple systems for analysis, ingestion tools primarily capture and transport raw data into storage or processing frameworks.
Leading Solutions for Data Integration
Leading solutions for data integration in Big Data environments include platforms like Apache Nifi, Talend, and Informatica PowerCenter, which excel at transforming and consolidating diverse datasets from multiple sources. These tools provide scalable, automated workflows that enable seamless integration of structured and unstructured data, optimizing data quality and consistency. Implementing these integration solutions enhances analytics capabilities by delivering unified, real-time data ready for processing and analysis.
Importance of Data Ingestion in Analytics Pipelines
Data ingestion is critical in analytics pipelines as it ensures the efficient collection of raw data from diverse sources, enabling real-time processing and immediate analysis. Effective ingestion mechanisms support scalability and data variety, which are essential for generating accurate insights and driving business decisions. Without robust data ingestion, integration efforts may face delays and data quality issues, hindering the overall performance of big data analytics.
Enhancing Data Quality Through Integration
Enhancing data quality through integration involves consolidating diverse data sources into a unified, consistent format that reduces redundancies and errors, improving reliability for analytics. Integration processes apply cleansing, transformation, and validation techniques that ensure accurate, timely, and complete data is accessible across enterprise systems. Unlike ingestion, which primarily focuses on collecting raw data, integration emphasizes harmonizing and enriching data to optimize its usability and trustworthiness in big data environments.
Challenges in Big Data Ingestion and Integration
Big Data ingestion faces challenges such as handling diverse data formats, high velocity streams, and ensuring data quality during real-time acquisition. Integration struggles with unifying structured, semi-structured, and unstructured data from disparate sources while maintaining consistency and scalability across large volumes. Both processes require robust frameworks to address data heterogeneity, latency issues, and evolving schema variations.
Best Practices for Seamless Data Processing
Effective big data management relies on distinguishing ingestion from integration to streamline workflows and enhance data quality. Best practices for seamless data processing include automating data ingestion pipelines to capture diverse sources in real-time, followed by robust integration techniques that harmonize, cleanse, and enrich datasets within a unified platform. Emphasizing metadata management and scalable architecture ensures consistent data lineage and supports advanced analytics across heterogeneous big data environments.
Choosing Between Ingestion and Integration for Your Big Data Strategy
Choosing between ingestion and integration in your Big Data strategy depends on your data sources and processing needs. Ingestion focuses on rapidly collecting and storing raw data from various sources, ensuring scalability and real-time access. Integration combines and transforms diverse data sets into a unified format, enabling comprehensive analysis and improved data quality for business intelligence.
Ingestion vs Integration Infographic