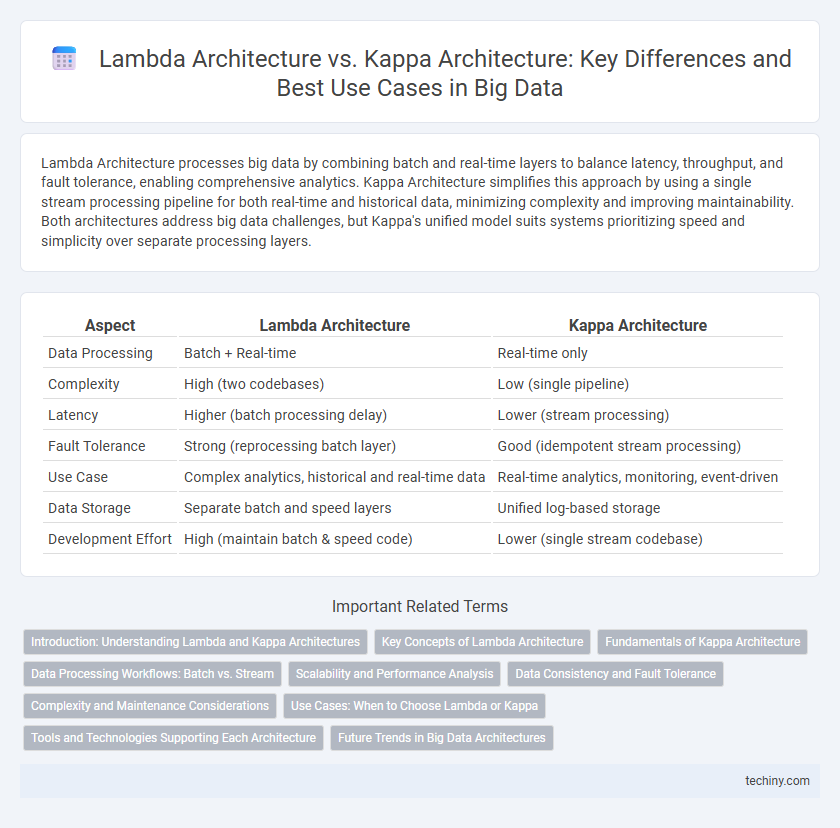
Lambda Architecture processes big data by combining batch and real-time layers to balance latency, throughput, and fault tolerance, enabling comprehensive analytics. Kappa Architecture simplifies this approach by using a single stream processing pipeline for both real-time and historical data, minimizing complexity and improving maintainability. Both architectures address big data challenges, but Kappa's unified model suits systems prioritizing speed and simplicity over separate processing layers.
Table of Comparison
| Aspect | Lambda Architecture | Kappa Architecture |
|---|---|---|
| Data Processing | Batch + Real-time | Real-time only |
| Complexity | High (two codebases) | Low (single pipeline) |
| Latency | Higher (batch processing delay) | Lower (stream processing) |
| Fault Tolerance | Strong (reprocessing batch layer) | Good (idempotent stream processing) |
| Use Case | Complex analytics, historical and real-time data | Real-time analytics, monitoring, event-driven |
| Data Storage | Separate batch and speed layers | Unified log-based storage |
| Development Effort | High (maintain batch & speed code) | Lower (single stream codebase) |
Introduction: Understanding Lambda and Kappa Architectures
Lambda Architecture integrates batch and real-time processing to handle massive data volumes with fault tolerance and scalability, using separate layers for speed and accuracy. Kappa Architecture simplifies data pipelines by processing real-time streams exclusively, reducing complexity and operational overhead for continuous data integration. Both architectures aim to optimize big data workflows, with Lambda emphasizing robustness and Kappa focusing on simplicity.
Key Concepts of Lambda Architecture
Lambda Architecture integrates batch and real-time processing to handle massive data volumes by combining a batch layer, speed layer, and serving layer. The batch layer processes historical data using distributed computing frameworks like Hadoop, providing comprehensive and accurate results. The speed layer manages real-time data streams with low-latency tools such as Apache Storm, ensuring timely updates for immediate insights.
Fundamentals of Kappa Architecture
Kappa Architecture streamlines big data processing by using a single real-time processing layer, eliminating the need for separate batch and speed layers found in Lambda Architecture. It processes data as a continuous stream, enabling simpler codebases and easier maintenance while leveraging distributed log storage systems like Apache Kafka for fault tolerance and scalability. This architecture enhances real-time analytics and reduces complexity by avoiding redundant data processing paths typical in Lambda's dual-layer design.
Data Processing Workflows: Batch vs. Stream
Lambda Architecture uses a dual processing workflow, combining batch processing for comprehensive historical data analysis and real-time streaming for immediate insights, ensuring data accuracy and fault tolerance. Kappa Architecture simplifies the workflow by relying solely on stream processing, continuously ingesting and processing data in real time, which reduces system complexity and latency. Batch processing in Lambda allows reprocessing of large data volumes, while Kappa's unified streaming pipeline offers faster updates but requires reliable fault handling to maintain data consistency.
Scalability and Performance Analysis
Lambda Architecture combines batch and stream processing to enhance scalability by handling large data volumes through distributed systems like Hadoop and Spark, enabling fault-tolerant and low-latency analytics. Kappa Architecture simplifies the pipeline by processing all data as a real-time stream, leveraging platforms such as Apache Kafka and Apache Flink, which improves system performance by reducing complexity and minimizing data duplication. Performance analysis reveals Kappa's streamlined approach leads to faster data processing and easier scalability, while Lambda excels in scenarios requiring complex batch computations alongside real-time insights.
Data Consistency and Fault Tolerance
Lambda Architecture separates batch and real-time processing layers, ensuring strong data consistency through immutable batch views but introduces complexity in fault tolerance across layers. Kappa Architecture simplifies processing with a single streaming pipeline, enhancing fault tolerance by reprocessing events from the immutable log to recover from failures while maintaining eventual consistency. Both architectures use immutable data stores like Apache Kafka, but Lambda favors immediate accuracy, whereas Kappa emphasizes simplified recovery and consistency trade-offs.
Complexity and Maintenance Considerations
Lambda Architecture divides data processing into separate batch and real-time layers, increasing system complexity and requiring maintenance of multiple codebases and infrastructure components. Kappa Architecture simplifies maintenance by unifying stream processing into a single pipeline, reducing the overhead associated with synchronizing batch and real-time layers. Organizations adopting Kappa gain faster development cycles and easier scalability, while Lambda supports complex analytics with historically richer data integration but at a higher operational cost.
Use Cases: When to Choose Lambda or Kappa
Lambda Architecture suits scenarios requiring robust batch and real-time processing, such as fraud detection systems combining historical data with live transactions for accuracy and speed. Kappa Architecture excels in streaming data pipelines needing simplified maintenance and real-time analytics, ideal for IoT sensor data where event ordering and continuous processing are crucial. Choosing Lambda depends on complex data integration needs and fault tolerance, while Kappa favors use cases emphasizing real-time processing efficiency and reduced system complexity.
Tools and Technologies Supporting Each Architecture
Lambda Architecture utilizes tools like Apache Hadoop for batch processing and Apache Storm or Apache Spark Streaming for real-time processing, enabling fault-tolerant and scalable data pipelines. Kappa Architecture relies primarily on stream processing frameworks such as Apache Kafka and Apache Flink, simplifying the architecture by treating all data as a continuous stream. Both architectures leverage NoSQL databases like Apache Cassandra or HBase for serving layer storage, supporting large-scale and low-latency data access.
Future Trends in Big Data Architectures
Lambda Architecture combines batch and real-time processing layers to handle massive data volumes, ensuring fault tolerance and scalability in complex environments. Kappa Architecture simplifies this by streamlining data processing into a single real-time pipeline, reducing maintenance overhead and latency. Emerging Big Data trends favor Kappa's unified model for its agility and efficiency in handling continuous data streams.
Lambda Architecture vs Kappa Architecture Infographic