Cross-validation and bootstrap are essential techniques in data science for model evaluation and reliability assessment. Cross-validation splits the dataset into multiple folds to train and test the model on different subsets, providing a robust estimate of model performance. In contrast, bootstrap resamples the data with replacement to generate numerous datasets, allowing estimation of the stability and variance of the model's predictions.
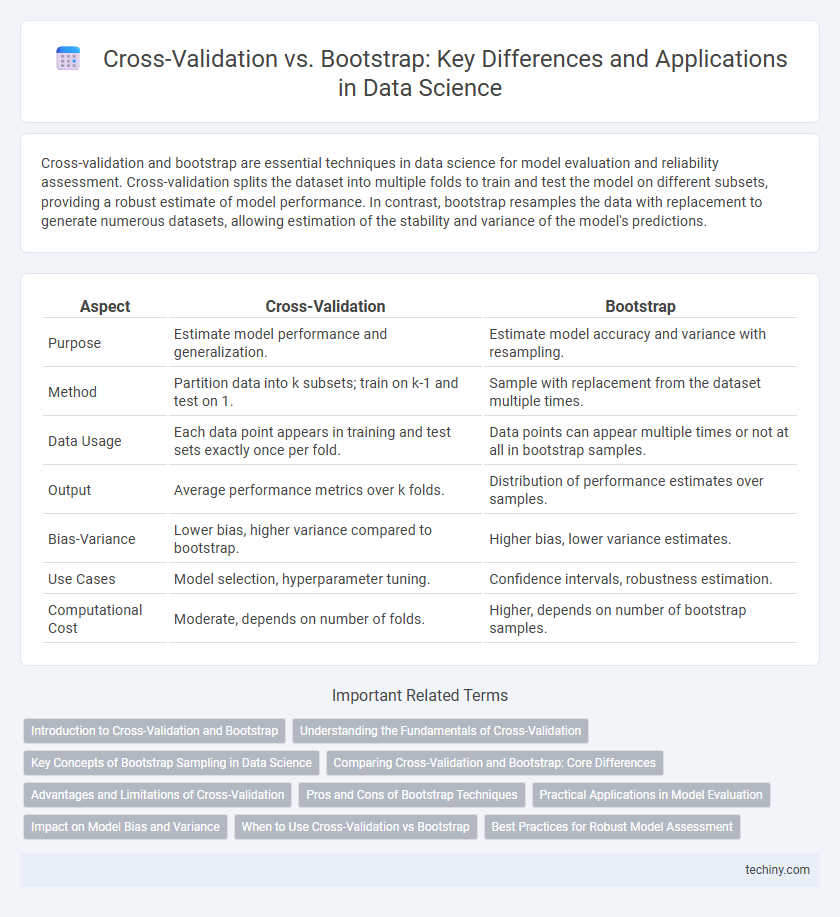
Table of Comparison
| Aspect | Cross-Validation | Bootstrap |
|---|---|---|
| Purpose | Estimate model performance and generalization. | Estimate model accuracy and variance with resampling. |
| Method | Partition data into k subsets; train on k-1 and test on 1. | Sample with replacement from the dataset multiple times. |
| Data Usage | Each data point appears in training and test sets exactly once per fold. | Data points can appear multiple times or not at all in bootstrap samples. |
| Output | Average performance metrics over k folds. | Distribution of performance estimates over samples. |
| Bias-Variance | Lower bias, higher variance compared to bootstrap. | Higher bias, lower variance estimates. |
| Use Cases | Model selection, hyperparameter tuning. | Confidence intervals, robustness estimation. |
| Computational Cost | Moderate, depends on number of folds. | Higher, depends on number of bootstrap samples. |
Introduction to Cross-Validation and Bootstrap
Cross-validation is a statistical method used to evaluate the performance of machine learning models by dividing data into training and testing subsets multiple times to ensure model robustness. Bootstrap involves repeatedly sampling with replacement from the original dataset to estimate the sampling distribution and assess model accuracy. Both techniques help in reducing overfitting and provide reliable model evaluation metrics in data science workflows.
Understanding the Fundamentals of Cross-Validation
Cross-validation is a robust resampling technique used in data science to evaluate the performance and generalizability of predictive models by partitioning data into multiple subsets, training on some folds, and validating on others. Unlike bootstrap methods, which rely on sampling with replacement to create multiple datasets, cross-validation emphasizes systematic data splitting to prevent overfitting and assess model stability across diverse partitions. This fundamental approach enhances model reliability by providing unbiased estimates of prediction error, crucial for optimizing algorithm parameters and ensuring consistent outcomes on unseen data.
Key Concepts of Bootstrap Sampling in Data Science
Bootstrap sampling in data science involves repeatedly drawing random samples with replacement from the original dataset to create multiple training sets, enabling robust estimation of model accuracy and variance. This resampling technique provides insight into the stability and reliability of predictive models by approximating the sampling distribution of an estimator. Unlike cross-validation, bootstrap sampling allows calculation of confidence intervals and bias estimates, making it essential for assessing model uncertainty and performance in small or imbalanced datasets.
Comparing Cross-Validation and Bootstrap: Core Differences
Cross-validation partitions the dataset into multiple folds to evaluate model performance on unseen data, ensuring robustness by averaging results across splits. Bootstrap sampling creates multiple datasets by random sampling with replacement, emphasizing variance estimation and model stability. Cross-validation tends to provide less biased error estimates, while bootstrap focuses on assessing prediction variability and bias correction.
Advantages and Limitations of Cross-Validation
Cross-validation offers a robust method for estimating model performance by systematically partitioning data into training and testing sets, enhancing the reliability of predictive accuracy assessments. Its advantage lies in reducing overfitting risk and providing a more generalized model evaluation compared to a single train-test split. However, cross-validation can be computationally intensive for large datasets and may introduce bias if data points are not independent or identically distributed.
Pros and Cons of Bootstrap Techniques
Bootstrap techniques in data science provide robust estimates of model performance by repeatedly sampling with replacement, which helps in assessing variability and confidence intervals. However, bootstrap can introduce bias because some samples may be overrepresented while others are excluded, potentially leading to less accurate generalization compared to cross-validation. Despite this, bootstrap methods excel in small datasets where traditional cross-validation might struggle due to limited data variability.
Practical Applications in Model Evaluation
Cross-validation, particularly k-fold, is extensively used in data science for robust model evaluation by partitioning data to assess generalization performance, minimizing overfitting risks. Bootstrap methods generate multiple resampled datasets to estimate model accuracy and variance, which is crucial for small or imbalanced datasets where traditional splits may be insufficient. Practical applications often combine cross-validation with bootstrap techniques to optimize hyperparameter tuning and provide confidence intervals for predictive performance metrics.
Impact on Model Bias and Variance
Cross-validation typically reduces model bias by averaging performance across multiple folds, providing a more reliable estimate of model accuracy, while its variance is often moderate due to repeated sampling of subsets. Bootstrap methods, by resampling with replacement, tend to lower variance by creating diverse training sets but can introduce higher bias as some data points may be overrepresented or omitted, affecting model generalization. Understanding these impacts helps data scientists select the optimal validation technique to balance bias-variance trade-offs for robust predictive modeling.
When to Use Cross-Validation vs Bootstrap
Cross-validation is ideal for evaluating model performance on small to medium datasets by partitioning data into training and testing subsets to reduce overfitting bias. Bootstrap is more suitable for estimating the sampling distribution and assessing model variance when the dataset is limited or when confidence intervals for predictions are required. Use cross-validation for model selection and hyperparameter tuning, while bootstrap excels in measuring estimator stability and uncertainty.
Best Practices for Robust Model Assessment
Cross-validation and bootstrap are essential techniques for robust model assessment in data science, each offering unique advantages for evaluating model performance. Cross-validation, particularly k-fold, provides reliable estimates by partitioning data into multiple training and validation sets, minimizing overfitting risks. The bootstrap method complements this by generating numerous resampled datasets to estimate model stability and variance, making the combined use of both techniques a best practice for comprehensive and robust model evaluation.
Cross-Validation vs Bootstrap Infographic