Hadoop offers a reliable framework for distributed storage and batch processing of large datasets, making it ideal for handling massive volumes of data over time. Spark provides faster in-memory computing capabilities and supports real-time data processing, which significantly accelerates machine learning and analytics workflows. Choosing between Hadoop and Spark depends on specific data processing needs, such as batch versus streaming tasks and cluster resource utilization.
Table of Comparison
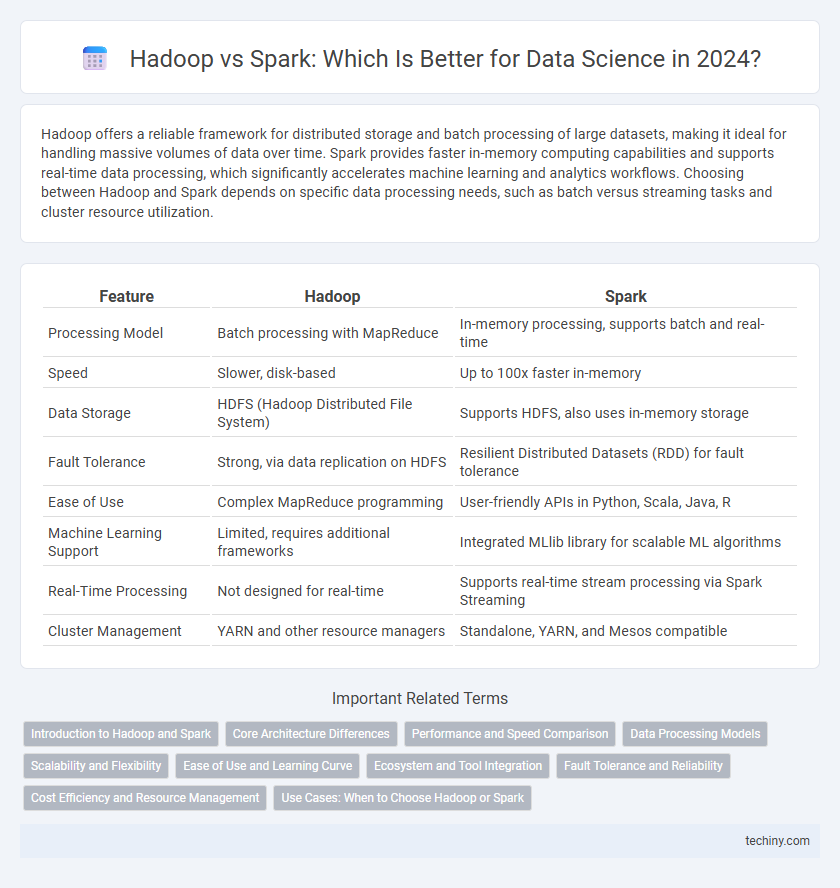
| Feature | Hadoop | Spark |
|---|---|---|
| Processing Model | Batch processing with MapReduce | In-memory processing, supports batch and real-time |
| Speed | Slower, disk-based | Up to 100x faster in-memory |
| Data Storage | HDFS (Hadoop Distributed File System) | Supports HDFS, also uses in-memory storage |
| Fault Tolerance | Strong, via data replication on HDFS | Resilient Distributed Datasets (RDD) for fault tolerance |
| Ease of Use | Complex MapReduce programming | User-friendly APIs in Python, Scala, Java, R |
| Machine Learning Support | Limited, requires additional frameworks | Integrated MLlib library for scalable ML algorithms |
| Real-Time Processing | Not designed for real-time | Supports real-time stream processing via Spark Streaming |
| Cluster Management | YARN and other resource managers | Standalone, YARN, and Mesos compatible |
Introduction to Hadoop and Spark
Hadoop is an open-source framework designed for distributed storage and processing of large data sets using the MapReduce programming model across clusters of commodity hardware. Apache Spark provides an in-memory data processing engine that significantly accelerates big data analytics compared to traditional disk-based frameworks like Hadoop MapReduce. Both Hadoop and Spark support scalable data processing, but Spark's advanced DAG execution engine offers faster computation for iterative algorithms and real-time stream processing.
Core Architecture Differences
Hadoop relies on the Hadoop Distributed File System (HDFS) and MapReduce for batch processing, emphasizing disk-based storage and sequential data processing. Spark uses Resilient Distributed Datasets (RDDs) and in-memory computation, enabling faster data processing and real-time analytics. The core architecture difference lies in Hadoop's disk-dependent MapReduce framework versus Spark's memory-centric execution engine for improved performance and speed.
Performance and Speed Comparison
Apache Spark offers significantly faster processing speeds compared to Hadoop MapReduce, primarily due to its in-memory computation capabilities, which reduce disk I/O overhead. Hadoop's batch processing model suits large-scale, disk-based data processing but often lags in performance on iterative tasks when compared to Spark's optimized DAG execution engine. Benchmark studies show Spark can be up to 100 times faster in memory and 10 times faster on disk, making it the preferred choice for real-time analytics and complex data science workflows.
Data Processing Models
Hadoop utilizes the MapReduce data processing model, which processes data in batch mode by dividing tasks into map and reduce phases, suitable for large-scale, disk-based computations. In contrast, Apache Spark employs an in-memory data processing model, enabling faster computation through Resilient Distributed Datasets (RDDs) and iterative processing for real-time and interactive analytics. The Spark model significantly reduces latency compared to Hadoop MapReduce by minimizing disk I/O and optimizing data reuse across multiple stages.
Scalability and Flexibility
Hadoop offers robust scalability through its distributed file system (HDFS) that efficiently stores and processes vast datasets by distributing data across multiple nodes. Spark enhances scalability by leveraging in-memory processing, enabling faster data analysis and real-time computing across large clusters. Flexibility in Spark surpasses Hadoop by supporting diverse workloads such as batch processing, streaming, machine learning, and graph computations within a unified framework.
Ease of Use and Learning Curve
Hadoop requires users to master complex MapReduce programming, making its learning curve steep and less accessible for beginners. Spark offers a more user-friendly API with support for multiple languages like Python, Scala, and Java, significantly reducing development effort and accelerating learning. Developers can leverage Spark's interactive shell and extensive documentation to quickly prototype and test large-scale data processing tasks.
Ecosystem and Tool Integration
Hadoop's ecosystem centers around HDFS, MapReduce, and tools like Hive and Pig, providing robust batch processing and dependable storage solutions. Spark offers a more versatile ecosystem with Spark SQL, MLlib, and GraphX, enabling faster in-memory processing and real-time analytics. Integration capabilities favor Spark due to its compatibility with Hadoop components and seamless support for diverse data sources and processing frameworks.
Fault Tolerance and Reliability
Hadoop ensures fault tolerance through data replication across nodes in its HDFS, allowing recovery from hardware failures without data loss. Spark achieves fault tolerance using lineage information to recompute lost data partitions, enabling faster recovery during failures. Both frameworks provide high reliability, with Hadoop excelling in data durability and Spark offering rapid fault recovery for in-memory processing tasks.
Cost Efficiency and Resource Management
Hadoop's batch processing framework offers cost efficiency through its ability to run on low-cost commodity hardware, effectively managing large-scale data storage with HDFS. Spark, optimized for in-memory processing, provides faster data throughput and better resource utilization, reducing compute time and associated costs for iterative algorithms. Both platforms excel in resource management, but Spark's dynamic allocation and DAG execution often result in lower operational expenses for real-time analytics workloads.
Use Cases: When to Choose Hadoop or Spark
Hadoop excels in batch processing of large-scale datasets and is ideal for data warehousing, log analysis, and scenarios requiring fault tolerance and scalability across distributed storage. Spark is preferred for real-time analytics, iterative machine learning, and streaming data applications due to its in-memory processing capabilities and faster computation speed. Organizations should choose Hadoop for long-duration batch jobs with massive data volumes and Spark for time-sensitive or iterative analytics tasks requiring rapid data processing.
Hadoop vs Spark Infographic