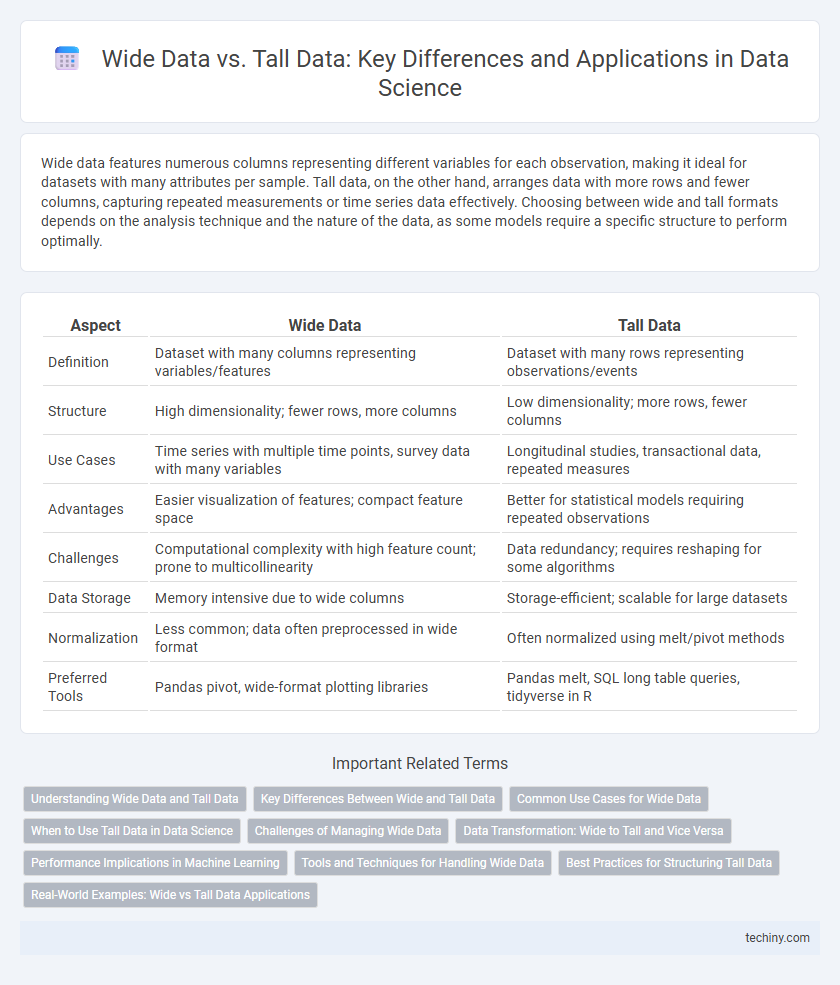
Wide data features numerous columns representing different variables for each observation, making it ideal for datasets with many attributes per sample. Tall data, on the other hand, arranges data with more rows and fewer columns, capturing repeated measurements or time series data effectively. Choosing between wide and tall formats depends on the analysis technique and the nature of the data, as some models require a specific structure to perform optimally.
Table of Comparison
| Aspect | Wide Data | Tall Data |
|---|---|---|
| Definition | Dataset with many columns representing variables/features | Dataset with many rows representing observations/events |
| Structure | High dimensionality; fewer rows, more columns | Low dimensionality; more rows, fewer columns |
| Use Cases | Time series with multiple time points, survey data with many variables | Longitudinal studies, transactional data, repeated measures |
| Advantages | Easier visualization of features; compact feature space | Better for statistical models requiring repeated observations |
| Challenges | Computational complexity with high feature count; prone to multicollinearity | Data redundancy; requires reshaping for some algorithms |
| Data Storage | Memory intensive due to wide columns | Storage-efficient; scalable for large datasets |
| Normalization | Less common; data often preprocessed in wide format | Often normalized using melt/pivot methods |
| Preferred Tools | Pandas pivot, wide-format plotting libraries | Pandas melt, SQL long table queries, tidyverse in R |
Understanding Wide Data and Tall Data
Wide data features many columns representing variables for each observation, making it ideal for datasets where a fixed number of attributes describe each subject. Tall data, characterized by numerous rows and fewer columns, organizes repeated measurements or time series data efficiently by stacking records vertically. Understanding the structure of wide versus tall data is critical for selecting appropriate data processing techniques and optimizing machine learning model performance.
Key Differences Between Wide and Tall Data
Wide data features many columns representing variables for fewer observations, while tall data has fewer columns but a larger number of rows. Wide datasets facilitate easier comparison among variables but can lead to computational challenges with high dimensionality. Tall data improves model training efficiency and scalability, particularly for time-series or panel data analysis, due to its normalized structure.
Common Use Cases for Wide Data
Wide data is commonly used in scenarios where each subject or entity is described by many variables, such as in genomics, where multiple gene expressions are recorded for single samples. It is ideal for machine learning models requiring a broad feature set to capture complex relationships across numerous predictors. Wide data structures also facilitate feature selection and multivariate analysis in marketing analytics, enabling better customer segmentation and targeted campaigns.
When to Use Tall Data in Data Science
Tall data is preferred in data science when dealing with datasets that require efficient handling of repeated measures or longitudinal data, enabling easier modeling of time series or panel data. It facilitates the use of mixed-effects models and time-dependent covariates by structuring data with multiple rows per subject or entity. Opt for tall data when simplifying data transformation and analysis for complex hierarchical or nested relationships.
Challenges of Managing Wide Data
Wide data poses significant challenges in data management due to its high dimensionality, leading to increased computational complexity and storage requirements. Handling numerous variables simultaneously can cause multicollinearity issues, complicating statistical analysis and model performance. Efficient feature selection and dimensionality reduction techniques are essential to mitigate these challenges and extract meaningful insights from wide datasets.
Data Transformation: Wide to Tall and Vice Versa
Transforming wide data to tall data involves reshaping datasets with many columns (features) into a longer format with fewer columns and more rows, enabling easier time-series analysis and visualization. Conversely, converting tall data back to wide format aggregates multiple observations per entity into a single row with multiple columns, facilitating models that require fixed feature sets. Efficient use of tools like pandas' melt and pivot functions in Python streamlines these transformations, enhancing data preprocessing workflows in data science projects.
Performance Implications in Machine Learning
Wide data, characterized by a high number of features relative to samples, often leads to increased computational complexity and heightened risk of overfitting in machine learning models. Tall data, with more samples than features, generally improves model generalization and reduces variance but may require more memory and processing time during training. Optimizing performance involves selecting appropriate algorithms and dimensionality reduction techniques to balance bias-variance trade-offs and computational efficiency.
Tools and Techniques for Handling Wide Data
Wide data often requires specialized tools like Apache Spark and Dask to efficiently manage and process high-dimensional datasets. Techniques such as feature selection, dimensionality reduction using PCA, and sparse matrix representation help mitigate the computational challenges associated with wide data. Efficient memory management and parallel processing frameworks are critical for handling the complexity and scale of wide data in machine learning pipelines.
Best Practices for Structuring Tall Data
Tall data structures excel in scenarios requiring efficient data manipulation and scalability, where each row represents a single observation with multiple records per subject, optimizing performance for time-series and repeated-measures analysis. Best practices for structuring tall data include maintaining consistent variable names across rows, ensuring a clear identifier column for subjects or entities, and using separate columns for measurement types and values to facilitate flexibility in data aggregation and transformation. Leveraging tools like pandas in Python or tidyr in R enhances data cleaning and reshaping processes, supporting reproducible workflows in large-scale data science projects.
Real-World Examples: Wide vs Tall Data Applications
Wide data structures are commonly used in genomics, where each column represents a specific gene or variant, allowing efficient comparison across many genetic markers for individual samples. Tall data formats dominate sensor data analytics, such as time-series IoT data, where each row records a single sensor reading with timestamp and sensor ID, facilitating scalable aggregation and time-based analysis. E-commerce platforms often use wide data to capture multiple customer attributes per record, while tall data formats enable detailed purchase transaction logs for intricate behavioral trend analysis.
Wide Data vs Tall Data Infographic