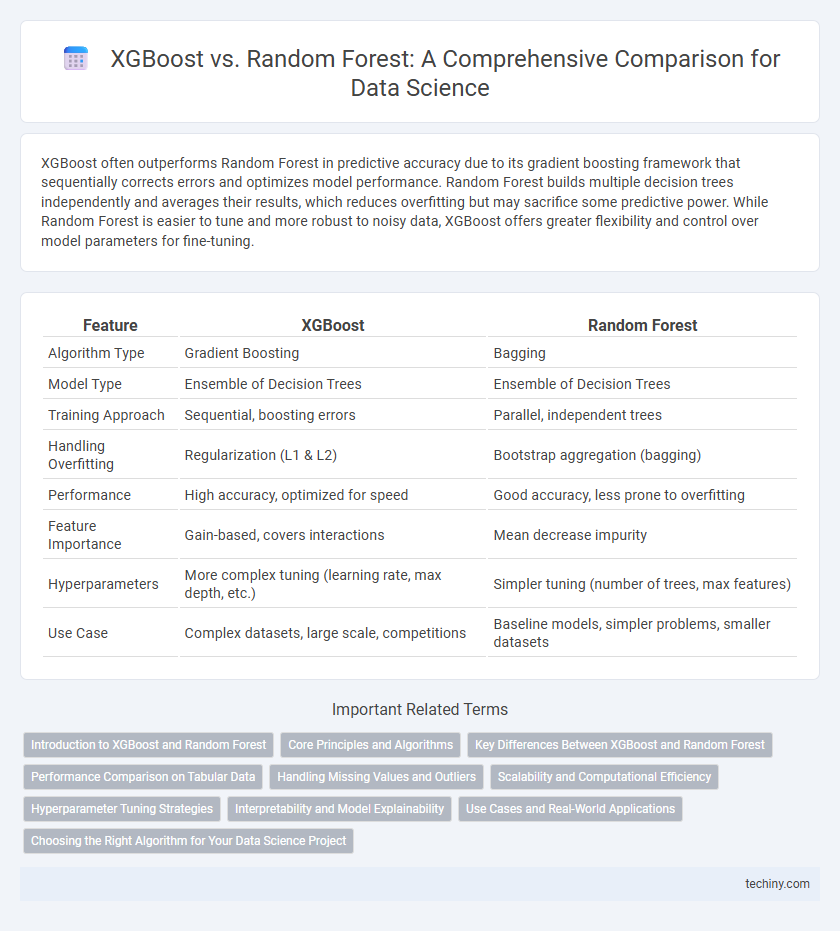
XGBoost often outperforms Random Forest in predictive accuracy due to its gradient boosting framework that sequentially corrects errors and optimizes model performance. Random Forest builds multiple decision trees independently and averages their results, which reduces overfitting but may sacrifice some predictive power. While Random Forest is easier to tune and more robust to noisy data, XGBoost offers greater flexibility and control over model parameters for fine-tuning.
Table of Comparison
| Feature | XGBoost | Random Forest |
|---|---|---|
| Algorithm Type | Gradient Boosting | Bagging |
| Model Type | Ensemble of Decision Trees | Ensemble of Decision Trees |
| Training Approach | Sequential, boosting errors | Parallel, independent trees |
| Handling Overfitting | Regularization (L1 & L2) | Bootstrap aggregation (bagging) |
| Performance | High accuracy, optimized for speed | Good accuracy, less prone to overfitting |
| Feature Importance | Gain-based, covers interactions | Mean decrease impurity |
| Hyperparameters | More complex tuning (learning rate, max depth, etc.) | Simpler tuning (number of trees, max features) |
| Use Case | Complex datasets, large scale, competitions | Baseline models, simpler problems, smaller datasets |
Introduction to XGBoost and Random Forest
XGBoost is a scalable, tree-based gradient boosting algorithm optimized for speed and performance in predictive modeling tasks within data science. Random Forest, an ensemble method using multiple decision trees, enhances classification and regression accuracy by aggregating diverse model predictions through bagging and feature randomness. Both algorithms are pivotal in handling large datasets, with XGBoost excelling in handling sparse data and complex patterns, while Random Forest is valued for its robustness and ease of use.
Core Principles and Algorithms
XGBoost employs gradient boosting, sequentially building trees to minimize a specified loss function through additive model optimization, enhancing predictive accuracy by correcting previous errors. Random Forest uses bagging by constructing multiple independent decision trees from random data subsets and features, aggregating their outputs to reduce variance and prevent overfitting. Both algorithms leverage tree-based models but differ in their approach: XGBoost focuses on boosting with weighted trees and gradient descent, while Random Forest emphasizes parallel tree construction and majority voting or averaging.
Key Differences Between XGBoost and Random Forest
XGBoost leverages gradient boosting to sequentially optimize model performance by minimizing errors, while Random Forest builds multiple independent decision trees using bagging to reduce variance. XGBoost incorporates regularization techniques to prevent overfitting and supports parallel processing for faster computation, contrasting with Random Forest's focus on randomness in feature selection and tree construction. Feature importance interpretation varies as XGBoost provides weighted gain metrics, whereas Random Forest uses mean decrease in impurity or accuracy-based measures.
Performance Comparison on Tabular Data
XGBoost consistently outperforms Random Forest in tabular data tasks due to its gradient boosting framework, which optimizes for prediction accuracy and reduces overfitting through regularization techniques. While Random Forest builds multiple decision trees independently and averages their predictions, XGBoost builds trees sequentially, correcting errors of prior trees, leading to enhanced model precision and faster convergence. Benchmark studies show XGBoost achieves higher AUC-ROC scores and lower root mean squared error (RMSE) on structured datasets, making it preferable for complex predictive modeling in data science.
Handling Missing Values and Outliers
XGBoost incorporates a built-in method to handle missing values by learning the best direction for missing data during training, making it highly resilient to incomplete datasets. Random Forest, however, typically requires preprocessing techniques such as imputation to address missing values since it does not inherently manage them. When it comes to outliers, both algorithms demonstrate robustness, but XGBoost's gradient boosting framework often provides more nuanced handling by minimizing loss functions iteratively, while Random Forest reduces sensitivity by averaging multiple decision trees to mitigate outlier effects.
Scalability and Computational Efficiency
XGBoost demonstrates superior scalability and computational efficiency compared to Random Forest due to its gradient boosting framework and optimized parallel processing capabilities. It utilizes a novel tree learning algorithm that handles sparse data and supports out-of-core computation, making it suitable for large-scale datasets. Random Forest, while robust, often requires more memory and computation time since it builds multiple full decision trees independently without leveraging gradient-based optimization.
Hyperparameter Tuning Strategies
XGBoost hyperparameter tuning involves optimizing parameters like learning rate, max depth, and subsample ratio to enhance gradient boosting model performance, often using grid search or Bayesian optimization for efficiency. Random Forest tuning focuses on parameters such as the number of trees, max features, and minimum samples split, with methods like randomized search to balance bias-variance trade-offs. Effective hyperparameter tuning for both models significantly improves prediction accuracy and prevents overfitting in diverse data science applications.
Interpretability and Model Explainability
XGBoost offers detailed feature importance metrics and SHAP values for enhanced interpretability compared to Random Forest, which provides simpler, aggregated feature importance scores. While Random Forest's ensemble of decision trees is easier to visualize and understand, XGBoost's gradient boosting framework delivers more granular insights into feature interactions and model predictions. Model explainability in XGBoost is strengthened by its ability to capture complex patterns, making it preferable for applications requiring both high performance and interpretability.
Use Cases and Real-World Applications
XGBoost excels in handling large-scale structured data and is widely used in competitions like Kaggle for tasks such as fraud detection and click-through rate prediction due to its superior accuracy and speed. Random Forest is preferred for interpretability and robustness, making it suitable for healthcare diagnostics, customer segmentation, and environmental modeling where insights are crucial. Both algorithms are versatile, but XGBoost often outperforms in high-dimensional data while Random Forest provides stability with noisy or smaller datasets.
Choosing the Right Algorithm for Your Data Science Project
XGBoost offers superior performance with structured data and handles missing values effectively, making it ideal for complex datasets with high dimensionality. Random Forest excels in robustness and interpretability, providing reliable predictions with less tuning and resistance to overfitting on smaller or noisy datasets. Selecting between XGBoost and Random Forest depends on dataset characteristics, computational resources, and the specific problem requirements in your data science project.
XGBoost vs Random Forest Infographic