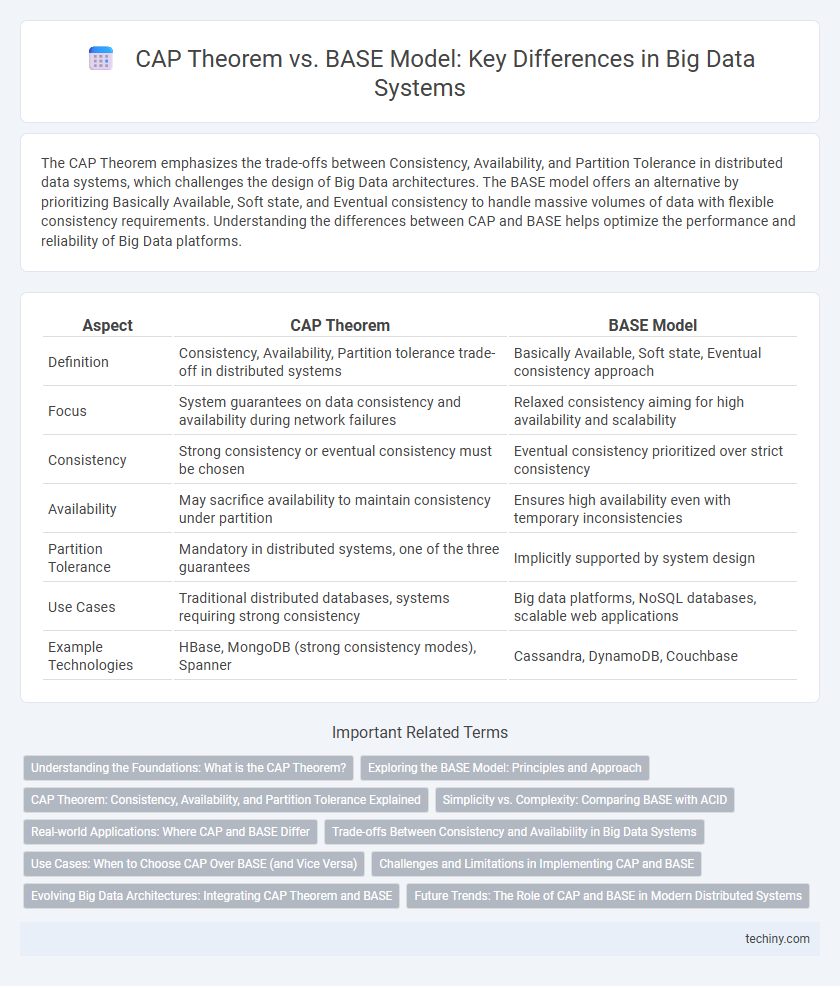
The CAP Theorem emphasizes the trade-offs between Consistency, Availability, and Partition Tolerance in distributed data systems, which challenges the design of Big Data architectures. The BASE model offers an alternative by prioritizing Basically Available, Soft state, and Eventual consistency to handle massive volumes of data with flexible consistency requirements. Understanding the differences between CAP and BASE helps optimize the performance and reliability of Big Data platforms.
Table of Comparison
| Aspect | CAP Theorem | BASE Model |
|---|---|---|
| Definition | Consistency, Availability, Partition tolerance trade-off in distributed systems | Basically Available, Soft state, Eventual consistency approach |
| Focus | System guarantees on data consistency and availability during network failures | Relaxed consistency aiming for high availability and scalability |
| Consistency | Strong consistency or eventual consistency must be chosen | Eventual consistency prioritized over strict consistency |
| Availability | May sacrifice availability to maintain consistency under partition | Ensures high availability even with temporary inconsistencies |
| Partition Tolerance | Mandatory in distributed systems, one of the three guarantees | Implicitly supported by system design |
| Use Cases | Traditional distributed databases, systems requiring strong consistency | Big data platforms, NoSQL databases, scalable web applications |
| Example Technologies | HBase, MongoDB (strong consistency modes), Spanner | Cassandra, DynamoDB, Couchbase |
Understanding the Foundations: What is the CAP Theorem?
The CAP Theorem, formulated by Eric Brewer, states that a distributed data system can only simultaneously guarantee two out of three properties: Consistency, Availability, and Partition Tolerance. This theorem is foundational in understanding the limitations and trade-offs in distributed databases when handling Big Data across multiple nodes. Selecting between these guarantees impacts system design, influencing how data is managed under network failures and ensuring reliable performance at scale.
Exploring the BASE Model: Principles and Approach
The BASE model in Big Data systems prioritizes availability and eventual consistency over strict consistency, contrasting the CAP Theorem's emphasis on consistency, availability, and partition tolerance. BASE stands for Basically Available, Soft state, and Eventual consistency, allowing flexible data handling in distributed environments with high fault tolerance and scalability. By relaxing consistency requirements, the BASE approach enables improved performance and resilience in large-scale, distributed databases commonly used in Big Data applications.
CAP Theorem: Consistency, Availability, and Partition Tolerance Explained
The CAP Theorem defines three critical guarantees in distributed systems: Consistency ensures every read receives the most recent write, Availability guarantees every request receives a response without failure, and Partition Tolerance maintains system operations despite network splits or failures. In Big Data architectures, achieving all three simultaneously is impossible, requiring trade-offs based on specific application needs. Prioritizing Partition Tolerance is essential in large-scale distributed databases, while balancing Consistency and Availability depends on data criticality and latency requirements.
Simplicity vs. Complexity: Comparing BASE with ACID
BASE model prioritizes eventual consistency and high availability, embracing system simplicity by allowing more flexible data states compared to the strict consistency guarantees of ACID properties in CAP Theorem. While ACID enforces atomicity, consistency, isolation, and durability ensuring complex transaction integrity, BASE accepts temporary inconsistency for improved scalability and fault tolerance. This trade-off highlights the complexity of ACID systems versus the more adaptable and simpler approach inherent in BASE for distributed big data environments.
Real-world Applications: Where CAP and BASE Differ
CAP Theorem emphasizes consistency, availability, and partition tolerance trade-offs in distributed systems, crucial for applications like banking where data accuracy is paramount. BASE model favors eventual consistency, high availability, and soft-state design, ideal for systems such as social media platforms that handle massive, loosely consistent data loads. Real-world applications choose CAP for strict, real-time data integrity, while BASE suits scalable, flexible environments demanding eventual consistency.
Trade-offs Between Consistency and Availability in Big Data Systems
The CAP Theorem establishes a fundamental trade-off in Big Data systems, asserting that out of Consistency, Availability, and Partition Tolerance, only two can be guaranteed simultaneously during network failures. The BASE (Basically Available, Soft state, Eventual consistency) model offers a practical approach to address these trade-offs by relaxing consistency requirements to improve availability and partition tolerance. In distributed databases like Cassandra and DynamoDB, the BASE model enables systems to achieve high availability and fault tolerance at the expense of immediate consistency, aligning with CAP's principles in real-world Big Data environments.
Use Cases: When to Choose CAP Over BASE (and Vice Versa)
CAP Theorem suits systems requiring strong consistency and partition tolerance, such as banking transactions or real-time analytics, where data accuracy is critical despite network failures. BASE Model fits applications like social media feeds or e-commerce recommendations, prioritizing high availability and eventual consistency for user experience under heavy load. Choosing CAP over BASE hinges on the need for immediate accuracy, while BASE is ideal for scalable, fault-tolerant systems with relaxed consistency demands.
Challenges and Limitations in Implementing CAP and BASE
Implementing the CAP Theorem in distributed systems faces challenges such as balancing consistency, availability, and partition tolerance, where achieving two often compromises the third. BASE model limitations include eventual consistency leading to data anomalies and complexity in application logic to handle asynchronous updates. Both models require careful architectural decisions to mitigate latency issues and ensure system reliability under partition events.
Evolving Big Data Architectures: Integrating CAP Theorem and BASE
Evolving Big Data architectures increasingly integrate the CAP Theorem's principles of consistency, availability, and partition tolerance with the BASE model's emphasis on Basically Available, Soft state, and Eventual consistency to address scalability and fault tolerance challenges. This hybrid approach enables distributed systems to balance strict consistency requirements against system availability and responsiveness in large-scale data environments. Leveraging both models ensures optimized data processing workflows, enhancing performance and reliability in complex big data infrastructures.
Future Trends: The Role of CAP and BASE in Modern Distributed Systems
CAP Theorem remains crucial in modern distributed systems by defining trade-offs between consistency, availability, and partition tolerance, guiding system design under network failures. The BASE model complements CAP by promoting eventual consistency and high availability, aligning with cloud-native applications and microservices architectures. Emerging trends emphasize hybrid approaches that dynamically balance CAP constraints and BASE principles to optimize performance and resilience in large-scale big data environments.
CAP Theorem vs BASE Model Infographic