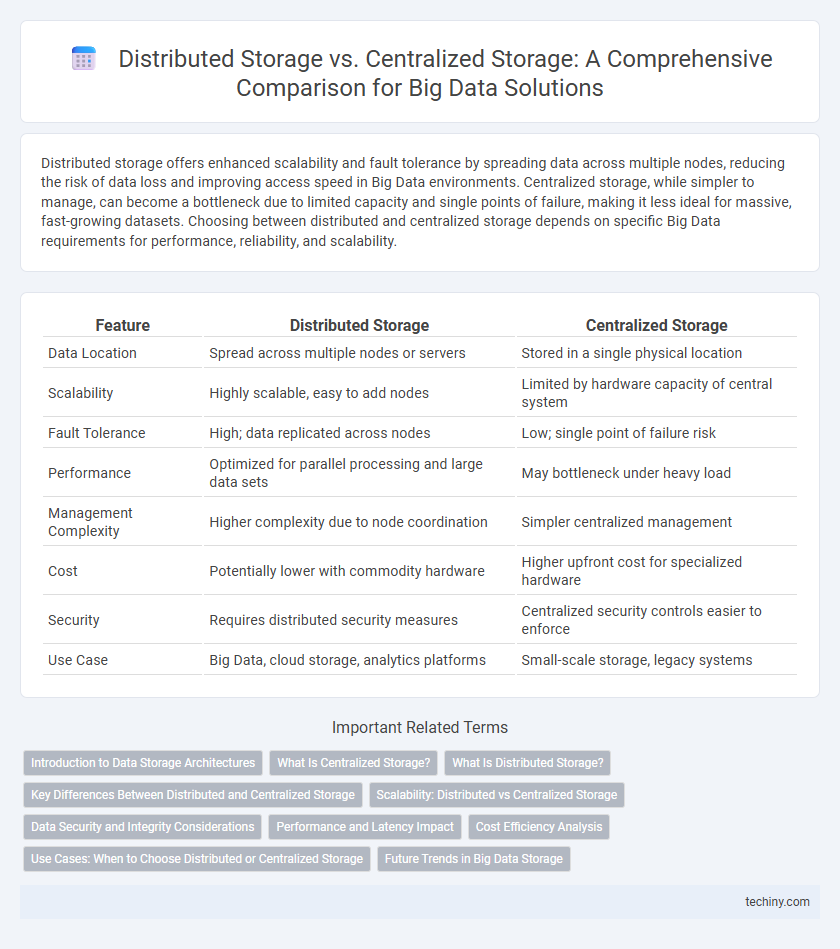
Distributed storage offers enhanced scalability and fault tolerance by spreading data across multiple nodes, reducing the risk of data loss and improving access speed in Big Data environments. Centralized storage, while simpler to manage, can become a bottleneck due to limited capacity and single points of failure, making it less ideal for massive, fast-growing datasets. Choosing between distributed and centralized storage depends on specific Big Data requirements for performance, reliability, and scalability.
Table of Comparison
| Feature | Distributed Storage | Centralized Storage |
|---|---|---|
| Data Location | Spread across multiple nodes or servers | Stored in a single physical location |
| Scalability | Highly scalable, easy to add nodes | Limited by hardware capacity of central system |
| Fault Tolerance | High; data replicated across nodes | Low; single point of failure risk |
| Performance | Optimized for parallel processing and large data sets | May bottleneck under heavy load |
| Management Complexity | Higher complexity due to node coordination | Simpler centralized management |
| Cost | Potentially lower with commodity hardware | Higher upfront cost for specialized hardware |
| Security | Requires distributed security measures | Centralized security controls easier to enforce |
| Use Case | Big Data, cloud storage, analytics platforms | Small-scale storage, legacy systems |
Introduction to Data Storage Architectures
Distributed storage architecture spreads data across multiple nodes, enhancing fault tolerance and scalability for big data applications. Centralized storage consolidates data in a single location, simplifying management but risking bottlenecks and single points of failure. Choosing between distributed and centralized storage impacts performance, reliability, and cost-efficiency in handling large-scale datasets.
What Is Centralized Storage?
Centralized storage refers to a data management approach where all data is stored, managed, and maintained in a single, central location or server. This method simplifies data governance, security protocols, and backup processes by consolidating resources, making it easier to control access and enforce policies. Although centralized storage can face scalability challenges with the growing volume of Big Data, it remains effective for organizations requiring strong data consistency and simplified architecture.
What Is Distributed Storage?
Distributed storage is a data storage architecture where data is spread across multiple physical locations or devices, enhancing fault tolerance, scalability, and access speed. Unlike centralized storage, which relies on a single location, distributed storage leverages networked nodes to ensure data redundancy and high availability. This approach is essential for big data environments, enabling efficient handling of vast datasets and supporting real-time data processing.
Key Differences Between Distributed and Centralized Storage
Distributed storage systems store data across multiple nodes or locations, enhancing redundancy, fault tolerance, and scalability for big data applications. Centralized storage consolidates data in a single location or server, simplifying management but creating potential bottlenecks and single points of failure. Distributed storage excels in handling high-volume, high-velocity big data due to its ability to parallelize data processing and support large-scale storage expansion, whereas centralized storage suits smaller datasets with lower scalability requirements.
Scalability: Distributed vs Centralized Storage
Distributed storage systems offer superior scalability by enabling data to be stored across multiple nodes, allowing seamless expansion as data volumes grow. Centralized storage struggles with scalability due to hardware limitations and increased risk of bottlenecks in a single location. High scalability in distributed storage supports large-scale big data applications by providing flexible resource allocation and improved fault tolerance.
Data Security and Integrity Considerations
Distributed storage enhances data security by minimizing single points of failure and enabling data redundancy across multiple nodes, which strengthens integrity through continuous validation and error correction. Centralized storage systems concentrate data in one location, making them more vulnerable to targeted attacks, but can simplify security management with unified control and monitoring. Ensuring integrity in distributed setups relies on robust encryption protocols and consensus mechanisms, while centralized storage demands rigorous access controls and frequent audits to prevent breaches.
Performance and Latency Impact
Distributed storage systems enhance Big Data performance by enabling parallel processing and reducing latency through data proximity to computation nodes. Centralized storage often experiences bottlenecks and higher latency due to network congestion and limited I/O throughput. Optimizing data distribution across nodes in distributed architectures significantly improves scalability and responsiveness for real-time analytics.
Cost Efficiency Analysis
Distributed storage systems reduce cost inefficiencies by leveraging commodity hardware and scaling horizontally, which minimizes upfront capital expenditure and allows incremental growth. Centralized storage often incurs higher operational expenses due to the need for robust, high-performance infrastructure and complex maintenance. Analyzing total cost of ownership reveals distributed storage as more cost-efficient for big data environments involving large-scale and variable workloads.
Use Cases: When to Choose Distributed or Centralized Storage
Distributed storage is ideal for large-scale applications requiring high availability, fault tolerance, and rapid data access across multiple locations, such as global e-commerce platforms and IoT networks. Centralized storage suits environments with limited data volume or stringent security policies, like small enterprises managing sensitive financial records or legal documents. Hybrid approaches emerge when balancing performance and control, often seen in healthcare systems where patient data necessitates centralized security but distributed access for research.
Future Trends in Big Data Storage
Distributed storage systems are rapidly evolving to accommodate the explosive growth of big data, offering scalable, fault-tolerant architectures that enhance data accessibility and processing speed. Centralized storage continues to improve in performance with advancements in high-capacity hardware and optimized data management software, but it struggles to match the flexibility and resilience of distributed models in handling diverse, large-scale datasets. Emerging trends indicate a hybrid approach combining distributed and centralized storage, leveraging edge computing and cloud integration to optimize cost-efficiency, security, and real-time analytics for future big data applications.
Distributed Storage vs Centralized Storage Infographic