Data replication involves creating and storing multiple copies of data across different systems to ensure high availability and fault tolerance in Big Data environments. Data federation, on the other hand, provides a virtualized view of data from multiple sources without moving or copying the data, enabling unified access and real-time querying. Choosing between replication and federation depends on the balance between data consistency, latency, storage costs, and query performance requirements in a Big Data pet ecosystem.
Table of Comparison
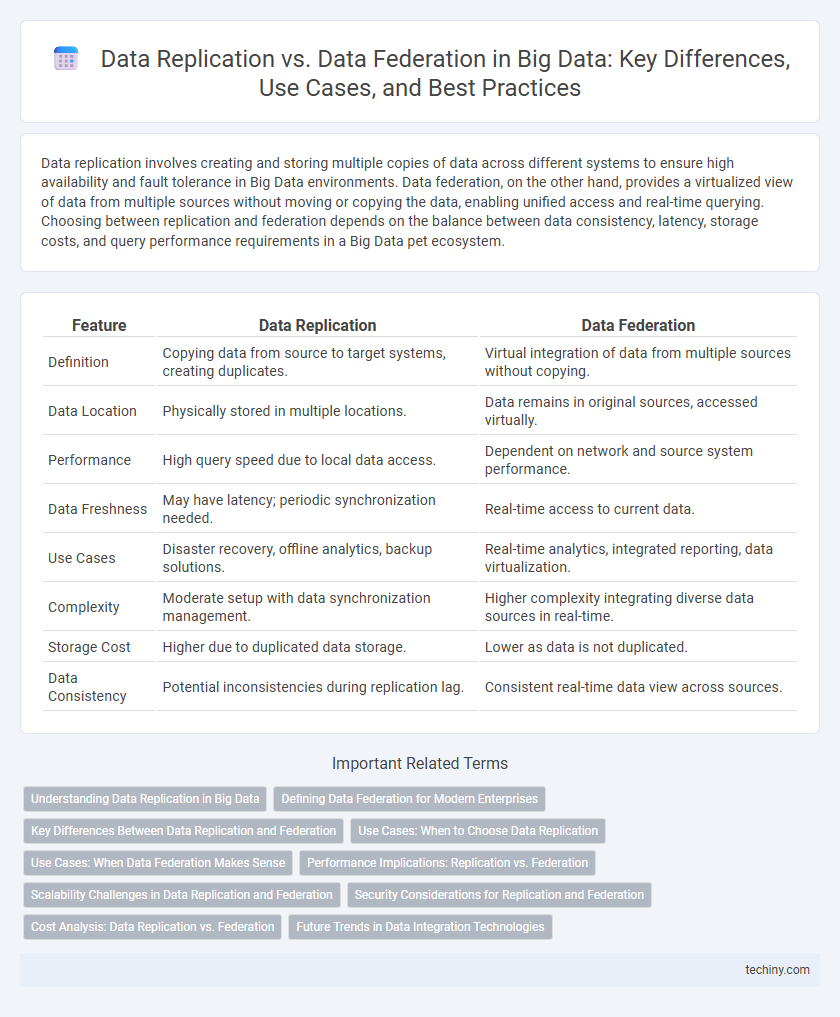
| Feature | Data Replication | Data Federation |
|---|---|---|
| Definition | Copying data from source to target systems, creating duplicates. | Virtual integration of data from multiple sources without copying. |
| Data Location | Physically stored in multiple locations. | Data remains in original sources, accessed virtually. |
| Performance | High query speed due to local data access. | Dependent on network and source system performance. |
| Data Freshness | May have latency; periodic synchronization needed. | Real-time access to current data. |
| Use Cases | Disaster recovery, offline analytics, backup solutions. | Real-time analytics, integrated reporting, data virtualization. |
| Complexity | Moderate setup with data synchronization management. | Higher complexity integrating diverse data sources in real-time. |
| Storage Cost | Higher due to duplicated data storage. | Lower as data is not duplicated. |
| Data Consistency | Potential inconsistencies during replication lag. | Consistent real-time data view across sources. |
Understanding Data Replication in Big Data
Data replication in Big Data involves copying and maintaining multiple copies of data across various nodes to ensure high availability, fault tolerance, and improved read performance. It reduces data latency and enables consistent data access by synchronizing changes across distributed environments, supporting real-time analytics and disaster recovery. Common technologies implementing data replication include Apache Kafka, Hadoop Distributed File System (HDFS), and Cassandra.
Defining Data Federation for Modern Enterprises
Data federation in modern enterprises enables real-time access to distributed data sources without physically copying data, optimizing storage and improving data agility. Unlike data replication, which duplicates data across systems for availability, federation provides a unified virtual view that supports faster decision-making and reduces data redundancy. This approach enhances scalability and simplifies data governance in complex big data environments by seamlessly integrating diverse datasets.
Key Differences Between Data Replication and Federation
Data replication involves copying data from one system to another, ensuring high availability and redundancy by maintaining multiple synchronized data copies. Data federation, on the other hand, creates a virtual database that aggregates data from disparate sources without moving the data, enabling real-time access and unified queries across heterogeneous systems. Key differences include data storage methods, with replication storing physical copies and federation providing a unified view, impacting latency, consistency, and use cases in big data environments.
Use Cases: When to Choose Data Replication
Data replication is ideal for scenarios requiring high availability and fault tolerance, such as real-time analytics and disaster recovery in Big Data environments. It ensures data consistency across multiple locations by copying datasets, enabling faster read access and reducing latency for distributed applications. Use cases with stringent uptime requirements and offline data processing needs benefit significantly from data replication over data federation.
Use Cases: When Data Federation Makes Sense
Data federation is ideal for use cases requiring real-time access to distributed data without the latency of replication, such as dynamic reporting and interactive analytics across heterogeneous data sources. It supports seamless querying across multiple databases, enabling businesses to integrate live data for decision-making without the overhead of storage duplication. This approach is particularly valuable for organizations prioritizing data consistency and agility in environments with rapidly changing datasets.
Performance Implications: Replication vs. Federation
Data replication enhances performance by storing multiple copies of data across different nodes, enabling faster query response times and improved availability through local access. Data federation relies on virtual integration without data movement, which can introduce latency and slower performance due to real-time data fetching from disparate sources. Choosing replication optimizes speed for frequent, heavy workloads, while federation suits scenarios requiring real-time access to diverse, distributed datasets with minimal storage overhead.
Scalability Challenges in Data Replication and Federation
Data replication faces scalability challenges due to increased storage requirements and network overhead as data volumes grow, leading to slower synchronization and higher costs. Data federation struggles with query performance and consistency when integrating diverse, distributed data sources, causing latency and complexity in data management. Both approaches require careful architecture design to balance scalability, data freshness, and system responsiveness in big data environments.
Security Considerations for Replication and Federation
Data replication involves copying data across multiple nodes, enhancing redundancy but increasing exposure risks due to data duplication and synchronization points that must be secured. Data federation provides unified access without data movement, reducing attack surfaces yet relying heavily on securing real-time query transmissions and access controls across diverse sources. Effective security strategies for both include robust encryption, strict authentication mechanisms, and continuous monitoring to prevent unauthorized access and ensure data integrity.
Cost Analysis: Data Replication vs. Federation
Data replication involves copying data across multiple storage systems, resulting in increased storage and maintenance costs due to redundancy. Data federation minimizes storage expenses by providing unified access to distributed datasets without the need for duplication, but may incur higher query latency and network overhead. Cost analysis reveals that replication demands upfront investment in storage infrastructure, whereas federation shifts costs towards network bandwidth and real-time data processing resources.
Future Trends in Data Integration Technologies
Data replication and data federation are evolving with advancements in AI-driven automation and cloud-native architectures, enhancing real-time data accessibility and consistency across distributed environments. Future trends emphasize hybrid integration models combining replication's reliability with federation's flexibility, enabling seamless multi-cloud and edge computing data synchronization. Emerging technologies like blockchain and metadata-driven data fabrics are set to further optimize data integration by ensuring security, governance, and dynamic data lineage tracking.
Data Replication vs Data Federation Infographic