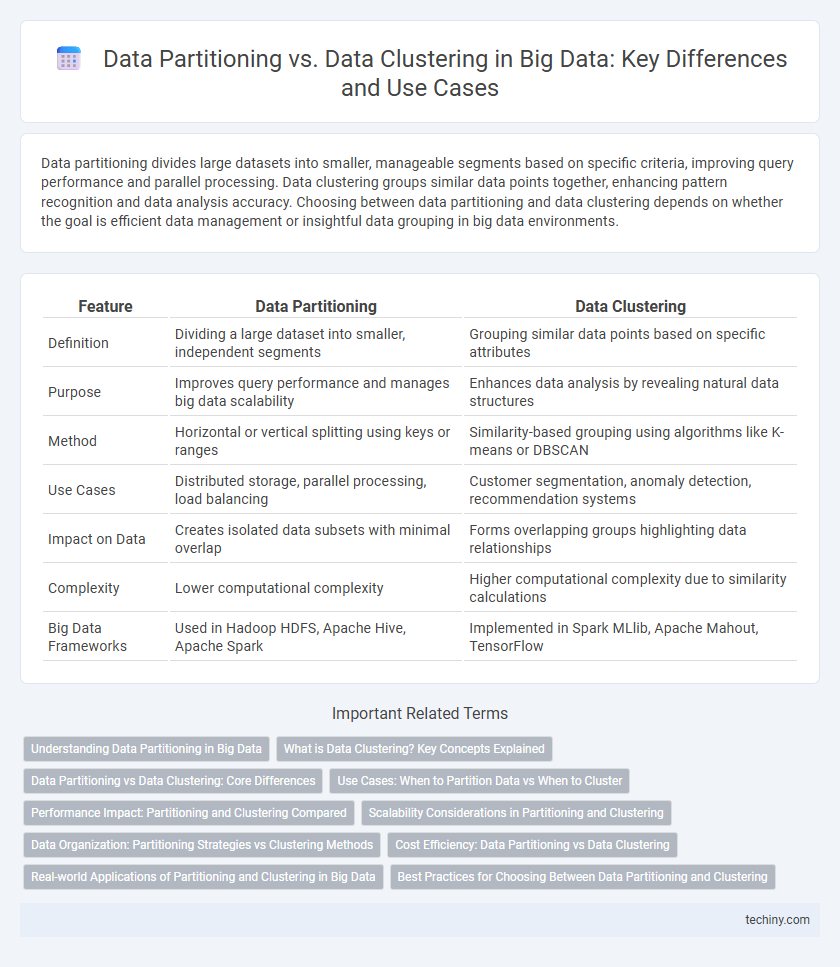
Data partitioning divides large datasets into smaller, manageable segments based on specific criteria, improving query performance and parallel processing. Data clustering groups similar data points together, enhancing pattern recognition and data analysis accuracy. Choosing between data partitioning and data clustering depends on whether the goal is efficient data management or insightful data grouping in big data environments.
Table of Comparison
| Feature | Data Partitioning | Data Clustering |
|---|---|---|
| Definition | Dividing a large dataset into smaller, independent segments | Grouping similar data points based on specific attributes |
| Purpose | Improves query performance and manages big data scalability | Enhances data analysis by revealing natural data structures |
| Method | Horizontal or vertical splitting using keys or ranges | Similarity-based grouping using algorithms like K-means or DBSCAN |
| Use Cases | Distributed storage, parallel processing, load balancing | Customer segmentation, anomaly detection, recommendation systems |
| Impact on Data | Creates isolated data subsets with minimal overlap | Forms overlapping groups highlighting data relationships |
| Complexity | Lower computational complexity | Higher computational complexity due to similarity calculations |
| Big Data Frameworks | Used in Hadoop HDFS, Apache Hive, Apache Spark | Implemented in Spark MLlib, Apache Mahout, TensorFlow |
Understanding Data Partitioning in Big Data
Data partitioning in Big Data involves dividing large datasets into smaller, manageable segments called partitions to enhance processing efficiency and parallelism. Unlike data clustering, which groups data based on feature similarity, partitioning distributes data across storage nodes or processing units, optimizing query performance and load balancing. Effective data partitioning strategies such as range, hash, or list partitioning are critical for scalable, high-speed data retrieval in distributed systems like Hadoop and Spark.
What is Data Clustering? Key Concepts Explained
Data clustering is a technique in big data that groups similar data points into clusters based on shared characteristics, enhancing the efficiency of data analysis. Key concepts include centroid, which represents the center of a cluster; distance measures, such as Euclidean or Manhattan distance, used to determine similarity; and algorithms like K-means and DBSCAN that automate the grouping process. Effective data clustering supports pattern recognition and anomaly detection, enabling more insightful decision-making in large-scale datasets.
Data Partitioning vs Data Clustering: Core Differences
Data partitioning divides large datasets into distinct, non-overlapping segments to improve processing efficiency and parallelism, while data clustering groups similar data points based on inherent characteristics or patterns to reveal meaningful relationships within the data. Partitioning optimizes data management by distributing workloads across multiple nodes, whereas clustering enhances data analysis by identifying natural groupings without predefined labels. The core difference lies in partitioning's focus on scalability and performance versus clustering's emphasis on pattern recognition and data insight.
Use Cases: When to Partition Data vs When to Cluster
Data partitioning excels in managing large-scale distributed databases by dividing datasets into distinct, manageable segments, enhancing parallel processing and fault tolerance in systems like Apache Hadoop. Data clustering is ideal for exploratory data analysis and pattern recognition tasks, such as customer segmentation in marketing or anomaly detection in cybersecurity. Partitioning suits environments requiring high scalability and load balancing, while clustering optimizes insights from unstructured data through grouping similar data points.
Performance Impact: Partitioning and Clustering Compared
Data partitioning divides large datasets into manageable segments, enabling parallel processing and reducing query response time by limiting the amount of data scanned. Data clustering organizes related data physically near each other on storage media, optimizing disk I/O and improving the efficiency of range queries. While partitioning excels in minimizing data scans for distinct data subsets, clustering enhances performance for queries accessing related data, making both techniques essential for tailored big data performance optimization.
Scalability Considerations in Partitioning and Clustering
Data partitioning enhances scalability by dividing large datasets into manageable, independent segments, allowing parallel processing and reducing query response times in Big Data environments. Data clustering improves scalability through grouping similar data points, optimizing storage and retrieval efficiency by minimizing inter-node communication. Effective scalability in Big Data systems depends on balancing partition granularity and clustering accuracy to optimize resource utilization and processing speed.
Data Organization: Partitioning Strategies vs Clustering Methods
Data partitioning strategies segment large datasets into distinct, manageable parts based on keys or ranges, optimizing query performance and parallel processing. Clustering methods organize data by grouping similar records through techniques like k-means or hierarchical clustering, enhancing data retrieval and pattern recognition. Effective data organization leverages partitioning to distribute workload and clustering to reveal inherent data structures for improved analytics.
Cost Efficiency: Data Partitioning vs Data Clustering
Data partitioning enhances cost efficiency by dividing large datasets into manageable segments, reducing data processing loads and enabling parallel computation, which lowers storage and compute expenses. In contrast, data clustering groups similar data points to improve query performance but often requires more complex computations and storage overhead, potentially increasing costs. Selecting partitioning over clustering typically yields better cost savings in big data environments by optimizing resource utilization and minimizing redundant data scans.
Real-world Applications of Partitioning and Clustering in Big Data
Data partitioning improves query performance and load balancing in distributed systems like Hadoop and Spark by dividing vast datasets into manageable chunks, enabling parallel processing and faster data retrieval. Data clustering groups similar data points, enhancing customer segmentation in marketing analytics and anomaly detection in cybersecurity by identifying patterns within massive, unstructured datasets. In real-world big data applications, partitioning optimizes storage and computational efficiency, while clustering extracts insights from complex data, driving informed decision-making across industries.
Best Practices for Choosing Between Data Partitioning and Clustering
Data Partitioning involves dividing large datasets into smaller, manageable parts based on specific criteria, which improves query performance and parallel processing efficiency. Data Clustering organizes records with similar attributes physically close on storage, enhancing retrieval speed for range queries and boosting index efficiency. Best practices for choosing between the two depend on workload characteristics: use data partitioning for scenarios with high-volume transactional processing and data clustering when queries frequently target contiguous data ranges or require optimized index scans.
Data Partitioning vs Data Clustering Infographic