Sharding divides big data into smaller, manageable pieces distributed across multiple servers, enhancing write scalability and reducing query latency. Replication creates copies of data across different nodes, improving data availability and fault tolerance by ensuring data redundancy. Choosing between sharding and replication depends on balancing performance needs with consistency and recovery requirements in big data environments.
Table of Comparison
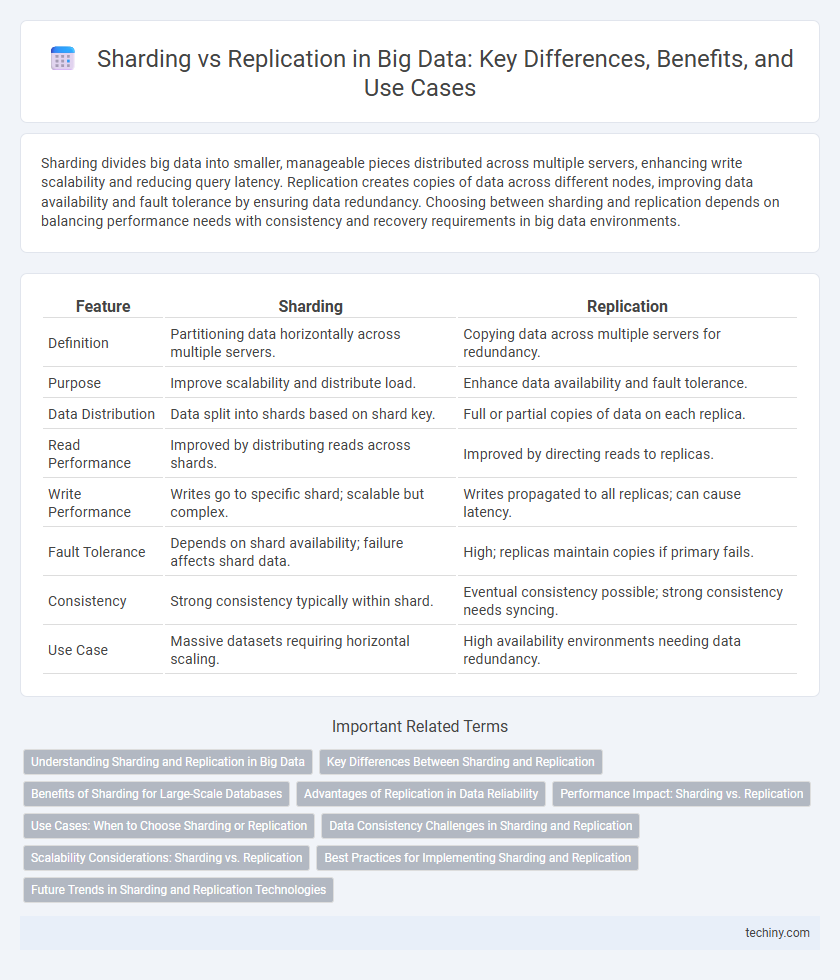
| Feature | Sharding | Replication |
|---|---|---|
| Definition | Partitioning data horizontally across multiple servers. | Copying data across multiple servers for redundancy. |
| Purpose | Improve scalability and distribute load. | Enhance data availability and fault tolerance. |
| Data Distribution | Data split into shards based on shard key. | Full or partial copies of data on each replica. |
| Read Performance | Improved by distributing reads across shards. | Improved by directing reads to replicas. |
| Write Performance | Writes go to specific shard; scalable but complex. | Writes propagated to all replicas; can cause latency. |
| Fault Tolerance | Depends on shard availability; failure affects shard data. | High; replicas maintain copies if primary fails. |
| Consistency | Strong consistency typically within shard. | Eventual consistency possible; strong consistency needs syncing. |
| Use Case | Massive datasets requiring horizontal scaling. | High availability environments needing data redundancy. |
Understanding Sharding and Replication in Big Data
Sharding in big data involves partitioning a large dataset into smaller, manageable pieces called shards, which enables parallel processing and improves query performance by distributing data across multiple servers. Replication creates copies of data shards across different nodes to ensure high availability, fault tolerance, and data durability in case of hardware failures. Understanding the balance between sharding's horizontal scaling benefits and replication's redundancy is crucial for designing efficient and resilient big data architectures.
Key Differences Between Sharding and Replication
Sharding distributes data across multiple servers to improve scalability and performance by partitioning datasets based on a shard key, while replication duplicates data across servers to enhance availability and fault tolerance. Sharding requires careful shard key selection to balance load, whereas replication primarily focuses on ensuring consistency and data redundancy. In Big Data environments, sharding optimizes query throughput by parallelizing data access, while replication ensures continuous data availability during server failures.
Benefits of Sharding for Large-Scale Databases
Sharding enhances performance in large-scale databases by distributing data across multiple servers, enabling parallel query processing and reducing latency. It improves scalability by allowing seamless addition of shards to accommodate growing data volumes without downtime. Sharding also increases fault tolerance, as failures in one shard do not impact the entire database system.
Advantages of Replication in Data Reliability
Replication enhances data reliability by creating multiple copies of data across different nodes, ensuring continuous availability in case of hardware failures. It supports fault tolerance by enabling systems to recover quickly without data loss or downtime. This redundancy significantly reduces the risk of data corruption and provides consistent backup for disaster recovery.
Performance Impact: Sharding vs. Replication
Sharding improves big data performance by distributing data across multiple nodes, enabling parallel processing and reducing query latency for large datasets. Replication enhances data availability and read throughput by maintaining copies of data across nodes, but it can introduce write latency due to synchronization overhead. Balancing sharding and replication strategies is essential to optimize response times and system reliability in distributed databases.
Use Cases: When to Choose Sharding or Replication
Sharding is ideal for use cases requiring horizontal scaling and high write throughput, such as large-scale e-commerce platforms handling diverse customer data. Replication suits scenarios needing high availability and fault tolerance, like real-time analytics systems that require consistent read access across multiple nodes. Choosing between sharding and replication depends on workload patterns, data size, and the need for data redundancy or partitioning.
Data Consistency Challenges in Sharding and Replication
Sharding distributes data across multiple databases to improve scalability but often faces data consistency challenges due to the complexity of maintaining synchronization across shards. Replication ensures data availability by copying data across multiple nodes, yet it struggles with consistency issues like eventual consistency and lag during updates. Both approaches require sophisticated conflict resolution and synchronization mechanisms to maintain reliable, accurate data across distributed systems.
Scalability Considerations: Sharding vs. Replication
Sharding enhances scalability by distributing data across multiple nodes, enabling parallel processing and reducing single-node bottlenecks in big data architectures. Replication improves data availability and fault tolerance but may introduce write latency and limits horizontal scaling since all replicas maintain the full dataset. Effective scaling strategies require balancing sharding's partitioning benefits with replication's redundancy to optimize performance in large-scale data environments.
Best Practices for Implementing Sharding and Replication
Implementing sharding requires carefully defining shard keys to evenly distribute data and minimize cross-shard queries, ensuring balanced load and high availability. Best practices for replication include configuring asynchronous replication for scalability and synchronous replication for consistency-critical applications, along with regular monitoring to detect lag and ensure data integrity. Combining sharding with replication enhances fault tolerance and performance by partitioning data across nodes while maintaining multiple copies for redundancy.
Future Trends in Sharding and Replication Technologies
Future trends in sharding and replication technologies focus on enhanced automation and intelligent data distribution using machine learning algorithms to optimize performance and resource utilization. Advances in adaptive sharding mechanisms aim to dynamically adjust shard boundaries based on workload patterns, improving scalability and fault tolerance in distributed databases. Replication technologies are evolving towards multi-cloud and geo-distributed architectures, ensuring low latency and high availability while maintaining strong consistency across diverse data centers.
Sharding vs Replication Infographic