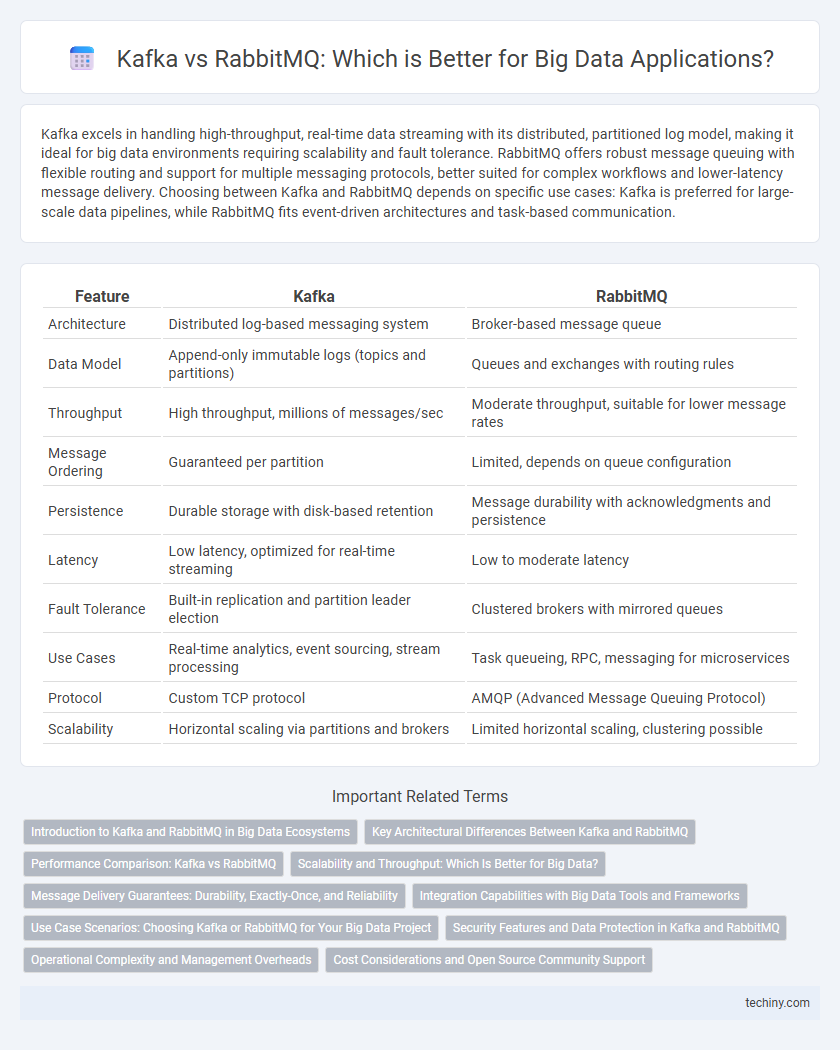
Kafka excels in handling high-throughput, real-time data streaming with its distributed, partitioned log model, making it ideal for big data environments requiring scalability and fault tolerance. RabbitMQ offers robust message queuing with flexible routing and support for multiple messaging protocols, better suited for complex workflows and lower-latency message delivery. Choosing between Kafka and RabbitMQ depends on specific use cases: Kafka is preferred for large-scale data pipelines, while RabbitMQ fits event-driven architectures and task-based communication.
Table of Comparison
| Feature | Kafka | RabbitMQ |
|---|---|---|
| Architecture | Distributed log-based messaging system | Broker-based message queue |
| Data Model | Append-only immutable logs (topics and partitions) | Queues and exchanges with routing rules |
| Throughput | High throughput, millions of messages/sec | Moderate throughput, suitable for lower message rates |
| Message Ordering | Guaranteed per partition | Limited, depends on queue configuration |
| Persistence | Durable storage with disk-based retention | Message durability with acknowledgments and persistence |
| Latency | Low latency, optimized for real-time streaming | Low to moderate latency |
| Fault Tolerance | Built-in replication and partition leader election | Clustered brokers with mirrored queues |
| Use Cases | Real-time analytics, event sourcing, stream processing | Task queueing, RPC, messaging for microservices |
| Protocol | Custom TCP protocol | AMQP (Advanced Message Queuing Protocol) |
| Scalability | Horizontal scaling via partitions and brokers | Limited horizontal scaling, clustering possible |
Introduction to Kafka and RabbitMQ in Big Data Ecosystems
Kafka is a distributed streaming platform designed for high-throughput, fault-tolerant data pipelines in Big Data ecosystems. RabbitMQ is a message broker that supports various messaging protocols, optimized for complex routing and reliable queueing. Kafka excels in real-time data processing with scalability, while RabbitMQ is ideal for legacy system integration and flexible message routing.
Key Architectural Differences Between Kafka and RabbitMQ
Kafka is designed as a distributed streaming platform with a log-based storage architecture, enabling high-throughput and fault-tolerant event processing through partitioned logs and consumer groups. RabbitMQ utilizes a traditional message broker approach based on queues and exchanges, supporting complex routing with a push-based delivery model optimized for low-latency message distribution. Kafka's architecture emphasizes scalability and persistent storage, while RabbitMQ focuses on flexible routing and protocol compatibility for diverse messaging patterns.
Performance Comparison: Kafka vs RabbitMQ
Kafka outperforms RabbitMQ in high-throughput, real-time data streaming scenarios due to its distributed architecture and efficient disk-based storage. RabbitMQ excels in complex routing and lower latency message delivery but may experience bottlenecks at scale compared to Kafka's partitioned log system. Kafka's ability to handle millions of messages per second with fault-tolerance makes it ideal for big data pipelines requiring massive parallel processing.
Scalability and Throughput: Which Is Better for Big Data?
Apache Kafka outperforms RabbitMQ in scalability and throughput, making it better suited for handling massive data streams in Big Data environments. Kafka's distributed architecture supports horizontal scaling with partitioned topics, enabling high-throughput data ingestion and processing. In contrast, RabbitMQ excels in complex routing and message delivery guarantees but may face limitations in scaling to the volume demands typical of Big Data analytics.
Message Delivery Guarantees: Durability, Exactly-Once, and Reliability
Kafka ensures high durability through its distributed log storage and replication, offering exactly-once delivery semantics with its transactional APIs for reliable message processing. RabbitMQ supports at-least-once delivery with message acknowledgments and persistent queues but lacks native exactly-once guarantees, relying on application-level handling for idempotency. Kafka's architecture prioritizes reliability in high-throughput environments, while RabbitMQ excels in flexible routing and lower latency messaging but requires additional mechanisms for strong delivery guarantees.
Integration Capabilities with Big Data Tools and Frameworks
Kafka offers robust integration capabilities with big data tools like Apache Hadoop, Spark, and Flink, enabling seamless data streaming and real-time analytics. RabbitMQ supports integration through numerous connectors and plugins but is generally better suited for message queuing than high-throughput data processing frameworks. Kafka's distributed architecture and native compatibility with big data ecosystems make it the preferred choice for scalable, low-latency data pipelines.
Use Case Scenarios: Choosing Kafka or RabbitMQ for Your Big Data Project
Kafka excels in high-throughput, real-time streaming and event-driven architectures, making it ideal for large-scale data ingestion, log aggregation, and complex event processing in Big Data projects. RabbitMQ suits scenarios requiring flexible routing, message acknowledgments, and reliability in traditional messaging patterns such as task queues and request-response workflows. Selecting Kafka or RabbitMQ depends on the project's scale, latency requirements, message durability, and the complexity of data processing pipelines.
Security Features and Data Protection in Kafka and RabbitMQ
Kafka implements robust security features including SSL/TLS encryption for data in transit, SASL authentication mechanisms, and role-based access control to ensure secure data streaming in large-scale environments. RabbitMQ offers comprehensive security through TLS encryption, pluggable authentication mechanisms, and fine-grained access control via permissions on exchanges, queues, and users. Both Kafka and RabbitMQ support secure data protection frameworks, but Kafka's integration with enterprise security tools makes it highly suitable for big data ecosystems requiring scalable and secure messaging.
Operational Complexity and Management Overheads
Kafka offers lower operational complexity compared to RabbitMQ due to its distributed architecture designed for high-throughput, fault tolerance, and scalability with minimal manual intervention. RabbitMQ requires more management overhead because of its reliance on message acknowledgments, queue maintenance, and handling complex routing logic. Kafka's streamlined partitioning and replication reduce the need for constant tuning, whereas RabbitMQ demands ongoing configuration adjustments to ensure reliability and performance.
Cost Considerations and Open Source Community Support
Kafka offers cost efficiency through its high throughput and horizontal scalability, reducing infrastructure expenses for large-scale data streaming. RabbitMQ incurs potentially higher operational costs due to lower throughput and more complex scaling requirements in high-demand environments. Both Kafka and RabbitMQ benefit from strong open-source communities, but Kafka's ecosystem is larger and more active, providing extensive tools, integrations, and real-time support for big data applications.
Kafka vs RabbitMQ Infographic