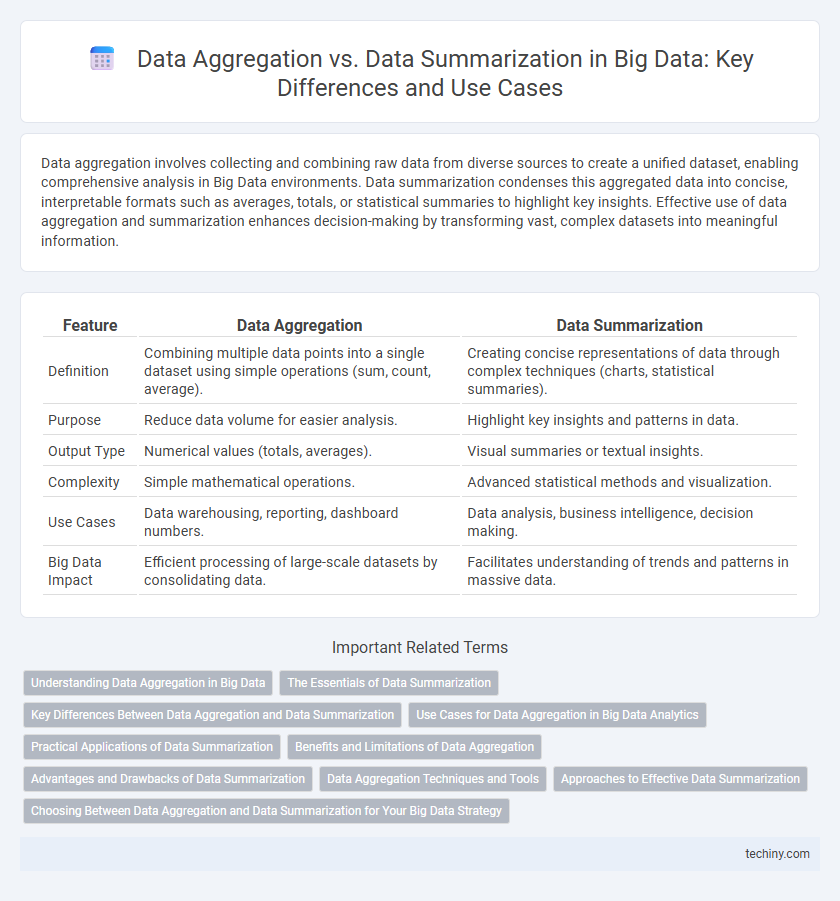
Data aggregation involves collecting and combining raw data from diverse sources to create a unified dataset, enabling comprehensive analysis in Big Data environments. Data summarization condenses this aggregated data into concise, interpretable formats such as averages, totals, or statistical summaries to highlight key insights. Effective use of data aggregation and summarization enhances decision-making by transforming vast, complex datasets into meaningful information.
Table of Comparison
| Feature | Data Aggregation | Data Summarization |
|---|---|---|
| Definition | Combining multiple data points into a single dataset using simple operations (sum, count, average). | Creating concise representations of data through complex techniques (charts, statistical summaries). |
| Purpose | Reduce data volume for easier analysis. | Highlight key insights and patterns in data. |
| Output Type | Numerical values (totals, averages). | Visual summaries or textual insights. |
| Complexity | Simple mathematical operations. | Advanced statistical methods and visualization. |
| Use Cases | Data warehousing, reporting, dashboard numbers. | Data analysis, business intelligence, decision making. |
| Big Data Impact | Efficient processing of large-scale datasets by consolidating data. | Facilitates understanding of trends and patterns in massive data. |
Understanding Data Aggregation in Big Data
Data aggregation in Big Data involves collecting and combining data from multiple sources to create a unified dataset for analysis, enabling more comprehensive insights. It supports scalable processing and efficient querying across distributed systems, often utilizing technologies like Hadoop and Spark to manage large volumes of structured and unstructured data. Understanding data aggregation is crucial for optimizing data storage, enhancing data quality, and driving informed decision-making in complex Big Data environments.
The Essentials of Data Summarization
Data summarization is a crucial process in big data analytics that involves condensing large datasets into concise summaries using statistical measures like mean, median, mode, and percentiles. Unlike data aggregation, which combines data from various sources into a single dataset, summarization focuses on extracting meaningful insights and patterns while reducing data complexity. Effective data summarization enhances data interpretability, supports faster decision-making, and optimizes storage by presenting essential information in a compact form.
Key Differences Between Data Aggregation and Data Summarization
Data aggregation involves collecting and compiling raw data from multiple sources into a unified dataset to facilitate comprehensive analysis, while data summarization focuses on distilling this compiled data into concise, meaningful statistics like averages, totals, or counts. Aggregation emphasizes data consolidation at a granular level, ensuring diverse data points are merged accurately, whereas summarization transforms this aggregated data to highlight key insights through metrics or visual summaries. Understanding these differences is crucial for effective big data processing workflows, optimizing both data storage and interpretability.
Use Cases for Data Aggregation in Big Data Analytics
Data aggregation in Big Data analytics enables efficient analysis by consolidating large volumes of raw data from diverse sources into structured datasets, facilitating faster query performance and comprehensive insights. Use cases include real-time monitoring of IoT sensor data, customer behavior analysis through aggregated transaction records, and large-scale log data consolidation for cybersecurity threat detection. These applications leverage aggregated data to enhance decision-making processes and operational efficiency across industries.
Practical Applications of Data Summarization
Data summarization condenses large datasets into meaningful insights by calculating averages, totals, or other statistics, making it essential in business intelligence for quick decision-making. Practical applications include generating sales reports, monitoring website traffic trends, and analyzing customer behavior patterns to optimize marketing strategies. This process enhances data accessibility and usability, enabling organizations to extract valuable information without handling overwhelming details.
Benefits and Limitations of Data Aggregation
Data aggregation in Big Data consolidates vast datasets into meaningful summaries, enhancing data analysis efficiency and enabling faster decision-making. This method reduces storage requirements and computational costs but may lead to the loss of granular details and potential data biases. Despite its limitations, data aggregation supports scalable analytics frameworks essential for processing high-velocity, high-volume data streams.
Advantages and Drawbacks of Data Summarization
Data summarization reduces large datasets into concise representations, enhancing computational efficiency and enabling faster insights in big data analytics. It facilitates easier visualization and interpretation but may lead to loss of granularity, potentially overlooking critical data nuances. While summarization improves performance and decision-making speed, the trade-off involves reduced detail that can impact accuracy and depth of analysis.
Data Aggregation Techniques and Tools
Data aggregation techniques in Big Data include methods such as map-reduce, distributed aggregation, and real-time stream processing to efficiently combine large datasets from diverse sources. Tools like Apache Hadoop, Apache Spark, and Apache Flink enable scalable data aggregation by parallelizing computations and supporting batch or stream processing. These technologies optimize data integration for analytics, enhancing performance in handling massive volumes of structured and unstructured data.
Approaches to Effective Data Summarization
Effective data summarization in big data relies on techniques such as clustering, sampling, and dimensionality reduction to condense vast datasets into meaningful insights. Employing algorithms like k-means, principal component analysis (PCA), and stratified sampling enhances the extraction of representative summaries while preserving data integrity. These approaches optimize computational efficiency and support accurate decision-making in complex data environments.
Choosing Between Data Aggregation and Data Summarization for Your Big Data Strategy
Choosing between data aggregation and data summarization in big data strategy depends on the specific analytical goals and dataset characteristics. Data aggregation combines multiple data points into a single composite value, enabling efficient storage and faster querying across large-scale datasets, while data summarization extracts essential patterns and insights, providing a comprehensive overview without the detailed granularity. Prioritizing aggregation is beneficial for performance optimization in real-time analytics, whereas summarization enhances interpretability for strategic decision-making and trend analysis.
Data Aggregation vs Data Summarization Infographic