Data Federation integrates data from multiple sources into a single, unified view without moving the underlying data, optimizing real-time query performance for Big Data environments. Data Virtualization offers a more dynamic layer by abstracting data access across disparate systems, enabling seamless interaction and transformation without physical data consolidation. Both technologies enhance Big Data management but differ in complexity, performance impact, and use case flexibility.
Table of Comparison
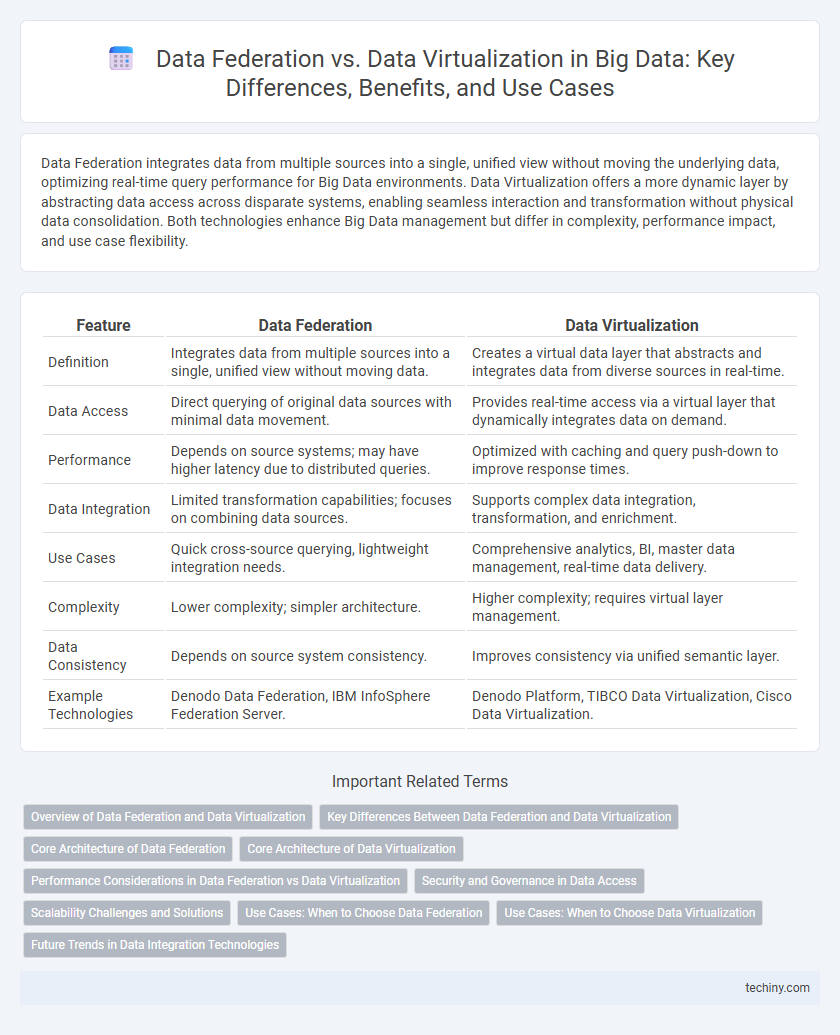
| Feature | Data Federation | Data Virtualization |
|---|---|---|
| Definition | Integrates data from multiple sources into a single, unified view without moving data. | Creates a virtual data layer that abstracts and integrates data from diverse sources in real-time. |
| Data Access | Direct querying of original data sources with minimal data movement. | Provides real-time access via a virtual layer that dynamically integrates data on demand. |
| Performance | Depends on source systems; may have higher latency due to distributed queries. | Optimized with caching and query push-down to improve response times. |
| Data Integration | Limited transformation capabilities; focuses on combining data sources. | Supports complex data integration, transformation, and enrichment. |
| Use Cases | Quick cross-source querying, lightweight integration needs. | Comprehensive analytics, BI, master data management, real-time data delivery. |
| Complexity | Lower complexity; simpler architecture. | Higher complexity; requires virtual layer management. |
| Data Consistency | Depends on source system consistency. | Improves consistency via unified semantic layer. |
| Example Technologies | Denodo Data Federation, IBM InfoSphere Federation Server. | Denodo Platform, TIBCO Data Virtualization, Cisco Data Virtualization. |
Overview of Data Federation and Data Virtualization
Data Federation integrates data from multiple sources into a unified view without moving the data, enabling faster query response and simplifying access to distributed datasets. Data Virtualization also provides a consolidated data layer, but it emphasizes real-time data access and transformation across heterogeneous systems without physical data replication. Both approaches enhance big data analytics by improving data accessibility and agility while minimizing data redundancy and latency.
Key Differences Between Data Federation and Data Virtualization
Data federation integrates data from multiple sources into a unified view without physically moving the data, enabling real-time queries across heterogeneous databases. Data virtualization creates an abstraction layer that allows users to access and manage data from disparate sources as if it were a single repository, often incorporating data transformation and caching for performance optimization. Key differences include data federation's emphasis on live access with minimal latency and data virtualization's broader capabilities in data integration, transformation, and delivery within big data environments.
Core Architecture of Data Federation
Data Federation's core architecture integrates multiple, distributed data sources into a unified virtual database through a centralized query engine, ensuring real-time access without data movement. This approach relies on data source adapters and a metadata catalog to translate and optimize queries dynamically across heterogeneous systems. Unlike data virtualization, data federation emphasizes direct query execution on source systems, minimizing latency but requiring consistent source availability for seamless data consolidation.
Core Architecture of Data Virtualization
Data Virtualization relies on a core architecture that integrates diverse data sources through a virtual data layer, enabling real-time access without physical data movement. This architecture uses metadata management, query optimization, and semantic data models to provide a unified view, enhancing agility and reducing latency compared to traditional Data Federation. By abstracting data complexities, the virtual layer supports consistent data governance, security policies, and seamless data consumption across Big Data environments.
Performance Considerations in Data Federation vs Data Virtualization
Data federation often requires complex query processing across multiple heterogeneous sources, which can introduce latency and impact performance in large-scale Big Data environments. Data virtualization optimizes query execution by creating a unified data access layer that leverages in-memory processing and smart caching, significantly enhancing response times. Performance in data federation heavily depends on source system capabilities, whereas data virtualization benefits from real-time abstraction and advanced query optimization techniques.
Security and Governance in Data Access
Data federation consolidates data from multiple sources into a unified view without moving it, enabling robust security controls by enforcing source-specific access policies and maintaining data provenance. Data virtualization abstracts data access through a virtual layer, offering centralized governance and consistent security protocols across disparate systems while reducing data duplication risks. Both approaches enhance data access security and governance but differ in implementation complexity and control granularity.
Scalability Challenges and Solutions
Data Federation faces scalability challenges due to the complexity of querying disparate data sources in real-time, often leading to performance bottlenecks as data volume and variety grow. Data Virtualization addresses these issues by creating a unified data access layer that supports dynamic data integration and query optimization, enabling efficient scaling across distributed environments. Advanced caching, parallel processing, and connection pooling techniques further enhance scalability in data virtualization platforms.
Use Cases: When to Choose Data Federation
Data Federation is ideal for use cases requiring real-time access to distributed and heterogeneous data sources without data replication, such as in financial services for fraud detection or telecom for customer analytics. It excels in scenarios needing consistent, up-to-date information from multiple systems while maintaining data sovereignty and minimizing latency. Organizations should choose Data Federation when quick, integrated querying across diverse databases is essential for decision-making and operational efficiency.
Use Cases: When to Choose Data Virtualization
Data virtualization is ideal for real-time data integration scenarios requiring instant access to diverse data sources without physical movement, such as in agile analytics and BI dashboards. It excels in environments where data agility and speed are critical, enabling seamless access to fragmented data across cloud and on-premises systems. Enterprises prioritize data virtualization when rapid insights, data governance, and minimal data duplication are essential for decision-making.
Future Trends in Data Integration Technologies
Data federation and data virtualization are evolving to address the scalability and real-time processing demands in big data ecosystems. Emerging trends emphasize AI-driven automation, enhanced metadata management, and hybrid cloud integration to optimize data accessibility and governance. Future data integration technologies are expected to prioritize seamless, unified data views across distributed sources with minimal latency and improved security protocols.
Data Federation vs Data Virtualization Infographic