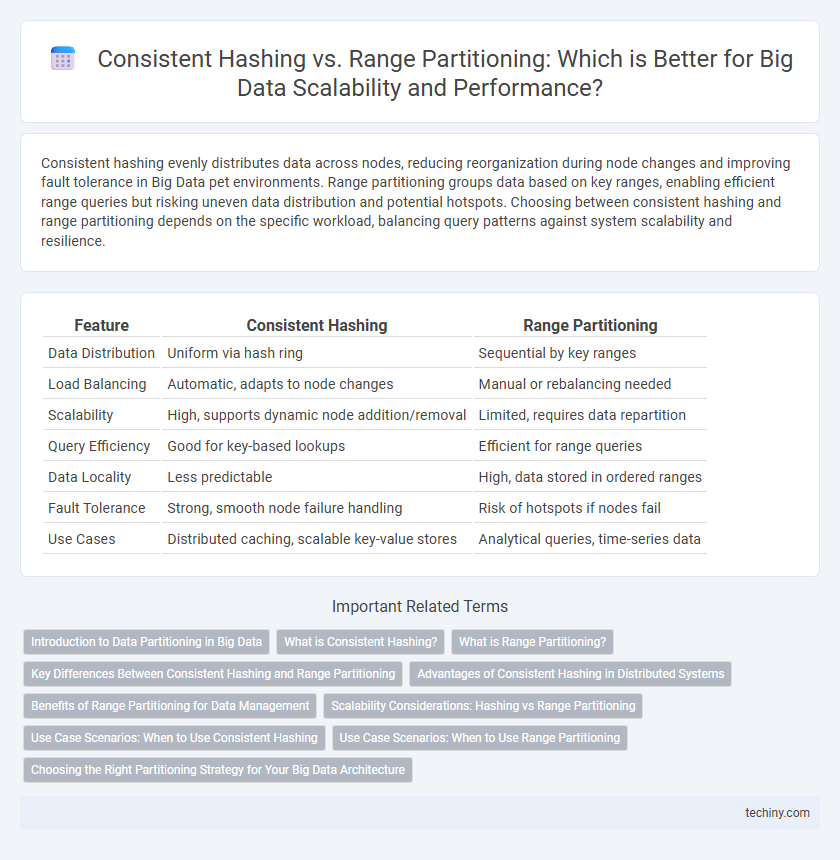
Consistent hashing evenly distributes data across nodes, reducing reorganization during node changes and improving fault tolerance in Big Data pet environments. Range partitioning groups data based on key ranges, enabling efficient range queries but risking uneven data distribution and potential hotspots. Choosing between consistent hashing and range partitioning depends on the specific workload, balancing query patterns against system scalability and resilience.
Table of Comparison
| Feature | Consistent Hashing | Range Partitioning |
|---|---|---|
| Data Distribution | Uniform via hash ring | Sequential by key ranges |
| Load Balancing | Automatic, adapts to node changes | Manual or rebalancing needed |
| Scalability | High, supports dynamic node addition/removal | Limited, requires data repartition |
| Query Efficiency | Good for key-based lookups | Efficient for range queries |
| Data Locality | Less predictable | High, data stored in ordered ranges |
| Fault Tolerance | Strong, smooth node failure handling | Risk of hotspots if nodes fail |
| Use Cases | Distributed caching, scalable key-value stores | Analytical queries, time-series data |
Introduction to Data Partitioning in Big Data
Data partitioning in Big Data enables efficient distribution and management of massive datasets across multiple nodes. Consistent hashing assigns data to nodes based on hash values, providing scalability and fault tolerance by minimizing data reshuffling during node changes. Range partitioning divides data into contiguous subranges, optimizing query performance for range-based queries but requiring careful load balancing to avoid data hotspots.
What is Consistent Hashing?
Consistent hashing is a distributed hashing scheme that maps data to servers in a way that minimizes reorganization when nodes join or leave a cluster, enhancing scalability in Big Data systems. It distributes keys uniformly across a ring of nodes by hashing both data keys and node identifiers, ensuring balanced load and fault tolerance. This approach is crucial for large-scale distributed databases and caching systems, where maintaining data availability and reducing remapping overhead are essential.
What is Range Partitioning?
Range partitioning organizes data by dividing it into contiguous key ranges, enabling efficient query processing for specific value intervals. It simplifies load balancing and improves performance for range scans by grouping similar keys together on the same node or partition. This technique is widely used in distributed databases and big data systems to optimize data locality and reduce query latency.
Key Differences Between Consistent Hashing and Range Partitioning
Consistent hashing distributes data across nodes by mapping keys to a circular hash ring, ensuring minimal data movement during node addition or removal, which enhances system scalability and fault tolerance. Range partitioning divides data into contiguous key ranges assigned to nodes, enabling efficient range queries but causing significant data reshuffling when scaling or node failures occur. The key difference lies in consistent hashing's dynamic adaptability to node changes with balanced load distribution, contrasted with range partitioning's focus on query efficiency at the cost of higher maintenance complexity.
Advantages of Consistent Hashing in Distributed Systems
Consistent hashing minimizes data redistribution when nodes are added or removed, enhancing scalability and fault tolerance in distributed systems. It ensures uniform data distribution across nodes, reducing load imbalance and hotspots compared to range partitioning. This approach simplifies node management and improves overall system stability in dynamic environments with frequent topology changes.
Benefits of Range Partitioning for Data Management
Range partitioning improves query efficiency by allowing targeted scans over specific data intervals, reducing the volume of data accessed during retrieval. It simplifies load balancing and data distribution by logically segmenting data into continuous ranges, which benefits time-series and range-based queries. This method enhances data management by supporting ordered data storage, enabling efficient range queries and easier data maintenance such as archiving or purging old data.
Scalability Considerations: Hashing vs Range Partitioning
Consistent hashing offers superior scalability for big data systems by evenly distributing data across nodes, minimizing rehashing when nodes are added or removed. Range partitioning can lead to data skew and hotspots as data distribution depends on key ranges, which may cause uneven load and require complex rebalancing. Therefore, consistent hashing enhances scalability by ensuring stable, balanced data allocation in dynamic environments compared to range partitioning.
Use Case Scenarios: When to Use Consistent Hashing
Consistent hashing is ideal for distributed systems requiring dynamic scalability and fault tolerance, such as large-scale key-value stores like Amazon Dynamo or distributed caching systems like Memcached. It efficiently balances load and minimizes data redistribution when nodes are added or removed, making it suitable for environments with frequent node churn. Use consistent hashing when handling non-sequential, uniformly distributed keys in highly available, scalable applications demanding minimal downtime.
Use Case Scenarios: When to Use Range Partitioning
Range partitioning is ideal for use cases involving time-series data or ordered datasets where queries frequently target continuous key ranges, such as logs analysis and financial transactions. It enhances query performance by enabling efficient range scans and range-based data pruning, making it suitable for analytical workloads requiring sorted data access. Systems processing sequentially generated data or implementing data retention policies benefit significantly from range partitioning's predictable data distribution.
Choosing the Right Partitioning Strategy for Your Big Data Architecture
Choosing the right partitioning strategy in big data architecture significantly impacts scalability and query performance. Consistent hashing excels in dynamic environments with frequent node additions or failures, offering uniform data distribution and minimal reorganization. Range partitioning is ideal for range queries and ordered scans, as it partitions data based on key ranges but may cause data skew and hotspot issues under uneven distributions.
Consistent Hashing vs Range Partitioning Infographic