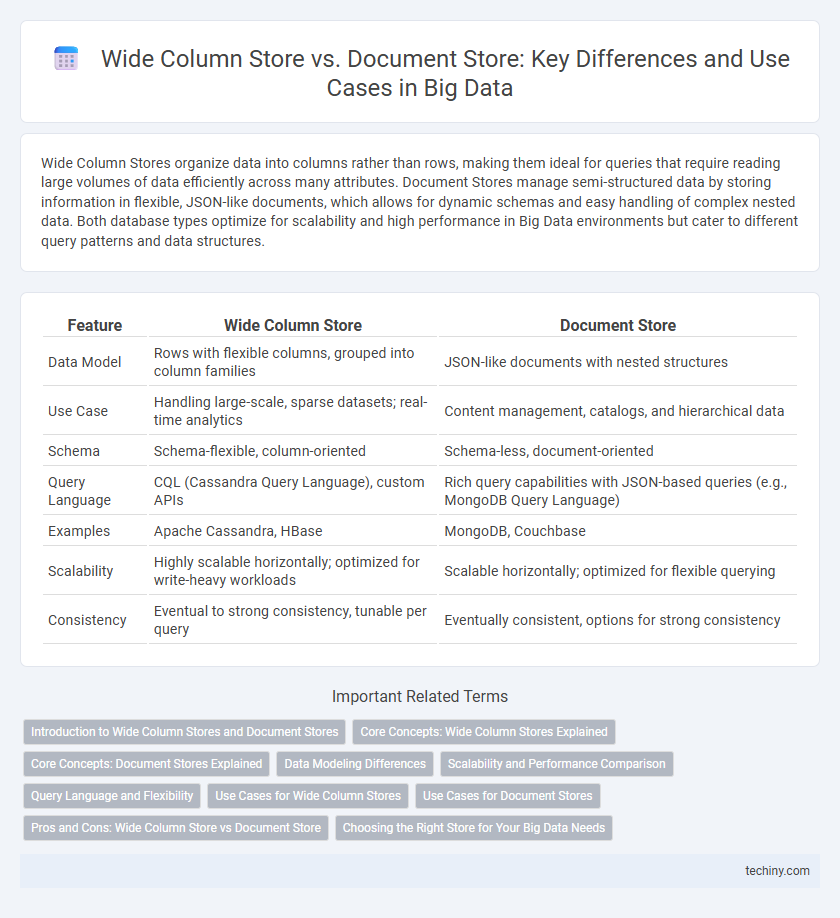
Wide Column Stores organize data into columns rather than rows, making them ideal for queries that require reading large volumes of data efficiently across many attributes. Document Stores manage semi-structured data by storing information in flexible, JSON-like documents, which allows for dynamic schemas and easy handling of complex nested data. Both database types optimize for scalability and high performance in Big Data environments but cater to different query patterns and data structures.
Table of Comparison
| Feature | Wide Column Store | Document Store |
|---|---|---|
| Data Model | Rows with flexible columns, grouped into column families | JSON-like documents with nested structures |
| Use Case | Handling large-scale, sparse datasets; real-time analytics | Content management, catalogs, and hierarchical data |
| Schema | Schema-flexible, column-oriented | Schema-less, document-oriented |
| Query Language | CQL (Cassandra Query Language), custom APIs | Rich query capabilities with JSON-based queries (e.g., MongoDB Query Language) |
| Examples | Apache Cassandra, HBase | MongoDB, Couchbase |
| Scalability | Highly scalable horizontally; optimized for write-heavy workloads | Scalable horizontally; optimized for flexible querying |
| Consistency | Eventual to strong consistency, tunable per query | Eventually consistent, options for strong consistency |
Introduction to Wide Column Stores and Document Stores
Wide Column Stores organize data into rows and dynamic columns, enabling efficient storage and retrieval of large-scale, sparse datasets commonly used in Big Data applications such as Apache Cassandra and HBase. Document Stores, like MongoDB and Couchbase, manage data in flexible, JSON-like documents that allow for powerful querying and scalability in semi-structured data environments. Both database types support horizontal scaling, but Wide Column Stores excel in write-heavy workloads while Document Stores offer greater schema flexibility for evolving data models.
Core Concepts: Wide Column Stores Explained
Wide column stores organize data into tables, rows, and dynamic columns grouped into column families, enabling efficient read and write operations across large datasets. Unlike traditional relational databases, they allow flexible schema design where each row can have a different set of columns, optimizing storage and access for sparse data. Core examples such as Apache Cassandra and HBase demonstrate how wide column stores excel in handling high-velocity, high-volume big data workloads with horizontal scalability.
Core Concepts: Document Stores Explained
Document stores organize data as flexible, schema-less JSON or BSON documents, allowing for easy representation of complex and nested data structures. Each document acts as a self-contained unit, storing related attributes and enabling efficient retrieval by document ID or indexed fields. This architecture supports horizontal scaling and dynamic data models, making it ideal for applications requiring rapid development and diverse data types.
Data Modeling Differences
Wide Column Stores organize data into tables with rows and flexible columns grouped into column families, enabling efficient storage of sparse data and fast read/write operations for large-scale analytics. Document Stores structure data as JSON-like documents, allowing rich, nested, and schema-less data models that support complex hierarchical relationships and flexible querying. These differing architectures impact indexing strategies and query optimization, with Wide Column Stores favoring denormalized datasets and Document Stores enabling dynamic, semi-structured data representation.
Scalability and Performance Comparison
Wide Column Stores like Apache Cassandra offer exceptional horizontal scalability by distributing data across multiple nodes with efficient write and read performance, especially for time-series and large-scale analytical workloads. Document Stores such as MongoDB provide flexible schema design with good scalability, excelling in handling semi-structured data and complex queries, but may experience performance bottlenecks under heavy write loads or large-scale distributed environments. Both database types optimize for different access patterns, with Wide Column Stores typically outperforming Document Stores in linear scalability and write throughput.
Query Language and Flexibility
Wide Column Stores like Apache Cassandra use CQL (Cassandra Query Language), which resembles SQL and supports complex queries with efficient read/write operations across distributed nodes. Document Stores such as MongoDB utilize a flexible, JSON-based query language that allows dynamic queries and rich, nested document structures for evolving use cases. The query flexibility in Document Stores often surpasses Wide Column Stores, making them ideal for semi-structured data and rapid application development.
Use Cases for Wide Column Stores
Wide column stores excel in handling large-scale, high-velocity data with flexible schemas, ideal for time-series analysis, IoT data management, and recommendation engines. Their efficient storage of sparse data and rapid read/write capabilities support real-time analytics and large-scale transactional workloads. Enterprises leverage wide column stores like Apache Cassandra and HBase for scalable, fault-tolerant solutions in telecommunications, finance, and social media platforms.
Use Cases for Document Stores
Document stores excel in managing semi-structured data, making them ideal for content management systems, user profiles, and e-commerce catalogs where flexible schema design is crucial. They support fast querying and indexing of JSON or BSON documents, which benefits applications requiring dynamic, nested data models like real-time analytics and personalization engines. Use cases involving hierarchical data, such as customer interaction histories or product configurations, leverage document stores for efficient storage and rapid retrieval.
Pros and Cons: Wide Column Store vs Document Store
Wide Column Stores excel in handling large-scale, sparse datasets with high write and read throughput, making them ideal for time-series or real-time analytics applications; however, complex queries and joins can be challenging due to their denormalized design. Document Stores offer flexible schema design with JSON-like documents, enabling easier representation of semi-structured data and nested objects, but they may experience performance degradation with highly relational data or large, unindexed documents. Choosing between Wide Column Stores and Document Stores depends on workload characteristics, as Wide Column Stores provide scalability and speed for massive, flat datasets, while Document Stores prioritize flexibility and developer-friendly data modeling.
Choosing the Right Store for Your Big Data Needs
Choosing the right store for big data depends on your data model and query patterns; wide column stores excel in handling large-scale, sparse datasets with high write throughput, ideal for time series and sensor data. Document stores offer flexible, schema-less structures suited for hierarchical and semi-structured data, enabling efficient querying of nested documents. Evaluate scalability, consistency requirements, and data complexity to select between Cassandra or HBase for wide column needs and MongoDB or Couchbase for document-based applications.
Wide Column Store vs Document Store Infographic