Hive offers a SQL-like query language called HiveQL that simplifies data analysis on large datasets stored in Hadoop, making it ideal for users with SQL experience. Pig uses a procedural data flow language called Pig Latin that provides more flexibility for complex data transformations and script-based processing. Both tools optimize big data workflows, with Hive favoring analytical queries and Pig excelling in data manipulation and ETL processes.
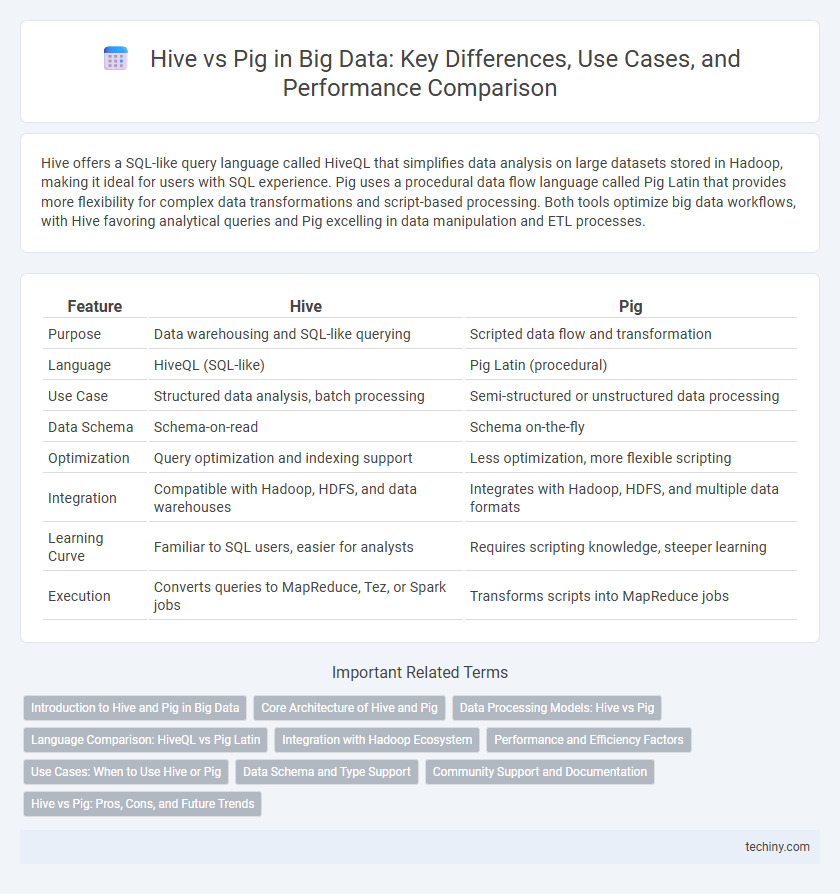
Table of Comparison
| Feature | Hive | Pig |
|---|---|---|
| Purpose | Data warehousing and SQL-like querying | Scripted data flow and transformation |
| Language | HiveQL (SQL-like) | Pig Latin (procedural) |
| Use Case | Structured data analysis, batch processing | Semi-structured or unstructured data processing |
| Data Schema | Schema-on-read | Schema on-the-fly |
| Optimization | Query optimization and indexing support | Less optimization, more flexible scripting |
| Integration | Compatible with Hadoop, HDFS, and data warehouses | Integrates with Hadoop, HDFS, and multiple data formats |
| Learning Curve | Familiar to SQL users, easier for analysts | Requires scripting knowledge, steeper learning |
| Execution | Converts queries to MapReduce, Tez, or Spark jobs | Transforms scripts into MapReduce jobs |
Introduction to Hive and Pig in Big Data
Hive and Pig are prominent data processing tools in the Big Data ecosystem, designed to simplify querying and analyzing large datasets stored in Hadoop Distributed File System (HDFS). Hive uses a SQL-like language called HiveQL, making it accessible for users familiar with traditional databases, while Pig employs a procedural scripting language called Pig Latin, offering more flexibility for complex data transformations. Both tools enable efficient data summarization, querying, and analysis, but Hive is often preferred for structured data and reporting, whereas Pig excels in handling unstructured and semi-structured data workflows.
Core Architecture of Hive and Pig
Hive architecture is based on a data warehousing model using a Metastore to manage metadata, a Driver to parse queries, and a Compiler that converts HiveQL into MapReduce or Tez jobs for execution on Hadoop clusters. Pig's architecture revolves around a Latin-based scripting language (Pig Latin) that is converted into a directed acyclic graph (DAG) of MapReduce jobs by the Pig Engine, with components like the Parser, Optimizer, and Execution Engine facilitating data flow and processing. Both Hive and Pig operate within the Hadoop ecosystem but differ fundamentally, with Hive emphasizing SQL-like query parsing via a Metastore and Pig focusing on procedural data flow scripting optimized through its execution engine.
Data Processing Models: Hive vs Pig
Hive employs a SQL-like query language called HiveQL for data warehousing and supports declarative querying over structured and semi-structured data, enabling efficient batch processing. Pig uses Pig Latin, a procedural scripting language designed for processing and transforming large datasets through a series of data flow steps, allowing more flexibility in complex data pipelines. While Hive is optimized for SQL-based analytics on large-scale data, Pig excels in iterative data processing and complex data manipulation tasks in Hadoop environments.
Language Comparison: HiveQL vs Pig Latin
HiveQL, a SQL-like query language, enables users to write declarative queries for data analysis in Hive, making it accessible for those familiar with traditional databases. Pig Latin offers a procedural data flow language designed for complex data transformations and ETL processes, providing greater flexibility in scripting workflows. HiveQL excels in structured query operations, while Pig Latin is optimized for iterative programming and custom processing within the Hadoop ecosystem.
Integration with Hadoop Ecosystem
Hive seamlessly integrates with the Hadoop ecosystem through its reliance on Hadoop Distributed File System (HDFS) and compatibility with MapReduce, Tez, and Spark execution engines, enabling efficient querying and data warehousing. Pig interacts with Hadoop ecosystem components by executing Pig Latin scripts that compile into MapReduce jobs, primarily optimized for data transformation and ETL processes within HDFS. Both Hive and Pig leverage Hadoop's scalable storage and processing power but serve different roles: Hive excels in SQL-like querying, while Pig offers a procedural approach for complex data manipulation.
Performance and Efficiency Factors
Hive offers faster query execution by optimizing SQL-like queries with a cost-based optimizer and supports complex joins and indexing, making it highly efficient for large-scale data warehousing. Pig provides a flexible data flow language, which allows custom scripts for transformations but may suffer from longer processing times due to its procedural nature and reliance on MapReduce. Performance in Hive generally outpaces Pig in batch processing tasks, while Pig excels in iterative data pipelines where flexible scripting outweighs raw speed.
Use Cases: When to Use Hive or Pig
Hive excels in structured data analysis and SQL-like querying on large datasets in data warehousing contexts, making it ideal for batch processing and business intelligence tasks. Pig is better suited for exploratory data analysis, ETL (extract, transform, load) workflows, and processing semi-structured or unstructured data with its procedural data flow language, Pig Latin. Choose Hive for environments requiring schema enforcement and complex query capabilities, and Pig for flexible, iterative data transformation and ad hoc data pipelines.
Data Schema and Type Support
Hive provides a robust data schema mechanism with a traditional table structure supporting complex data types like structs, arrays, and maps, allowing for strong schema enforcement during query execution. Pig uses a flexible data flow language called Pig Latin that handles semi-structured data without strict schema enforcement, supporting basic types and complex nested types through tuples, bags, and maps. Hive's schema-on-read approach contrasts with Pig's more dynamic schema management, making Hive more suitable for structured, schema-driven data processing in big data environments.
Community Support and Documentation
Hive benefits from a larger and more active community supported by extensive documentation maintained by the Apache Software Foundation, facilitating easier troubleshooting and resource availability. Pig, while robust for procedural data processing, has a smaller user base and less comprehensive documentation, which can limit support and learning resources. Choosing Hive often results in quicker issue resolution and access to richer community-driven content for big data analytics.
Hive vs Pig: Pros, Cons, and Future Trends
Hive offers a SQL-like interface ideal for data warehousing and structured queries, providing scalability and ease of use but often slower for complex transformations. Pig excels in handling unstructured data with its procedural scripting language, enabling more flexible data pipelines, though it has steeper learning curves and less community support. Future trends suggest Hive's integration with SQL-on-Hadoop engines will enhance performance, while Pig may see reduced adoption as newer frameworks like Apache Spark gain traction for big data processing.
Hive vs Pig Infographic