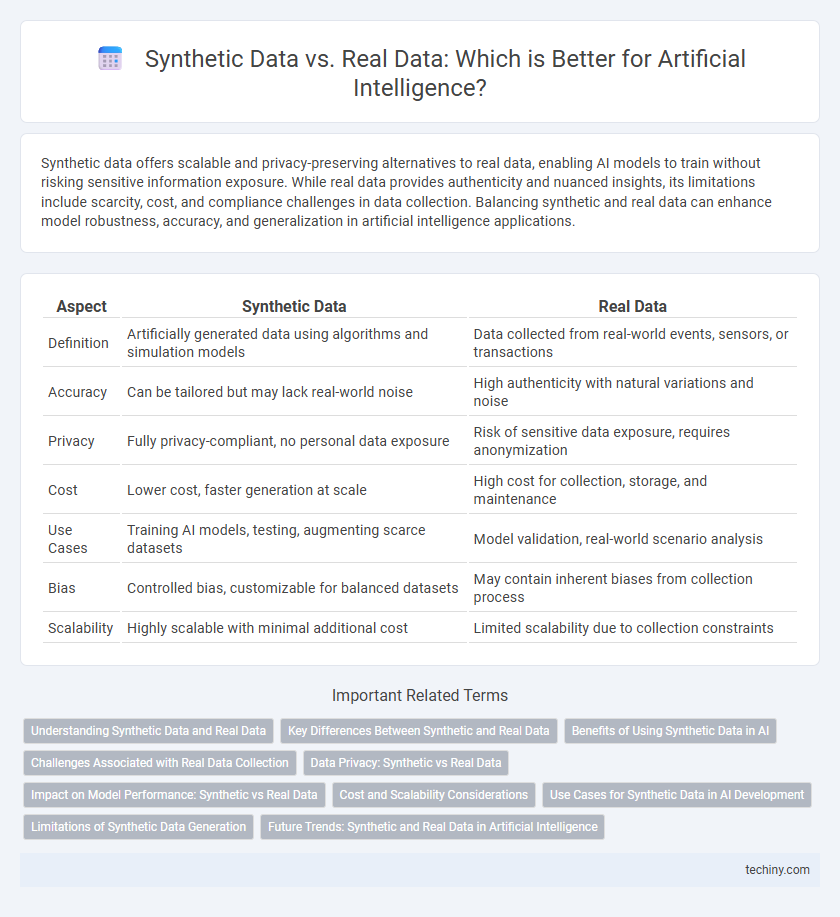
Synthetic data offers scalable and privacy-preserving alternatives to real data, enabling AI models to train without risking sensitive information exposure. While real data provides authenticity and nuanced insights, its limitations include scarcity, cost, and compliance challenges in data collection. Balancing synthetic and real data can enhance model robustness, accuracy, and generalization in artificial intelligence applications.
Table of Comparison
| Aspect | Synthetic Data | Real Data |
|---|---|---|
| Definition | Artificially generated data using algorithms and simulation models | Data collected from real-world events, sensors, or transactions |
| Accuracy | Can be tailored but may lack real-world noise | High authenticity with natural variations and noise |
| Privacy | Fully privacy-compliant, no personal data exposure | Risk of sensitive data exposure, requires anonymization |
| Cost | Lower cost, faster generation at scale | High cost for collection, storage, and maintenance |
| Use Cases | Training AI models, testing, augmenting scarce datasets | Model validation, real-world scenario analysis |
| Bias | Controlled bias, customizable for balanced datasets | May contain inherent biases from collection process |
| Scalability | Highly scalable with minimal additional cost | Limited scalability due to collection constraints |
Understanding Synthetic Data and Real Data
Synthetic data is artificially generated information created using algorithms to simulate real-world scenarios, often employed to train machine learning models while preserving privacy and reducing data collection costs. Real data, sourced directly from actual events or user interactions, provides authentic and high-fidelity insights that reflect true patterns and behaviors but may present challenges related to privacy, availability, and bias. Understanding the differences between synthetic and real data helps organizations balance data quality, compliance, and practicality in artificial intelligence applications.
Key Differences Between Synthetic and Real Data
Synthetic data is artificially generated by algorithms to mimic real-world data patterns, while real data is collected from actual events or observations. Key differences include the origin, with synthetic data offering controlled environments and privacy preservation, whereas real data provides authentic context and inherent variability. Synthetic data enables scalable datasets for training AI models without privacy risks, but real data ensures higher accuracy and validity in model evaluation.
Benefits of Using Synthetic Data in AI
Synthetic data enhances AI model training by providing vast, diverse datasets that preserve privacy and reduce biases inherent in real data. It accelerates development cycles through scalable and customizable data generation, enabling robust testing across rare or edge cases. Leveraging synthetic data minimizes reliance on costly, time-consuming data collection while improving model generalization and performance.
Challenges Associated with Real Data Collection
Real data collection in artificial intelligence faces significant challenges such as high costs, time consumption, and privacy concerns that limit accessibility and scalability. Issues like data bias, missing values, and inconsistent formats undermine model accuracy and reliability. Additionally, legal and ethical constraints restrict the use and sharing of sensitive information, complicating data acquisition efforts.
Data Privacy: Synthetic vs Real Data
Synthetic data mitigates privacy concerns by generating artificial datasets that replicate real-world patterns without exposing sensitive personal information. Unlike real data, which often requires stringent handling and anonymization to comply with data protection regulations such as GDPR and HIPAA, synthetic data inherently avoids these risks by design. This privacy-preserving nature enables safer data sharing and robust AI model training without compromising individual confidentiality.
Impact on Model Performance: Synthetic vs Real Data
Synthetic data offers scalable, privacy-preserving datasets that can enhance model training, especially when real data is scarce or sensitive. However, models trained on synthetic data may face generalization challenges due to lack of genuine variability and complexity present in real datasets. Combining synthetic data augmentation with real data often yields optimal model performance, balancing diversity and authenticity.
Cost and Scalability Considerations
Synthetic data offers significant cost advantages over real data by eliminating expenses related to data collection, labeling, and privacy compliance, making it a scalable solution for training AI models. Real data acquisition often involves high costs and logistical challenges, especially when dealing with large volumes or sensitive information. Synthetic data can be generated quickly and in vast quantities, enabling scalable AI development without the financial and operational burdens associated with real data.
Use Cases for Synthetic Data in AI Development
Synthetic data enables AI development by providing diverse training datasets that overcome privacy constraints and data scarcity. It is extensively used in computer vision for autonomous driving, allowing models to learn from rare or hazardous scenarios that are difficult to capture with real-world data. Furthermore, synthetic data accelerates innovation in healthcare AI by simulating patient records while preserving confidentiality and supporting robust algorithm training.
Limitations of Synthetic Data Generation
Synthetic data generation faces significant limitations, including potential biases that do not fully replicate the nuances of real-world data distributions, leading to reduced model accuracy. The complexity of accurately simulating diverse scenarios and rare events often results in synthetic datasets lacking sufficient variability and authenticity. Security concerns also arise as synthetic data may inadvertently expose sensitive information if the underlying real data is not properly anonymized.
Future Trends: Synthetic and Real Data in Artificial Intelligence
Synthetic data generation leverages advanced AI techniques such as generative adversarial networks (GANs) and reinforcement learning to create vast, diverse datasets that enhance model training while preserving privacy and reducing costs. Real data remains crucial for validating AI models and providing authentic context, especially in regulated industries like healthcare and finance where accuracy and compliance are paramount. Future trends indicate a hybrid approach, integrating synthetic and real data to optimize AI performance, improve generalization, and accelerate development cycles across various sectors.
Synthetic Data vs Real Data Infographic