Hive and Impala are both powerful tools for querying big data stored in Hadoop, with Hive known for its extensive support of SQL-like queries and compatibility with various data formats. Impala offers significantly faster query performance by leveraging in-memory processing and avoiding the overhead of MapReduce jobs. While Hive excels in complex batch processing and large-scale data analysis, Impala is preferred for low-latency, interactive analytics and real-time data exploration.
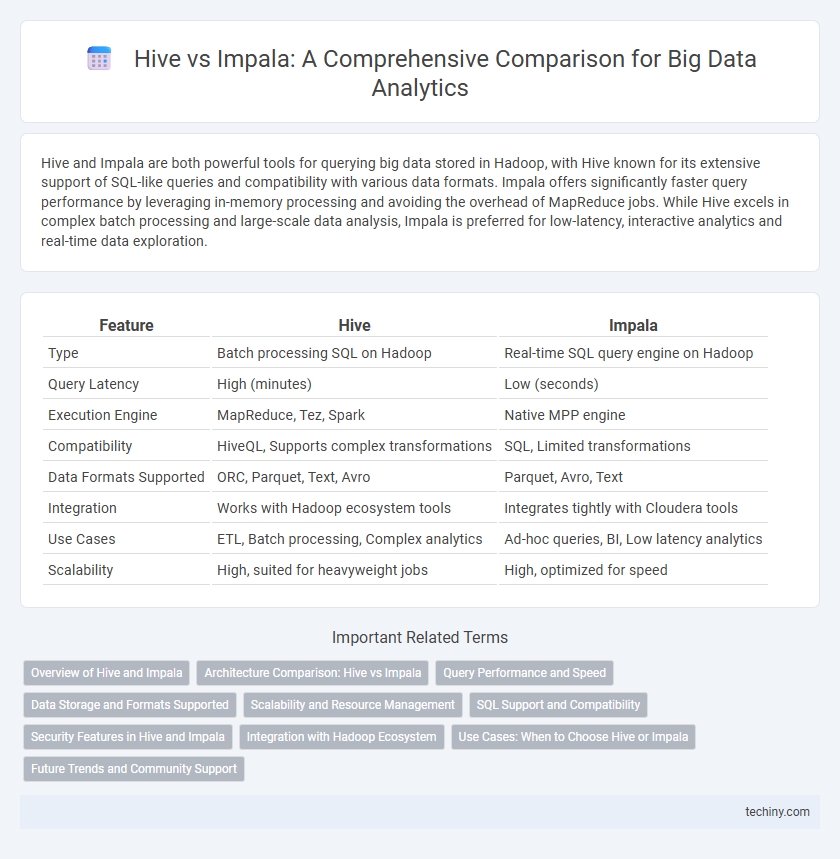
Table of Comparison
| Feature | Hive | Impala |
|---|---|---|
| Type | Batch processing SQL on Hadoop | Real-time SQL query engine on Hadoop |
| Query Latency | High (minutes) | Low (seconds) |
| Execution Engine | MapReduce, Tez, Spark | Native MPP engine |
| Compatibility | HiveQL, Supports complex transformations | SQL, Limited transformations |
| Data Formats Supported | ORC, Parquet, Text, Avro | Parquet, Avro, Text |
| Integration | Works with Hadoop ecosystem tools | Integrates tightly with Cloudera tools |
| Use Cases | ETL, Batch processing, Complex analytics | Ad-hoc queries, BI, Low latency analytics |
| Scalability | High, suited for heavyweight jobs | High, optimized for speed |
Overview of Hive and Impala
Hive and Impala are prominent SQL query engines designed for big data analytics on Hadoop platforms. Hive utilizes a batch processing model with MapReduce, making it suitable for complex, long-running queries and extensive ETL processes, while Impala offers low-latency, real-time query performance by bypassing MapReduce and directly executing queries on HDFS or HBase. Both support HiveQL syntax, but Impala is optimized for interactive analytics, delivering faster response times and higher concurrency in large-scale data environments.
Architecture Comparison: Hive vs Impala
Hive leverages a traditional MapReduce architecture, executing queries through batch processing which can result in higher latency for complex data workloads. Impala employs a massively parallel processing (MPP) architecture designed for real-time, low-latency SQL query execution directly on Hadoop Distributed File System (HDFS) data. The architectural distinction enables Impala to deliver faster query performance by bypassing MapReduce and operating in-memory, whereas Hive excels in handling large-scale ETL tasks with fault-tolerant MapReduce jobs.
Query Performance and Speed
Hive uses a batch processing model optimized for complex ETL workloads but exhibits higher latency in query execution compared to Impala, which leverages a massively parallel processing (MPP) architecture to deliver real-time, low-latency query responses. Impala bypasses MapReduce, enabling faster SQL query performance on Hadoop Distributed File System (HDFS) data with sub-second response times for ad-hoc queries. Benchmark tests show Impala often outperforms Hive by an order of magnitude in speed, making it ideal for interactive analytics and time-sensitive business intelligence tasks.
Data Storage and Formats Supported
Hive supports a wide range of data storage formats including ORC, Parquet, Avro, and text files, making it highly versatile for ETL and batch processing tasks. Impala is optimized for low-latency SQL queries and primarily supports Parquet, Avro, and text formats, enabling efficient read operations on data stored in HDFS or cloud storage. Both leverage Hadoop Distributed File System (HDFS) but Impala's design emphasizes in-memory processing for faster query performance on supported formats.
Scalability and Resource Management
Hive handles scalability by optimizing query execution through Apache Tez or MapReduce, efficiently managing resources in large, batch-oriented workloads across distributed clusters. Impala delivers low-latency queries by directly accessing HDFS and HBase, offering fine-grained resource management and real-time scalability for interactive analytics. Both systems integrate with YARN for resource allocation, but Impala's design prioritizes dynamic resource adjustment to enhance concurrency and performance in big data environments.
SQL Support and Compatibility
Hive supports a wide range of SQL-92 compliant queries with extensions for analytical functions, making it suitable for complex batch processing in Big Data environments. Impala offers low-latency, high-performance SQL querying optimized for interactive analytics while maintaining compatibility with Hive Metastore and the Hive Query Language (HQL). Both tools integrate with Hadoop ecosystems, but Impala excels in real-time SQL support, whereas Hive prioritizes scalability for large-scale data warehousing tasks.
Security Features in Hive and Impala
Hive integrates robust security features such as SQL standard-based authorization, Apache Ranger for fine-grained access control, and Kerberos authentication to protect sensitive data. Impala also supports Kerberos authentication and leverages Apache Sentry for role-based access control, ensuring strict data access policies. Both tools offer encryption mechanisms for data at rest and in transit, enhancing overall security in Big Data environments.
Integration with Hadoop Ecosystem
Hive offers seamless integration with the Hadoop ecosystem by supporting batch processing through MapReduce, Tez, and Spark execution engines, making it suitable for complex ETL workflows and large-scale data warehousing. Impala provides low-latency, interactive SQL queries by directly accessing data stored in HDFS and HBase without requiring data movement, optimized for real-time analytics within the Hadoop environment. Both tools leverage Hadoop's storage and resource management capabilities, but Hive excels in batch-oriented analytics while Impala is preferred for fast, ad-hoc querying.
Use Cases: When to Choose Hive or Impala
Hive is ideal for batch processing and complex ETL workflows involving large-scale data transformations, making it suitable for data warehousing tasks with extensive SQL support and integration with Hadoop ecosystem tools. Impala excels in low-latency, interactive queries on Hadoop, providing real-time analytics and faster response times for BI dashboards and ad-hoc data exploration. Choose Hive for heavy data processing and long-running jobs, while Impala is preferred for speed-sensitive applications requiring immediate query results.
Future Trends and Community Support
Hive and Impala continue evolving with future trends emphasizing real-time analytics and enhanced integration with cloud-native platforms. Hive benefits from a robust open-source community driving innovations in scalability and machine learning compatibility, while Impala's user base focuses on low-latency SQL queries and streamlined data warehousing solutions. Growing adoption of Kubernetes and containerization further shapes community contributions and feature roadmaps for both technologies.
Hive vs Impala Infographic