Hadoop Distributed File System (HDFS) offers high-throughput access to large datasets and is optimized for on-premises big data environments, providing data locality and fault tolerance within a cluster. Amazon S3 delivers scalable, durable cloud storage with seamless integration for big data analytics and real-time data processing across distributed systems. Choosing between HDFS and Amazon S3 depends on factors like infrastructure control, scalability requirements, and integration with cloud services.
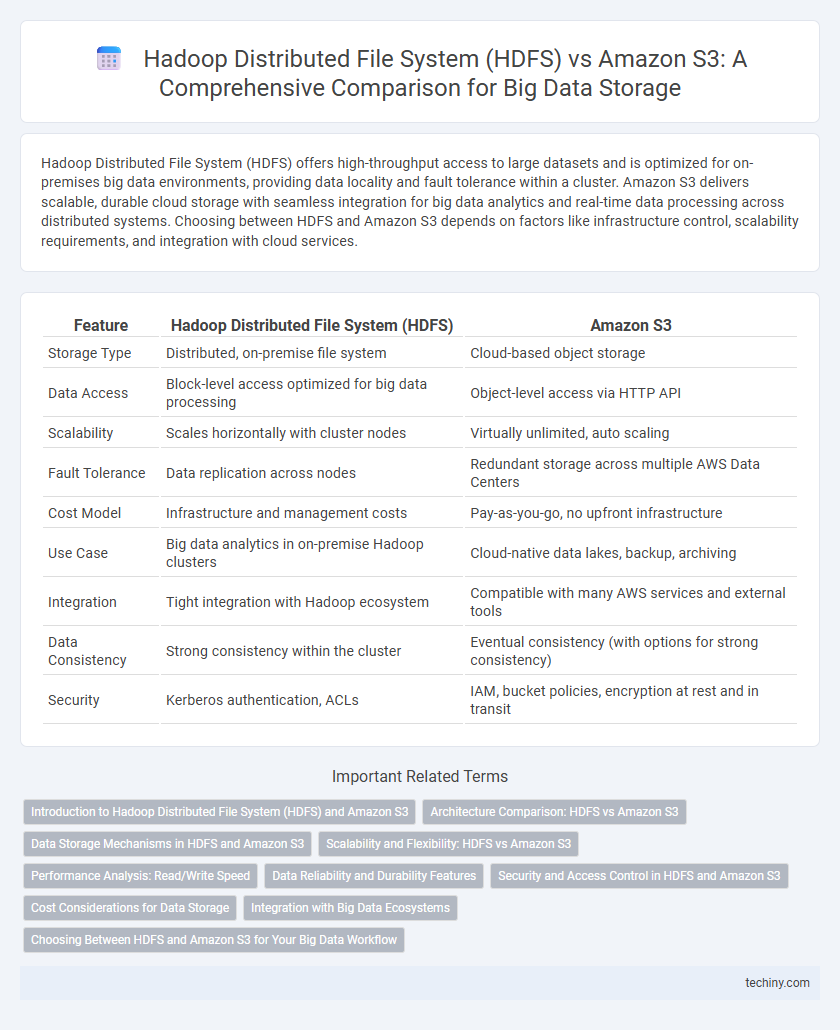
Table of Comparison
| Feature | Hadoop Distributed File System (HDFS) | Amazon S3 |
|---|---|---|
| Storage Type | Distributed, on-premise file system | Cloud-based object storage |
| Data Access | Block-level access optimized for big data processing | Object-level access via HTTP API |
| Scalability | Scales horizontally with cluster nodes | Virtually unlimited, auto scaling |
| Fault Tolerance | Data replication across nodes | Redundant storage across multiple AWS Data Centers |
| Cost Model | Infrastructure and management costs | Pay-as-you-go, no upfront infrastructure |
| Use Case | Big data analytics in on-premise Hadoop clusters | Cloud-native data lakes, backup, archiving |
| Integration | Tight integration with Hadoop ecosystem | Compatible with many AWS services and external tools |
| Data Consistency | Strong consistency within the cluster | Eventual consistency (with options for strong consistency) |
| Security | Kerberos authentication, ACLs | IAM, bucket policies, encryption at rest and in transit |
Introduction to Hadoop Distributed File System (HDFS) and Amazon S3
Hadoop Distributed File System (HDFS) is a scalable, fault-tolerant storage system designed to handle large datasets across clusters of commodity hardware, providing high-throughput access to application data. Amazon S3 (Simple Storage Service) is a cloud-based object storage service offering unlimited scalability, data durability, and seamless integration with various AWS services. Both HDFS and Amazon S3 serve as foundational storage solutions in big data architectures, with HDFS optimized for on-premise cluster environments and Amazon S3 excelling in cloud-native, distributed data storage.
Architecture Comparison: HDFS vs Amazon S3
Hadoop Distributed File System (HDFS) uses a master-slave architecture with a NameNode managing metadata and multiple DataNodes storing actual data blocks, enabling high-throughput access optimized for big data processing within a single cluster. Amazon S3 employs a distributed object storage architecture with a flat namespace, designed for scalability and durability across multiple geographic regions, offering highly available, persistent storage accessed via RESTful APIs. HDFS is tightly integrated with the Hadoop ecosystem for on-premises, batch-oriented workloads, while Amazon S3 provides a serverless, cloud-native service supporting diverse data analytics and real-time applications.
Data Storage Mechanisms in HDFS and Amazon S3
Hadoop Distributed File System (HDFS) stores data by dividing it into large blocks, typically 128MB or 256MB, which are distributed across multiple nodes with replication for fault tolerance and high throughput. Amazon S3 uses an object storage model, storing data as discrete objects in a flat namespace with metadata, ensuring high durability through automatic data replication across multiple availability zones. HDFS's block-based architecture optimizes large-scale data processing workloads, while S3's object storage allows for scalable, flexible, and highly available data retrieval and management in cloud environments.
Scalability and Flexibility: HDFS vs Amazon S3
Hadoop Distributed File System (HDFS) offers high scalability within on-premises clusters by distributing data across multiple nodes, enabling efficient processing of large datasets. Amazon S3 provides virtually unlimited scalability with its cloud-based architecture, automatically handling data storage growth without infrastructure management. Flexibility in HDFS is limited to predefined cluster configurations, whereas Amazon S3 supports diverse data types and seamless integration with various cloud services, enhancing adaptable data workflows.
Performance Analysis: Read/Write Speed
Hadoop Distributed File System (HDFS) delivers high throughput with optimized data locality, enhancing read/write speed for large-scale batch processing workloads. Amazon S3 offers scalable object storage with potentially higher latency due to its remote access model, impacting performance in latency-sensitive applications. Benchmark tests show HDFS outperforms Amazon S3 in sequential read/write operations, while S3 provides more flexibility and durability for diverse cloud-native environments.
Data Reliability and Durability Features
Hadoop Distributed File System (HDFS) ensures data reliability through block replication across multiple nodes, allowing automatic recovery from hardware failures and reducing data loss risk. Amazon S3 offers superior durability by replicating data across multiple geographically dispersed data centers, providing 99.999999999% (11 nines) durability and continuous integrity checks. Both systems use data redundancy, but Amazon S3's cloud-based architecture delivers higher fault tolerance and long-term data preservation compared to on-premises HDFS deployments.
Security and Access Control in HDFS and Amazon S3
HDFS employs Kerberos authentication and Access Control Lists (ACLs) to ensure robust security and granular permission management within big data environments, while Amazon S3 relies on AWS Identity and Access Management (IAM) policies, bucket policies, and Access Control Lists for flexible and scalable access control. Encryption at rest and in transit is supported by both HDFS and Amazon S3, with Amazon S3 offering integrated server-side encryption options like SSE-S3, SSE-KMS, and client-side encryption. Fine-grained access control in Amazon S3 enables multi-tenant environments and secure data sharing, whereas HDFS is designed for tightly controlled clusters with centralized authentication and authorization frameworks.
Cost Considerations for Data Storage
Hadoop Distributed File System (HDFS) offers cost advantages through on-premises infrastructure control, avoiding ongoing cloud service fees but requiring significant upfront capital for hardware and maintenance. Amazon S3 operates on a pay-as-you-go pricing model, with costs linked to data volume, access frequency, and data transfer, promoting scalability without large initial investments. Evaluating workload patterns and long-term storage needs is essential for choosing the most cost-effective solution between HDFS and S3.
Integration with Big Data Ecosystems
Hadoop Distributed File System (HDFS) seamlessly integrates with the Apache Hadoop ecosystem, providing native compatibility with tools like Apache Spark, Hive, and MapReduce for efficient big data processing. Amazon S3 supports a wide range of big data frameworks through connectors and APIs, enabling scalable cloud storage that complements platforms such as EMR and Databricks. Both HDFS and Amazon S3 facilitate distributed data management but differ in deployment models, with HDFS optimized for on-premises clusters and S3 offering flexible, serverless cloud integration.
Choosing Between HDFS and Amazon S3 for Your Big Data Workflow
Choosing between Hadoop Distributed File System (HDFS) and Amazon S3 for your big data workflow depends on factors such as data access patterns, scalability, and integration needs. HDFS offers high-throughput access to large datasets with data locality advantages, making it ideal for on-premises Hadoop clusters, while Amazon S3 provides virtually unlimited scalability, durability of 99.999999999%, and seamless integration with AWS analytics services for cloud-based workflows. Cost considerations include infrastructure management for HDFS versus pay-as-you-go storage and data transfer fees in Amazon S3.
Hadoop Distributed File System (HDFS) vs Amazon S3 Infographic