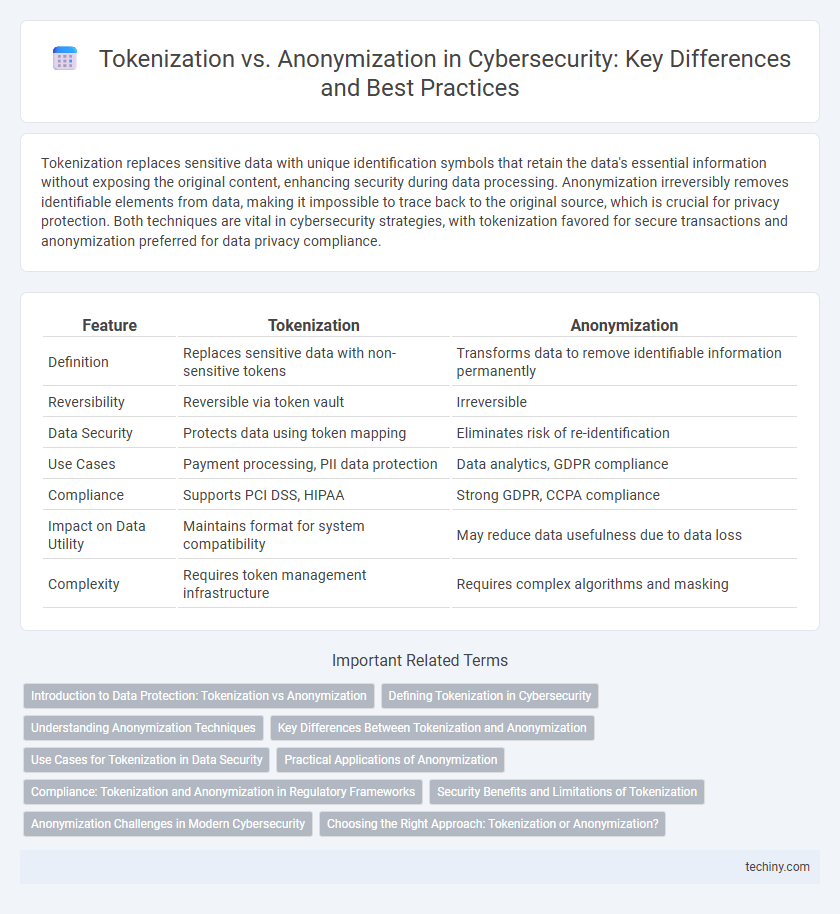
Tokenization replaces sensitive data with unique identification symbols that retain the data's essential information without exposing the original content, enhancing security during data processing. Anonymization irreversibly removes identifiable elements from data, making it impossible to trace back to the original source, which is crucial for privacy protection. Both techniques are vital in cybersecurity strategies, with tokenization favored for secure transactions and anonymization preferred for data privacy compliance.
Table of Comparison
| Feature | Tokenization | Anonymization |
|---|---|---|
| Definition | Replaces sensitive data with non-sensitive tokens | Transforms data to remove identifiable information permanently |
| Reversibility | Reversible via token vault | Irreversible |
| Data Security | Protects data using token mapping | Eliminates risk of re-identification |
| Use Cases | Payment processing, PII data protection | Data analytics, GDPR compliance |
| Compliance | Supports PCI DSS, HIPAA | Strong GDPR, CCPA compliance |
| Impact on Data Utility | Maintains format for system compatibility | May reduce data usefulness due to data loss |
| Complexity | Requires token management infrastructure | Requires complex algorithms and masking |
Introduction to Data Protection: Tokenization vs Anonymization
Tokenization replaces sensitive data with unique identification symbols that retain the original data format, enhancing secure data processing without exposing actual information. Anonymization irreversibly removes or alters personal identifiers, ensuring data privacy by preventing re-identification in datasets. Both methods play crucial roles in data protection strategies, with tokenization enabling secure data handling and anonymization supporting regulatory compliance in cybersecurity frameworks.
Defining Tokenization in Cybersecurity
Tokenization in cybersecurity refers to the process of substituting sensitive data with unique identification symbols or tokens that retain essential information without compromising security. These tokens are designed to be irreversibly mapped back to the original data only through a secure tokenization system, reducing the risk of data exposure during processing and storage. Unlike anonymization, tokenization preserves data format and usability, enabling secure transactions while maintaining compliance with data protection regulations such as PCI DSS.
Understanding Anonymization Techniques
Anonymization techniques in cybersecurity focus on irreversibly removing or masking personal identifiers from datasets to protect individual privacy while enabling data analysis. Common methods include data masking, generalization, and differential privacy, each designed to minimize re-identification risks by altering or aggregating sensitive information. Effective anonymization ensures compliance with data protection regulations like GDPR while maintaining data utility for secure processing and sharing.
Key Differences Between Tokenization and Anonymization
Tokenization replaces sensitive data elements with non-sensitive equivalents called tokens, preserving the original data format without revealing the actual information, whereas anonymization irreversibly removes or masks data to prevent any association with the original identity. Tokenization maintains data usability for business processes while anonymization focuses on data privacy by eliminating personal identifiers. Key differences include tokenization's reversibility through secure token mapping and anonymization's permanent transformation ensuring compliance with data protection regulations like GDPR and HIPAA.
Use Cases for Tokenization in Data Security
Tokenization is widely used in payment processing to secure credit card information by replacing sensitive data with non-sensitive tokens, reducing the risk of data breaches. It is also essential in healthcare for protecting patient records while maintaining data usability for compliance with HIPAA regulations. Enterprises implement tokenization in customer data platforms to safeguard personally identifiable information (PII) without losing the ability to perform data analytics and business insights.
Practical Applications of Anonymization
Anonymization is widely applied in healthcare data sharing, ensuring patient privacy while enabling research and data analysis. It allows organizations to comply with regulations like GDPR by removing personally identifiable information from datasets. Practical use cases include anonymizing customer data for marketing analytics and safeguarding sensitive financial records during audits.
Compliance: Tokenization and Anonymization in Regulatory Frameworks
Tokenization and anonymization are critical techniques in cybersecurity for meeting regulatory compliance requirements such as GDPR, HIPAA, and PCI DSS. Tokenization replaces sensitive data with non-sensitive equivalents, preserving format while reducing breach impact, aligning with PCI DSS mandates for protecting payment information. Anonymization irreversibly removes personal identifiers ensuring data subjects cannot be re-identified, supporting GDPR compliance by enabling secure data processing without personal data exposure.
Security Benefits and Limitations of Tokenization
Tokenization enhances cybersecurity by replacing sensitive data with non-sensitive equivalents, reducing the risk of data breaches and minimizing exposure during data storage and transmission. Its security benefits include preserving data format, enabling seamless integration with existing systems, and supporting compliance with standards like PCI DSS. However, tokenization depends on secure token vault management, and if the vault is compromised, tokenized data can be exposed, posing a significant limitation compared to anonymization, which irreversibly alters data to prevent re-identification.
Anonymization Challenges in Modern Cybersecurity
Anonymization faces significant challenges in modern cybersecurity due to evolving re-identification techniques and the increasing availability of auxiliary data that can link anonymized datasets back to individuals. Maintaining data utility while ensuring irreversible anonymization often results in a trade-off that complicates effective data protection. The complexity of balancing privacy requirements with analytics needs requires advanced methods beyond traditional anonymization to safeguard sensitive information.
Choosing the Right Approach: Tokenization or Anonymization?
Selecting between tokenization and anonymization depends on the specific data protection needs and regulatory compliance requirements. Tokenization replaces sensitive data with non-sensitive equivalents while preserving format and usability, making it ideal for payment processing and data retention scenarios. Anonymization irreversibly removes identifiable information, providing stronger privacy for data analytics and sharing but limiting data utility for operational purposes.
Tokenization vs Anonymization Infographic