Tokenization splits text into individual units such as words or phrases, enabling detailed analysis and processing of language data. Lemmatization reduces words to their base or dictionary form, improving the accuracy of text understanding by normalizing variations. Both techniques are fundamental in natural language processing, enhancing the effectiveness of AI models in tasks like sentiment analysis and machine translation.
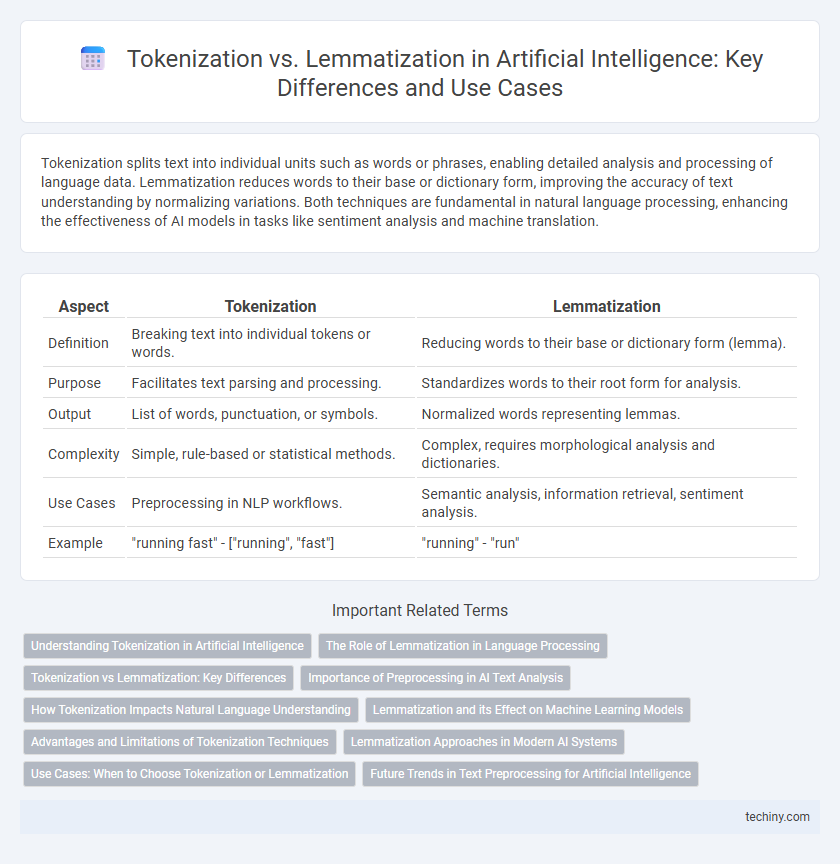
Table of Comparison
| Aspect | Tokenization | Lemmatization |
|---|---|---|
| Definition | Breaking text into individual tokens or words. | Reducing words to their base or dictionary form (lemma). |
| Purpose | Facilitates text parsing and processing. | Standardizes words to their root form for analysis. |
| Output | List of words, punctuation, or symbols. | Normalized words representing lemmas. |
| Complexity | Simple, rule-based or statistical methods. | Complex, requires morphological analysis and dictionaries. |
| Use Cases | Preprocessing in NLP workflows. | Semantic analysis, information retrieval, sentiment analysis. |
| Example | "running fast" - ["running", "fast"] | "running" - "run" |
Understanding Tokenization in Artificial Intelligence
Tokenization in Artificial Intelligence involves breaking down text into smaller units called tokens, which can be words, phrases, or symbols, enabling machines to efficiently process and analyze natural language. This fundamental step in natural language processing (NLP) facilitates tasks such as text classification, sentiment analysis, and machine translation by converting unstructured text into a structured format. Proper tokenization improves the accuracy of downstream processes by ensuring consistent segmentation of input data.
The Role of Lemmatization in Language Processing
Lemmatization plays a crucial role in language processing by reducing words to their base or dictionary form, enabling more accurate understanding of meaning across different contexts. Unlike tokenization, which segments text into individual units, lemmatization enhances semantic analysis and improves tasks like information retrieval, machine translation, and sentiment analysis. This process relies on morphological analysis and linguistic knowledge, making it essential for developing advanced natural language understanding systems.
Tokenization vs Lemmatization: Key Differences
Tokenization segments text into meaningful units called tokens, such as words, phrases, or sentences, enabling machines to process language at a granular level. Lemmatization reduces words to their base or dictionary form, known as lemmas, facilitating the understanding of a word's meaning across different contexts. Key differences lie in their purpose and output: tokenization focuses on splitting text for structural analysis, while lemmatization focuses on semantic normalization to improve language comprehension in NLP applications.
Importance of Preprocessing in AI Text Analysis
Tokenization and lemmatization serve as crucial preprocessing steps in AI text analysis, enabling more accurate natural language understanding and machine learning model performance. Tokenization breaks texts into meaningful units like words or subwords, facilitating efficient parsing, while lemmatization reduces words to their base forms to improve semantic consistency. Effective preprocessing through tokenization and lemmatization enhances feature extraction, reduces dimensionality, and increases the accuracy of AI-driven text classification, sentiment analysis, and information retrieval tasks.
How Tokenization Impacts Natural Language Understanding
Tokenization breaks text into meaningful units called tokens, forming the foundation for natural language understanding (NLU) by enabling models to analyze sentence structure and word relationships. It directly affects the accuracy of downstream tasks like part-of-speech tagging, entity recognition, and sentiment analysis by determining how effectively input data is segmented. Precise tokenization improves the interpretability of text data, facilitating better model comprehension and more accurate semantic representations.
Lemmatization and its Effect on Machine Learning Models
Lemmatization reduces words to their base or dictionary form, improving consistency in text data by addressing morphological variations. This normalization enhances the quality of features extracted for machine learning models, leading to better generalization and accuracy in natural language processing tasks. By minimizing noise and redundancy, lemmatization supports more efficient training and reliable predictions in applications like sentiment analysis and topic modeling.
Advantages and Limitations of Tokenization Techniques
Tokenization in Artificial Intelligence involves breaking text into smaller units such as words or subwords, which simplifies text processing and enhances the performance of language models like BERT and GPT. Its advantages include improved text analysis precision and efficient handling of large datasets, while limitations involve challenges with ambiguous text, context loss, and difficulties managing complex languages with rich morphology. Advanced tokenization methods such as Byte-Pair Encoding (BPE) address some issues but may still struggle with rare or out-of-vocabulary words compared to lemmatization's focus on root word normalization.
Lemmatization Approaches in Modern AI Systems
Lemmatization approaches in modern AI systems leverage advanced natural language processing techniques to improve text normalization by reducing words to their base or dictionary form, enhancing semantic understanding and contextual analysis. These methods often integrate machine learning models and linguistic rules to accurately identify and process morphological variations, boosting performance in tasks like information retrieval, sentiment analysis, and language translation. State-of-the-art lemmatizers utilize deep learning architectures such as transformers and sequence-to-sequence models, enabling more precise handling of complex language structures compared to traditional rule-based systems.
Use Cases: When to Choose Tokenization or Lemmatization
Tokenization is essential for breaking text into smaller units like words or phrases, making it ideal for tasks such as text classification, sentiment analysis, and language modeling where understanding sentence structure is crucial. Lemmatization, which reduces words to their base or dictionary form, is preferred in applications requiring semantic understanding, such as information retrieval, machine translation, and knowledge extraction. Choosing tokenization or lemmatization depends on the specific NLP task complexity and the need for either surface-level text segmentation or deeper linguistic normalization.
Future Trends in Text Preprocessing for Artificial Intelligence
Tokenization and lemmatization will evolve with deep learning advancements, enabling more context-aware and precise text segmentation and normalization. Emerging techniques like subword tokenization and dynamic lemmatization models will improve handling of multilingual and domain-specific datasets. Future text preprocessing pipelines will integrate these methods to enhance semantic understanding and boost AI-driven natural language processing accuracy.
Tokenization vs Lemmatization Infographic