Feature importance measures how much each variable contributes to a predictive model's accuracy, offering insights into which features drive predictions. Feature correlation identifies the statistical relationships between features, revealing dependencies and potential multicollinearity issues. Understanding the distinction helps optimize feature selection and improve model interpretability in data science projects.
Table of Comparison
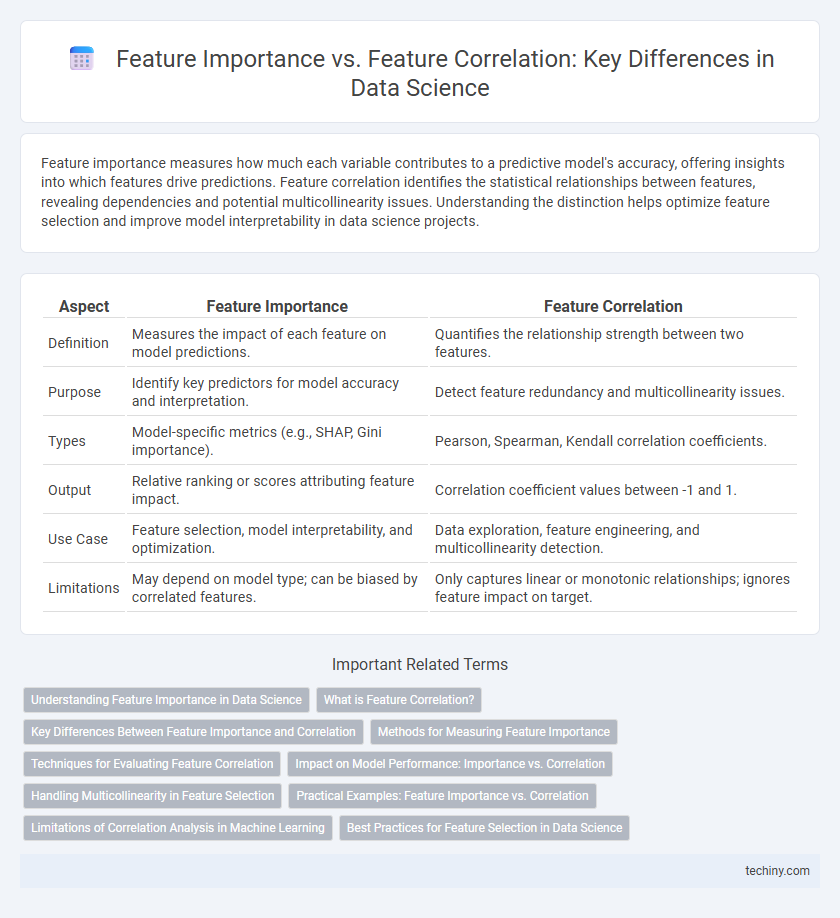
| Aspect | Feature Importance | Feature Correlation |
|---|---|---|
| Definition | Measures the impact of each feature on model predictions. | Quantifies the relationship strength between two features. |
| Purpose | Identify key predictors for model accuracy and interpretation. | Detect feature redundancy and multicollinearity issues. |
| Types | Model-specific metrics (e.g., SHAP, Gini importance). | Pearson, Spearman, Kendall correlation coefficients. |
| Output | Relative ranking or scores attributing feature impact. | Correlation coefficient values between -1 and 1. |
| Use Case | Feature selection, model interpretability, and optimization. | Data exploration, feature engineering, and multicollinearity detection. |
| Limitations | May depend on model type; can be biased by correlated features. | Only captures linear or monotonic relationships; ignores feature impact on target. |
Understanding Feature Importance in Data Science
Feature importance quantifies the contribution of each variable to a predictive model's accuracy, whereas feature correlation measures the linear relationship between variables regardless of the target. Understanding feature importance involves techniques such as permutation importance, SHAP values, and tree-based feature attribution, which provide insights into model behavior and guide feature selection. This distinction is crucial for building interpretable models and improving predictive performance by prioritizing impactful features over merely correlated ones.
What is Feature Correlation?
Feature correlation measures the statistical relationship between two variables, indicating how one feature may change in relation to another within a dataset. It is quantified using metrics such as Pearson's correlation coefficient, which captures linear dependencies between continuous features. Understanding feature correlation helps identify multicollinearity issues and informs feature selection in machine learning models.
Key Differences Between Feature Importance and Correlation
Feature importance measures how much a feature contributes to a predictive model's accuracy, often derived from machine learning algorithms like random forests or gradient boosting. Feature correlation quantifies the linear relationship between two variables, typically using statistical metrics such as Pearson's correlation coefficient. Unlike correlation, feature importance captures both linear and nonlinear dependencies and directly reflects the impact of features on model performance.
Methods for Measuring Feature Importance
Feature importance in data science is commonly measured using methods such as permutation importance, SHAP (SHapley Additive exPlanations), and feature importance scores derived from tree-based models like Random Forest and Gradient Boosting. These techniques evaluate the impact of each feature on the model's predictive performance, unlike feature correlation which only measures linear relationships between variables. Permutation importance assesses the increase in model error after shuffling a feature's values, while SHAP values provide a consistent and locally accurate attribution of feature contributions for individual predictions.
Techniques for Evaluating Feature Correlation
Techniques for evaluating feature correlation in data science include Pearson correlation, Spearman rank correlation, and Kendall tau correlation, each measuring different aspects of linear or monotonic relationships between variables. Mutual information provides a non-linear dependency measure that captures more complex associations beyond simple correlations. Visual tools like heatmaps and scatter plots complement these techniques by offering intuitive insights into feature relationships, facilitating better feature selection and model interpretability.
Impact on Model Performance: Importance vs. Correlation
Feature importance directly measures the impact of individual variables on model predictions, reflecting how much each feature contributes to reducing error in algorithms like random forests or gradient boosting. In contrast, feature correlation indicates the linear relationship between features and the target, but high correlation does not guarantee significant improvement in model performance, especially for complex, non-linear models. Prioritizing feature importance helps identify truly predictive variables that enhance accuracy and robustness, whereas relying solely on correlation may overlook subtle but influential features.
Handling Multicollinearity in Feature Selection
Handling multicollinearity in feature selection requires distinguishing between feature importance and feature correlation, as highly correlated features can distort model interpretation and reduce performance. Techniques like variance inflation factor (VIF) and regularization methods such as Lasso help identify and penalize redundant features, ensuring the selection of truly influential variables. Prioritizing feature importance over mere correlation enhances model robustness and accuracy by eliminating multicollinearity-related bias.
Practical Examples: Feature Importance vs. Correlation
Feature importance in data science quantifies the contribution of each feature to a predictive model's accuracy, often determined through methods like permutation importance or SHAP values. Feature correlation measures the statistical relationship between variables, highlighting linear or nonlinear associations but not directly attributing predictive power. For example, a feature with high correlation to the target may have low feature importance if redundant with other features, while a feature with low correlation can exhibit high importance due to interactions captured by complex models.
Limitations of Correlation Analysis in Machine Learning
Correlation analysis measures the linear relationship between features but fails to capture complex, nonlinear interactions critical in machine learning models. It cannot identify causal effects or feature interactions that significantly impact model performance, leading to potential misinterpretation of feature importance. Relying solely on correlation may result in overlooking valuable predictive features or including redundant variables, impairing model accuracy and interpretability.
Best Practices for Feature Selection in Data Science
Feature importance often provides a more reliable measure than feature correlation for selecting predictors in data science, as it captures nonlinear relationships and interactions within models like random forests or gradient boosting. Relying solely on feature correlation can lead to overlooking important variables that exhibit weak linear relationships but are crucial in complex predictive patterns. Combining feature importance analysis with correlation checks and domain knowledge ensures robust feature selection, reduces multicollinearity, and enhances model interpretability and performance.
feature importance vs feature correlation Infographic