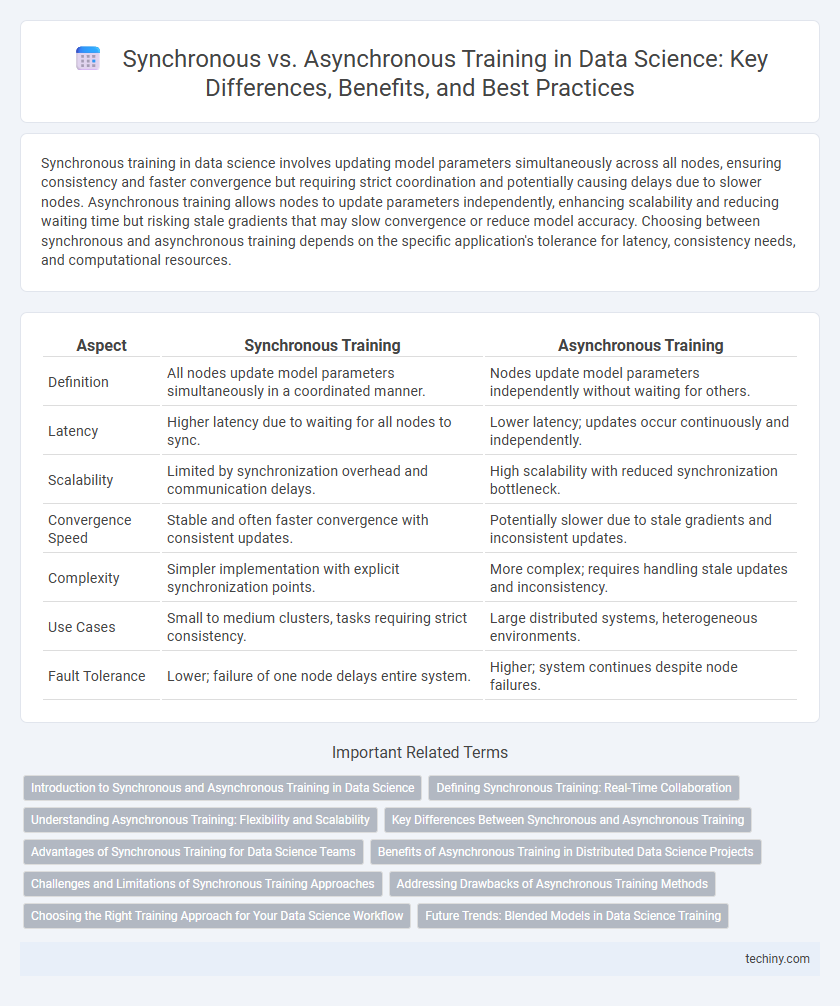
Synchronous training in data science involves updating model parameters simultaneously across all nodes, ensuring consistency and faster convergence but requiring strict coordination and potentially causing delays due to slower nodes. Asynchronous training allows nodes to update parameters independently, enhancing scalability and reducing waiting time but risking stale gradients that may slow convergence or reduce model accuracy. Choosing between synchronous and asynchronous training depends on the specific application's tolerance for latency, consistency needs, and computational resources.
Table of Comparison
| Aspect | Synchronous Training | Asynchronous Training |
|---|---|---|
| Definition | All nodes update model parameters simultaneously in a coordinated manner. | Nodes update model parameters independently without waiting for others. |
| Latency | Higher latency due to waiting for all nodes to sync. | Lower latency; updates occur continuously and independently. |
| Scalability | Limited by synchronization overhead and communication delays. | High scalability with reduced synchronization bottleneck. |
| Convergence Speed | Stable and often faster convergence with consistent updates. | Potentially slower due to stale gradients and inconsistent updates. |
| Complexity | Simpler implementation with explicit synchronization points. | More complex; requires handling stale updates and inconsistency. |
| Use Cases | Small to medium clusters, tasks requiring strict consistency. | Large distributed systems, heterogeneous environments. |
| Fault Tolerance | Lower; failure of one node delays entire system. | Higher; system continues despite node failures. |
Introduction to Synchronous and Asynchronous Training in Data Science
Synchronous training in data science involves simultaneous updates of model parameters across multiple nodes, ensuring consistent gradient aggregation during each training iteration. Asynchronous training allows individual nodes to update parameters independently without waiting for others, enabling faster computations but potentially introducing stale gradients. Balancing the trade-offs between synchronization overhead and model convergence speed is crucial for optimizing distributed machine learning workflows.
Defining Synchronous Training: Real-Time Collaboration
Synchronous training in data science involves real-time collaboration where multiple models or nodes update parameters simultaneously during each iteration. This approach ensures model consistency by aggregating gradients across all participants for every training step, reducing the risk of stale updates. Real-time synchronization often improves convergence speed but requires higher communication overhead and tightly-coupled infrastructure.
Understanding Asynchronous Training: Flexibility and Scalability
Asynchronous training in data science allows individual workers or nodes to update model parameters independently without waiting for synchronization, enhancing flexibility in distributed systems. This method improves scalability by enabling efficient resource utilization and reducing idle time caused by slower nodes, also known as stragglers. It is particularly advantageous in large-scale machine learning tasks where diverse hardware capabilities and network latencies are common.
Key Differences Between Synchronous and Asynchronous Training
Synchronous training in data science involves updating model parameters simultaneously across all nodes, ensuring consistent weight synchronization but often resulting in higher latency due to waiting for all nodes to complete their tasks. Asynchronous training allows nodes to update parameters independently without waiting for others, which speeds up training times but can introduce stale gradients and potential model divergence. The key difference lies in the trade-off between consistency and speed, where synchronous training prioritizes model accuracy and consistency, while asynchronous training focuses on faster convergence with potential variability in parameter updates.
Advantages of Synchronous Training for Data Science Teams
Synchronous training enhances model accuracy by ensuring all nodes update simultaneously, leading to consistent gradient aggregation and reduced variance in parameter updates. It facilitates easier debugging and monitoring, as each training step is synchronized across data science teams, improving collaboration and reproducibility. This approach also minimizes stale gradient issues, accelerating convergence and improving overall model performance in distributed machine learning environments.
Benefits of Asynchronous Training in Distributed Data Science Projects
Asynchronous training in distributed data science projects enhances scalability by allowing worker nodes to process data and update models independently, reducing idle time caused by synchronization barriers. This method improves fault tolerance, as the system continues functioning smoothly even if some nodes experience delays or failures. It also accelerates convergence in heterogeneous environments by accommodating variable computation speeds across different nodes, leading to more efficient utilization of resources.
Challenges and Limitations of Synchronous Training Approaches
Synchronous training faces significant challenges including communication overhead and synchronization delays, which increase as the number of distributed nodes grows. This approach often leads to idle waiting times as faster nodes must wait for slower ones, causing inefficiencies and slower convergence rates. Furthermore, it is less resilient to node failures, as the entire system may stall if one node encounters issues, limiting scalability in large-scale data science projects.
Addressing Drawbacks of Asynchronous Training Methods
Asynchronous training methods in data science often face challenges such as stale gradients and inconsistent model updates, which can slow convergence and reduce accuracy. Techniques like gradient staleness compensation and adaptive learning rates have been developed to mitigate these issues by aligning delayed updates and improving synchronization among distributed nodes. Implementing these solutions enhances model performance and stability while maintaining the scalability benefits of asynchronous training architectures.
Choosing the Right Training Approach for Your Data Science Workflow
Choosing between synchronous and asynchronous training in data science hinges on balancing model convergence speed and hardware utilization efficiency. Synchronous training ensures consistent updates by aggregating gradients across all nodes simultaneously, enhancing model accuracy but requiring significant synchronization overhead. Asynchronous training improves resource utilization and scalability by allowing individual nodes to update weights independently, though it may introduce staleness in gradients affecting convergence stability.
Future Trends: Blended Models in Data Science Training
Blended models in data science training are emerging as the future trend by integrating synchronous training's real-time collaboration with the flexibility and scalability of asynchronous methods. These hybrid approaches leverage cloud-based platforms and AI-driven personalization to optimize learning outcomes and accommodate diverse learner needs. The adoption of blended training models is expected to enhance engagement, improve skill retention, and accelerate proficiency development in complex data science domains.
Synchronous Training vs Asynchronous Training Infographic