Aggregation in data science involves summarizing detailed data points into a broader overview, enabling easier analysis and trend identification. Granularity refers to the level of detail or depth in the dataset, where finer granularity provides more specific information but may require more complex processing. Balancing aggregation and granularity is crucial for optimizing data insights while maintaining computational efficiency.
Table of Comparison
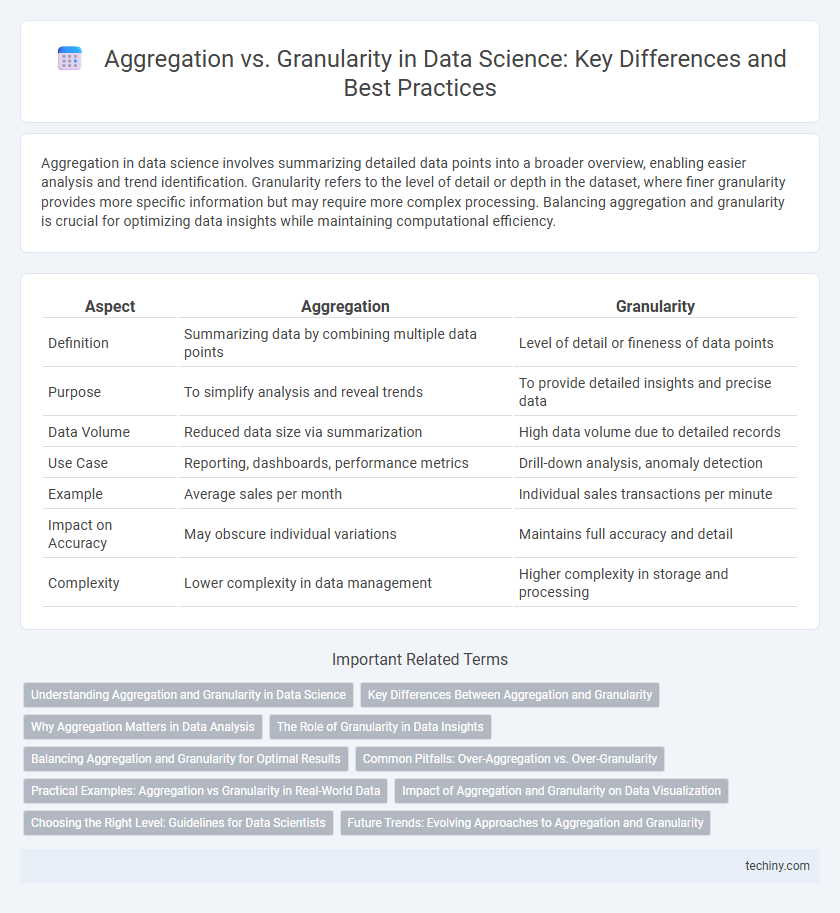
| Aspect | Aggregation | Granularity |
|---|---|---|
| Definition | Summarizing data by combining multiple data points | Level of detail or fineness of data points |
| Purpose | To simplify analysis and reveal trends | To provide detailed insights and precise data |
| Data Volume | Reduced data size via summarization | High data volume due to detailed records |
| Use Case | Reporting, dashboards, performance metrics | Drill-down analysis, anomaly detection |
| Example | Average sales per month | Individual sales transactions per minute |
| Impact on Accuracy | May obscure individual variations | Maintains full accuracy and detail |
| Complexity | Lower complexity in data management | Higher complexity in storage and processing |
Understanding Aggregation and Granularity in Data Science
Aggregation in data science refers to the process of summarizing detailed data into higher-level insights by combining multiple data points, often using functions like sum, average, or count. Granularity defines the level of detail or precision in the dataset, where finer granularity means more specific, detailed records and coarser granularity indicates broader, summarized data. Balancing aggregation and granularity is crucial for effective data analysis, as it impacts the accuracy, interpretability, and performance of analytical models.
Key Differences Between Aggregation and Granularity
Aggregation in data science involves summarizing detailed data into higher-level insights by combining multiple data points, often through functions like sum, average, or count. Granularity refers to the level of detail or scale at which data is captured, ranging from fine (individual transactions) to coarse (monthly summaries). Key differences include aggregation reducing data detail to reveal trends while granularity defines the original data's resolution and can influence the choice of aggregation methods for accurate analysis.
Why Aggregation Matters in Data Analysis
Aggregation matters in data analysis because it simplifies large datasets into meaningful summaries, enabling clearer insights and faster decision-making. By reducing granularity, analysts can identify overarching patterns and trends without being overwhelmed by noise or variability in individual data points. This process enhances the efficiency of algorithms and supports scalable analysis across diverse data sources and structures.
The Role of Granularity in Data Insights
Granularity determines the level of detail present in a dataset, directly impacting the precision of data insights in data science. High granularity allows for more nuanced analysis by capturing fine distinctions, enabling targeted decision-making and personalized solutions. Aggregated data, while useful for identifying broad trends, often sacrifices this specificity, limiting the depth of insights derived from complex datasets.
Balancing Aggregation and Granularity for Optimal Results
Balancing aggregation and granularity in data science involves selecting the appropriate level of detail to maintain analytical accuracy while enhancing computational efficiency. Excessive aggregation can obscure critical insights by oversimplifying data patterns, whereas too much granularity may introduce noise and increase processing time without substantial benefit. Optimal results are achieved by tailoring data aggregation levels to the specific objectives and complexity of the dataset, leveraging techniques such as hierarchical clustering and multi-resolution analysis.
Common Pitfalls: Over-Aggregation vs. Over-Granularity
Over-aggregation in data science can obscure critical insights by merging diverse data points into overly broad summaries, leading to loss of detail and potential misinterpretation. Over-granularity, on the other hand, results in excessively detailed datasets that complicate analysis, increase noise, and reduce computational efficiency. Balancing aggregation and granularity is essential to preserve meaningful patterns while maintaining actionable clarity in data-driven decision-making.
Practical Examples: Aggregation vs Granularity in Real-World Data
Aggregation in data science involves summarizing detailed data points into higher-level metrics such as averages, sums, or counts, enabling easier trend analysis across large datasets like sales totals per region. Granularity refers to the level of detail or depth in data, exemplified by transaction-level records that capture individual customer purchases with timestamps and product details. Balancing aggregation and granularity is essential for effective decision-making, where detailed granular data supports granular insights and aggregation helps identify broader patterns in sectors like retail analytics or sensor data monitoring.
Impact of Aggregation and Granularity on Data Visualization
Aggregation reduces data complexity by summarizing detailed information into broader categories, enhancing clarity in visualizations but potentially obscuring important nuances. Granularity refers to the level of detail in data, where finer granularity offers deeper insights but can overwhelm visual representations with noise. Balancing aggregation and granularity is critical to creating data visualizations that are both interpretable and rich in actionable information.
Choosing the Right Level: Guidelines for Data Scientists
Data scientists must balance aggregation and granularity to optimize data analysis outcomes, selecting the appropriate level based on the research question and dataset complexity. Aggregated data simplifies patterns by summarizing large datasets, while granular data offers detailed insights necessary for precise modeling and anomaly detection. Effective guideline implementation includes evaluating task objectives, computational resources, and the impact on model accuracy to ensure the chosen data granularity aligns with analytic goals.
Future Trends: Evolving Approaches to Aggregation and Granularity
Future trends in data science emphasize dynamic aggregation techniques leveraging machine learning to optimize granularity levels in real-time, enhancing predictive analytics accuracy. Advances in automated feature engineering and adaptive data summarization enable systems to balance detailed insights with computational efficiency across diverse datasets. Emerging frameworks integrate hierarchical and multi-resolution data models, supporting scalable analysis tailored to complex, evolving big data environments.
Aggregation vs Granularity Infographic