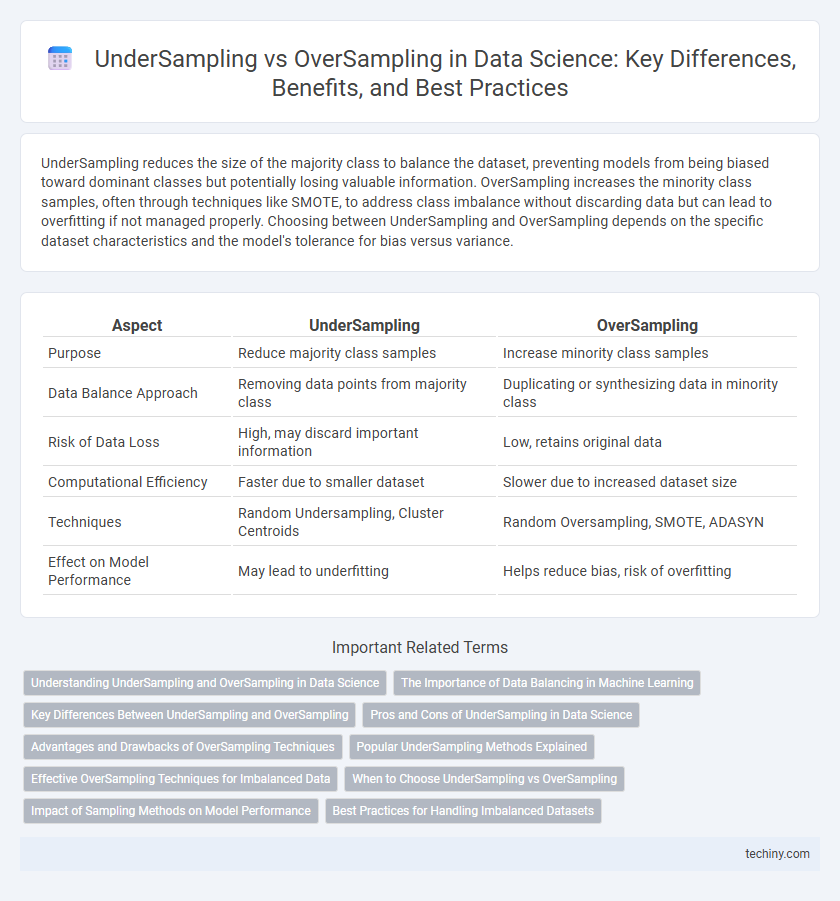
UnderSampling reduces the size of the majority class to balance the dataset, preventing models from being biased toward dominant classes but potentially losing valuable information. OverSampling increases the minority class samples, often through techniques like SMOTE, to address class imbalance without discarding data but can lead to overfitting if not managed properly. Choosing between UnderSampling and OverSampling depends on the specific dataset characteristics and the model's tolerance for bias versus variance.
Table of Comparison
| Aspect | UnderSampling | OverSampling |
|---|---|---|
| Purpose | Reduce majority class samples | Increase minority class samples |
| Data Balance Approach | Removing data points from majority class | Duplicating or synthesizing data in minority class |
| Risk of Data Loss | High, may discard important information | Low, retains original data |
| Computational Efficiency | Faster due to smaller dataset | Slower due to increased dataset size |
| Techniques | Random Undersampling, Cluster Centroids | Random Oversampling, SMOTE, ADASYN |
| Effect on Model Performance | May lead to underfitting | Helps reduce bias, risk of overfitting |
Understanding UnderSampling and OverSampling in Data Science
UnderSampling reduces the majority class instances to balance dataset distribution, effectively preventing model bias but risking information loss from discarded data. OverSampling increases minority class samples by replicating or synthetically generating new instances, enhancing model performance on rare classes while potentially causing overfitting. Selecting between UnderSampling and OverSampling depends on dataset size, class imbalance severity, and the specific machine learning algorithm's sensitivity to data distribution.
The Importance of Data Balancing in Machine Learning
Data balancing in machine learning addresses class imbalance by using techniques such as undersampling and oversampling to ensure equal representation of minority and majority classes, which improves model accuracy and reduces bias. Undersampling removes samples from the majority class to prevent dominance, while oversampling duplicates or generates synthetic data points for the minority class to boost its presence. Implementing these balancing methods enhances model generalization, reduces overfitting, and leads to more reliable predictions in imbalanced datasets.
Key Differences Between UnderSampling and OverSampling
UnderSampling reduces the size of the majority class to balance datasets, which helps prevent model bias but can discard potentially valuable information. OverSampling increases the minority class size by replicating or generating synthetic samples, preserving all original data while addressing class imbalance. Key differences include the risk of information loss in UnderSampling versus the potential for overfitting in OverSampling due to duplicated or synthetic data.
Pros and Cons of UnderSampling in Data Science
UnderSampling reduces dataset size by removing majority class samples, which decreases training time and mitigates class imbalance, but risks losing important information and causing underfitting. It is computationally efficient and useful for large datasets where majority class dominance skews model performance. However, excessive undersampling can lead to lower predictive accuracy due to insufficient data representation from the majority class.
Advantages and Drawbacks of OverSampling Techniques
OverSampling techniques in data science enhance model performance by balancing class distribution, improving minority class recognition and reducing bias. However, these methods may introduce overfitting and synthetic data noise, potentially harming model generalization. Careful tuning and validation are essential to maximize OverSampling benefits while minimizing its drawbacks.
Popular UnderSampling Methods Explained
Popular undersampling methods in data science include Random Undersampling, which reduces the majority class by randomly removing samples to balance the dataset, and Tomek Links, which identify and eliminate overlapping instances near class boundaries to improve classifier performance. Edited Nearest Neighbors (ENN) removes majority class examples that differ from their nearest neighbors, enhancing class separation and reducing noise. These techniques help address class imbalance by minimizing bias while maintaining important data characteristics for effective model training.
Effective OverSampling Techniques for Imbalanced Data
Effective oversampling techniques for imbalanced data in data science include Synthetic Minority Over-sampling Technique (SMOTE), Adaptive Synthetic (ADASYN), and Borderline-SMOTE, which generate synthetic samples to enhance the minority class representation. These methods improve model performance by addressing class imbalance without simply duplicating existing samples, reducing overfitting risks. Integration of oversampling with ensemble learning or feature selection techniques further optimizes predictive accuracy on minority classes.
When to Choose UnderSampling vs OverSampling
UnderSampling is ideal when dealing with large datasets where reducing the majority class can significantly speed up model training without losing critical information. OverSampling is preferred when preserving all existing data is crucial, especially in small datasets, by synthetically generating minority class examples to balance class distribution. The choice depends on dataset size, computational resources, and the risk of overfitting or information loss.
Impact of Sampling Methods on Model Performance
Undersampling reduces the majority class size to balance imbalanced datasets, which can decrease training time but may lead to loss of important information, affecting model generalization negatively. Oversampling techniques like SMOTE generate synthetic minority class samples, improving model performance by addressing class imbalance without discarding data but risking overfitting. Choosing between undersampling and oversampling depends on the dataset size and model sensitivity, as both methods significantly influence classification accuracy and recall metrics.
Best Practices for Handling Imbalanced Datasets
UnderSampling reduces the majority class size to balance the dataset but risks losing valuable information, making it suitable for large datasets with significant imbalance. OverSampling increases the minority class examples, often through techniques like SMOTE, which generates synthetic samples to enhance model performance without discarding data. Combining both methods or using ensemble techniques can improve classification accuracy and mitigate bias in imbalanced datasets.
UnderSampling vs OverSampling Infographic