JSON files are human-readable and widely used for data interchange but tend to be inefficient for large-scale data processing due to their verbose structure and lack of compression. Parquet is a columnar storage file format optimized for big data analytics, offering efficient compression and faster query performance by enabling selective data reading. Choosing Parquet over JSON significantly enhances storage efficiency and accelerates data processing workflows in data science projects.
Table of Comparison
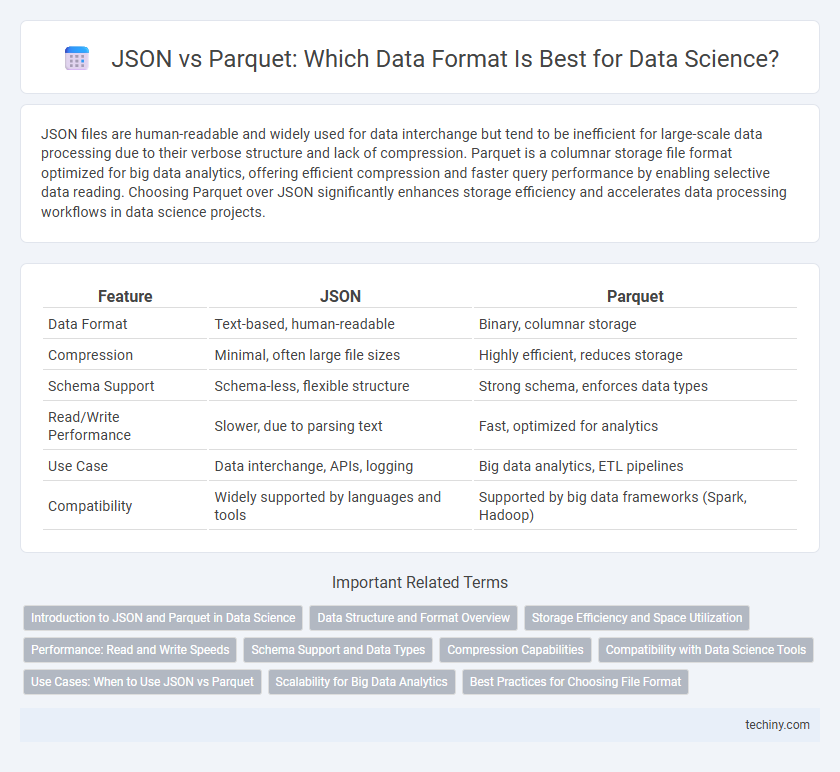
| Feature | JSON | Parquet |
|---|---|---|
| Data Format | Text-based, human-readable | Binary, columnar storage |
| Compression | Minimal, often large file sizes | Highly efficient, reduces storage |
| Schema Support | Schema-less, flexible structure | Strong schema, enforces data types |
| Read/Write Performance | Slower, due to parsing text | Fast, optimized for analytics |
| Use Case | Data interchange, APIs, logging | Big data analytics, ETL pipelines |
| Compatibility | Widely supported by languages and tools | Supported by big data frameworks (Spark, Hadoop) |
Introduction to JSON and Parquet in Data Science
JSON (JavaScript Object Notation) is a lightweight, flexible data interchange format widely used for data representation and transmission in data science due to its human-readable structure and compatibility with various programming languages. Parquet is a columnar storage file format optimized for big data processing and analytics, providing efficient data compression and encoding schemes that significantly improve performance in data science workflows. Both formats serve distinct purposes, with JSON excelling in data interchange and Parquet enhancing storage efficiency and query speed in large-scale data analysis.
Data Structure and Format Overview
JSON is a lightweight, text-based data format ideal for semi-structured data with human-readable key-value pairs, often used for data interchange and storage of nested objects. Parquet is a columnar storage file format designed for efficient data compression and encoding, optimized for analytical querying and large-scale data processing. The row-oriented structure of JSON contrasts with Parquet's columnar format, which significantly improves performance in read-heavy workloads and big data environments.
Storage Efficiency and Space Utilization
Parquet format offers superior storage efficiency compared to JSON by using columnar storage and advanced compression techniques, significantly reducing disk space usage for large datasets. JSON files are verbose and store data as plain text, leading to larger file sizes and higher storage costs. Parquet's optimized space utilization makes it ideal for large-scale data processing in data science workflows requiring fast read and write operations.
Performance: Read and Write Speeds
Parquet files offer significantly faster read and write speeds compared to JSON due to their columnar storage format, which enables efficient data compression and retrieval. JSON's row-based, text format leads to slower processing times and higher I/O costs, especially with large datasets. In big data environments, leveraging Parquet improves query performance and reduces latency during data analysis workflows.
Schema Support and Data Types
Parquet offers robust schema support with a strict, columnar storage format enabling efficient data compression and encoding, which improves performance in large-scale data processing. JSON, being a flexible text-based format, supports dynamic and complex data structures but lacks explicit schema enforcement, often leading to inconsistent data types and increased parsing overhead. In data science workflows, Parquet's explicit schema and rich data types, including nested structures, enhance reliability and speed in analytical queries compared to the loosely-typed nature of JSON.
Compression Capabilities
Parquet offers superior compression capabilities compared to JSON by utilizing columnar storage and advanced encoding techniques, resulting in significantly reduced file sizes and faster query performance. JSON's text-based format lacks efficient compression, leading to larger storage requirements and slower processing speeds. Data scientists prefer Parquet for big data applications where optimized storage and retrieval are critical.
Compatibility with Data Science Tools
JSON files are widely compatible with data science tools due to their human-readable format and support across programming languages like Python, R, and JavaScript. Parquet files, optimized for big data analytics, offer seamless integration with frameworks such as Apache Spark, Hadoop, and cloud-based solutions, providing efficient columnar storage and faster query performance. Data scientists often prefer Parquet for large-scale data processing tasks, while JSON is favored for lightweight, flexible data interchange and easy debugging.
Use Cases: When to Use JSON vs Parquet
JSON is ideal for data interchange in web applications and scenarios requiring human-readable formats, supporting flexible and nested structures but with larger file sizes and slower processing. Parquet excels in big data analytics and storage, offering efficient columnar compression and faster query performance for large datasets in data warehouses or processing frameworks like Apache Spark. Choose JSON for lightweight, schema-less data exchange and Parquet for optimized storage and high-performance analytics on structured data.
Scalability for Big Data Analytics
Parquet offers superior scalability for big data analytics compared to JSON due to its columnar storage format, which significantly reduces I/O and speeds up query performance on large datasets. JSON's text-based, row-oriented structure leads to higher storage overhead and slower processing times, making it less efficient for handling massive volumes of data. Optimized for distributed systems like Hadoop and Spark, Parquet supports efficient compression and encoding, enabling faster, scalable analytics pipelines essential for big data environments.
Best Practices for Choosing File Format
Choosing between JSON and Parquet file formats depends on data structure and processing needs, where JSON suits semi-structured, human-readable data while Parquet excels in efficient storage and query performance for large-scale analytics. Best practices recommend using Parquet for big data workflows due to its columnar storage and compression capabilities, which reduce I/O and improve speed in distributed computing frameworks like Apache Spark. For scenarios requiring flexibility and ease of ingestion, JSON remains valuable, but optimizing for performance and storage scalability typically favors adopting Parquet format.
JSON vs Parquet Infographic