SMOTE (Synthetic Minority Over-sampling Technique) enhances imbalanced datasets by generating synthetic examples for the minority class, improving model performance on rare events. Undersampling reduces the majority class size to balance the dataset, which can sometimes lead to loss of valuable information. Choosing between SMOTE and undersampling depends on the specific dataset characteristics and the trade-off between preserving data diversity and addressing class imbalance effectively.
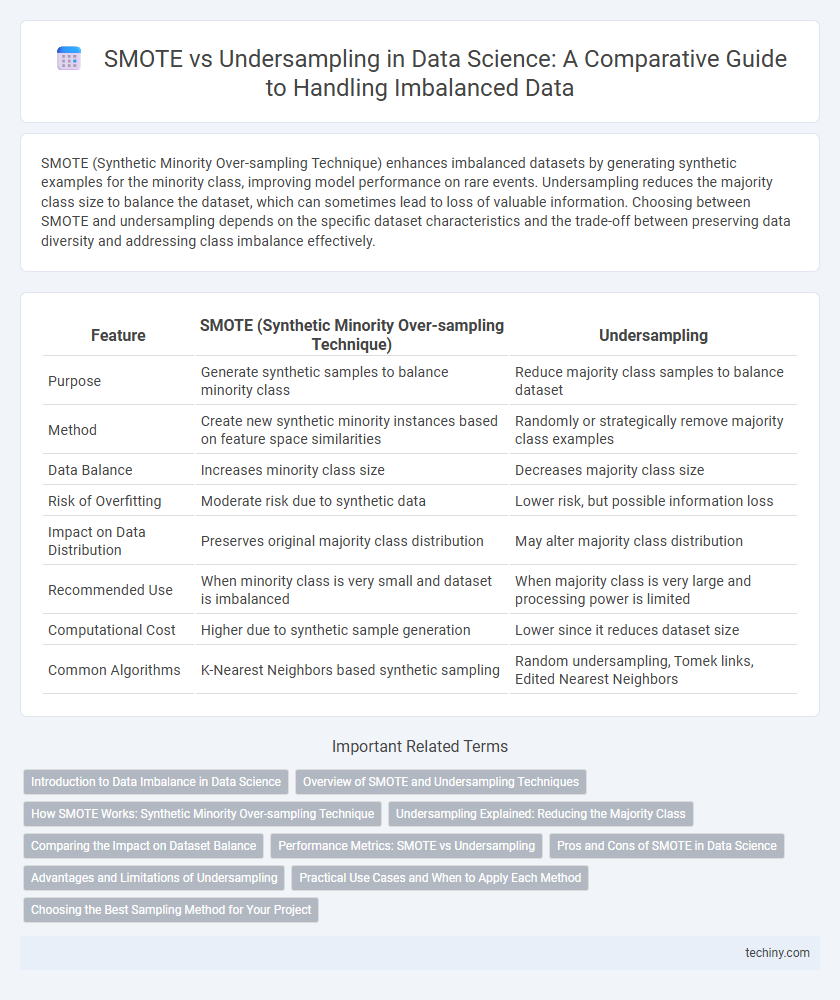
Table of Comparison
| Feature | SMOTE (Synthetic Minority Over-sampling Technique) | Undersampling |
|---|---|---|
| Purpose | Generate synthetic samples to balance minority class | Reduce majority class samples to balance dataset |
| Method | Create new synthetic minority instances based on feature space similarities | Randomly or strategically remove majority class examples |
| Data Balance | Increases minority class size | Decreases majority class size |
| Risk of Overfitting | Moderate risk due to synthetic data | Lower risk, but possible information loss |
| Impact on Data Distribution | Preserves original majority class distribution | May alter majority class distribution |
| Recommended Use | When minority class is very small and dataset is imbalanced | When majority class is very large and processing power is limited |
| Computational Cost | Higher due to synthetic sample generation | Lower since it reduces dataset size |
| Common Algorithms | K-Nearest Neighbors based synthetic sampling | Random undersampling, Tomek links, Edited Nearest Neighbors |
Introduction to Data Imbalance in Data Science
Data imbalance in data science occurs when certain classes in a dataset are underrepresented, leading to biased model performance. SMOTE (Synthetic Minority Over-sampling Technique) addresses this issue by generating synthetic samples for minority classes, enhancing model generalization. Undersampling reduces the size of majority classes to balance the dataset but may discard valuable information, impacting model accuracy.
Overview of SMOTE and Undersampling Techniques
SMOTE (Synthetic Minority Over-sampling Technique) generates synthetic samples for minority classes to address class imbalance, improving classifier performance by creating more balanced datasets. Undersampling reduces the majority class size by randomly removing samples, which can lead to loss of information but decreases training time and mitigates bias toward the majority class. Both techniques are essential in data preprocessing for imbalanced datasets, with SMOTE preferred for preserving information and undersampling useful for large-scale data where computational efficiency is critical.
How SMOTE Works: Synthetic Minority Over-sampling Technique
SMOTE works by generating synthetic samples for the minority class through interpolation between existing minority class instances, effectively increasing data diversity and reducing class imbalance. It selects k-nearest neighbors of a minority class sample and creates new examples along the line segments joining those neighbors, enhancing classifier performance on imbalanced datasets. Compared to undersampling, which reduces majority class samples and risks information loss, SMOTE enriches minority class representation without discarding valuable data.
Undersampling Explained: Reducing the Majority Class
Undersampling reduces the majority class by selectively removing samples to balance class distribution, aiming to prevent model bias in imbalanced datasets. This technique helps improve classifier performance by ensuring equal representation without artificially generating new data points, unlike SMOTE which creates synthetic minority samples. Effective undersampling methods include random undersampling and cluster-based approaches, which maintain data integrity while addressing class imbalance.
Comparing the Impact on Dataset Balance
SMOTE (Synthetic Minority Over-sampling Technique) generates synthetic samples to balance imbalanced datasets by increasing minority class instances, enhancing model generalization without reducing data volume. Undersampling reduces the majority class size, potentially leading to data loss and lower model performance but can speed up training times. Comparing impact, SMOTE maintains dataset size and feature space diversity better, while undersampling simplifies data but risks removing valuable majority class information.
Performance Metrics: SMOTE vs Undersampling
SMOTE enhances classifier performance by generating synthetic samples, improving metrics like recall and F1-score in imbalanced datasets. Undersampling reduces majority class size, often increasing precision but risking loss of critical information, which may lower overall accuracy. Selecting between SMOTE and undersampling depends on the specific performance metrics prioritized, such as maximizing recall for rare event detection or precision for reducing false positives.
Pros and Cons of SMOTE in Data Science
SMOTE (Synthetic Minority Over-sampling Technique) generates synthetic samples to address class imbalance, enhancing model performance on minority classes without losing valuable information. It can improve classifier accuracy and reduce bias but may introduce noise and increase overfitting risk due to synthetic data generation. Compared to undersampling, SMOTE preserves all original data while balancing classes, but requires more computational resources and careful parameter tuning.
Advantages and Limitations of Undersampling
Undersampling reduces class imbalance by eliminating majority class examples, which simplifies models and decreases training time, benefiting datasets with large class disparities. However, it risks discarding potentially valuable information, leading to loss of important patterns and decreased model performance, especially in complex data scenarios. Balancing efficiency and representativeness remains a key challenge when employing undersampling in data science tasks.
Practical Use Cases and When to Apply Each Method
SMOTE is ideal for datasets with moderate imbalance where generating synthetic minority class samples enhances model training without losing information, often benefiting fraud detection and medical diagnosis applications. Undersampling suits scenarios with large majority class datasets, such as large-scale customer churn prediction, where reducing majority samples accelerates training and mitigates overfitting. Choose SMOTE when minority class detail retention is critical; opt for undersampling when computation efficiency and simplicity are prioritized.
Choosing the Best Sampling Method for Your Project
When selecting a sampling method for imbalanced datasets in data science, SMOTE (Synthetic Minority Over-sampling Technique) generates synthetic examples to enhance minority class representation without losing valuable data, while undersampling removes majority class instances, potentially leading to information loss but faster processing times. The choice depends on dataset size, class distribution, and model sensitivity to overfitting; large datasets with complex patterns often benefit from SMOTE's balanced augmentation, whereas smaller datasets may require cautious undersampling to prevent overfitting or training bias. Evaluating model performance metrics such as F1-score, precision-recall curves, and computational efficiency can guide the optimal sampling strategy tailored to specific project goals.
SMOTE vs undersampling Infographic