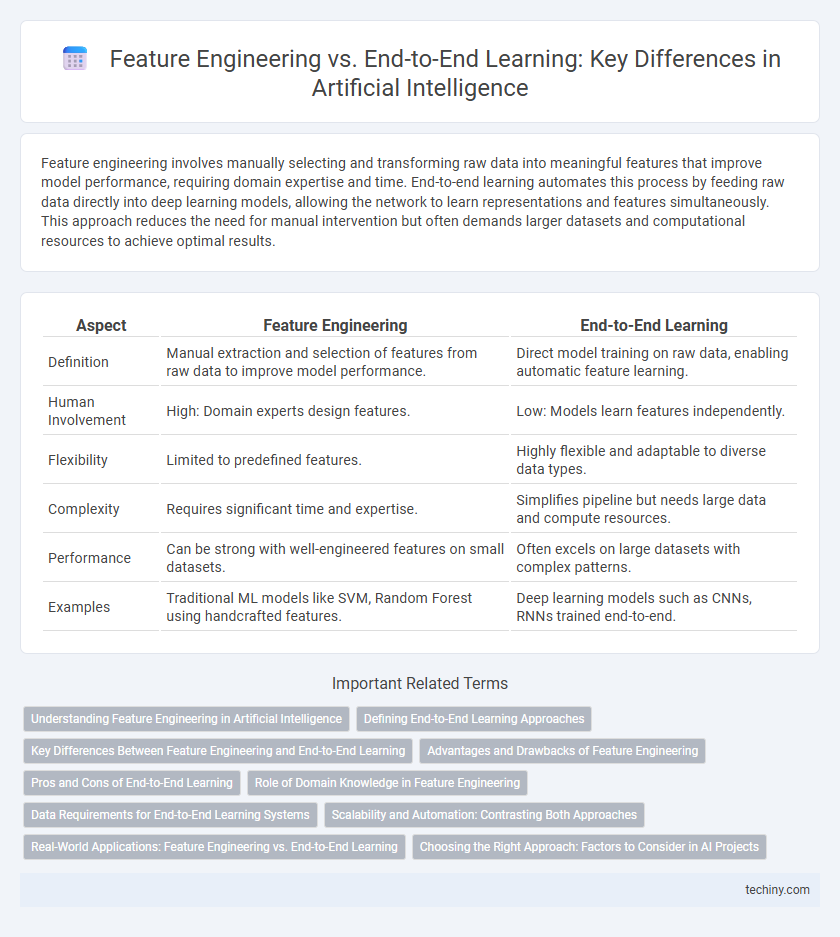
Feature engineering involves manually selecting and transforming raw data into meaningful features that improve model performance, requiring domain expertise and time. End-to-end learning automates this process by feeding raw data directly into deep learning models, allowing the network to learn representations and features simultaneously. This approach reduces the need for manual intervention but often demands larger datasets and computational resources to achieve optimal results.
Table of Comparison
| Aspect | Feature Engineering | End-to-End Learning |
|---|---|---|
| Definition | Manual extraction and selection of features from raw data to improve model performance. | Direct model training on raw data, enabling automatic feature learning. |
| Human Involvement | High: Domain experts design features. | Low: Models learn features independently. |
| Flexibility | Limited to predefined features. | Highly flexible and adaptable to diverse data types. |
| Complexity | Requires significant time and expertise. | Simplifies pipeline but needs large data and compute resources. |
| Performance | Can be strong with well-engineered features on small datasets. | Often excels on large datasets with complex patterns. |
| Examples | Traditional ML models like SVM, Random Forest using handcrafted features. | Deep learning models such as CNNs, RNNs trained end-to-end. |
Understanding Feature Engineering in Artificial Intelligence
Feature engineering in artificial intelligence involves manually selecting, transforming, and creating features from raw data to improve model performance, relying heavily on domain expertise and data understanding. This process enhances model interpretability and can significantly reduce training time by presenting cleaner, more informative inputs to algorithms. Effective feature engineering often results in improved accuracy and robustness compared to models that rely solely on raw data inputs.
Defining End-to-End Learning Approaches
End-to-end learning approaches in artificial intelligence involve training a single model to directly map raw input data to desired outputs without manually crafted feature extraction, enabling automatic feature representation learning. These methods leverage deep neural networks to optimize all stages simultaneously, reducing reliance on domain expertise and enhancing adaptability across diverse tasks. End-to-end learning contrasts with traditional feature engineering, which requires separate, task-specific preprocessing steps to design and select relevant data features.
Key Differences Between Feature Engineering and End-to-End Learning
Feature engineering involves manually selecting and transforming raw data into meaningful features to improve model performance, whereas end-to-end learning enables neural networks to automatically learn representations directly from raw inputs. Key differences include the reliance on domain expertise in feature engineering versus the requirement of large labeled datasets for end-to-end systems. Feature engineering often reduces model complexity and training time, while end-to-end learning excels in handling unstructured data like images and text with minimal human intervention.
Advantages and Drawbacks of Feature Engineering
Feature engineering enhances model interpretability and leverages domain expertise to create meaningful input features, often improving performance on structured data tasks. However, it requires significant manual effort, domain knowledge, and may introduce biases or overlook complex data relationships. In contrast, end-to-end learning automates feature extraction but may demand larger datasets and computational resources.
Pros and Cons of End-to-End Learning
End-to-end learning streamlines the AI development process by automatically extracting features directly from raw data, reducing the need for manual feature engineering and domain expertise. This approach excels in complex tasks like image and speech recognition where high-dimensional data benefits from deep neural networks' ability to learn hierarchical representations, improving generalization and adaptability. However, end-to-end learning requires large amounts of labeled data, intensive computational resources, and may lack interpretability compared to traditional feature-engineered models, posing challenges in transparency and debugging.
Role of Domain Knowledge in Feature Engineering
Feature engineering leverages domain knowledge to create meaningful input variables that enhance model performance by capturing relevant patterns and relationships specific to the problem context. This process requires expertise to identify and transform raw data into features that improve interpretability and reduce noise. In contrast, end-to-end learning models automatically extract features from raw data, relying less on domain expertise but often requiring larger datasets and more computational power.
Data Requirements for End-to-End Learning Systems
End-to-end learning systems demand vast amounts of high-quality, annotated data to effectively capture intricate patterns without manual feature extraction. These systems rely on raw, unprocessed inputs enabling models like deep neural networks to learn hierarchical representations directly. Consequently, the scalability and success of end-to-end learning heavily depend on the availability and diversity of comprehensive datasets such as ImageNet or large-scale text corpora.
Scalability and Automation: Contrasting Both Approaches
Feature engineering demands extensive manual intervention and domain expertise, limiting scalability and slowing automation in AI model development. End-to-end learning leverages deep neural networks to automatically extract features from raw data, enhancing scalability by reducing human involvement. This approach accelerates deployment across diverse datasets, making it more suitable for large-scale AI applications requiring continuous adaptation.
Real-World Applications: Feature Engineering vs. End-to-End Learning
Feature engineering requires domain expertise to manually select and transform raw data into meaningful input features, enhancing model interpretability and performance in applications like finance fraud detection and healthcare diagnostics. End-to-end learning automates feature extraction, enabling deep neural networks to learn hierarchical representations directly from raw data, which is advantageous in complex tasks such as image recognition and natural language processing. Real-world deployments often balance these approaches, leveraging feature engineering for structured data while employing end-to-end models for unstructured data scenarios.
Choosing the Right Approach: Factors to Consider in AI Projects
Choosing between feature engineering and end-to-end learning depends on factors such as the availability of labeled data, computational resources, and domain expertise. Feature engineering excels when domain knowledge is rich and data is limited, enabling tailored input representations to improve model interpretability and performance. End-to-end learning is preferable with large datasets and powerful hardware, as it automates feature extraction and can capture complex patterns without manual intervention.
Feature Engineering vs End-to-End Learning Infographic