Pruning reduces model complexity by removing less important neurons or weights, effectively slimming down neural networks to enhance inference speed and decrease memory usage. Quantization compresses model parameters by lowering the numerical precision of weights and activations, which significantly reduces model size and accelerates computation on compatible hardware. Both techniques optimize AI models for deployment, balancing performance with resource efficiency.
Table of Comparison
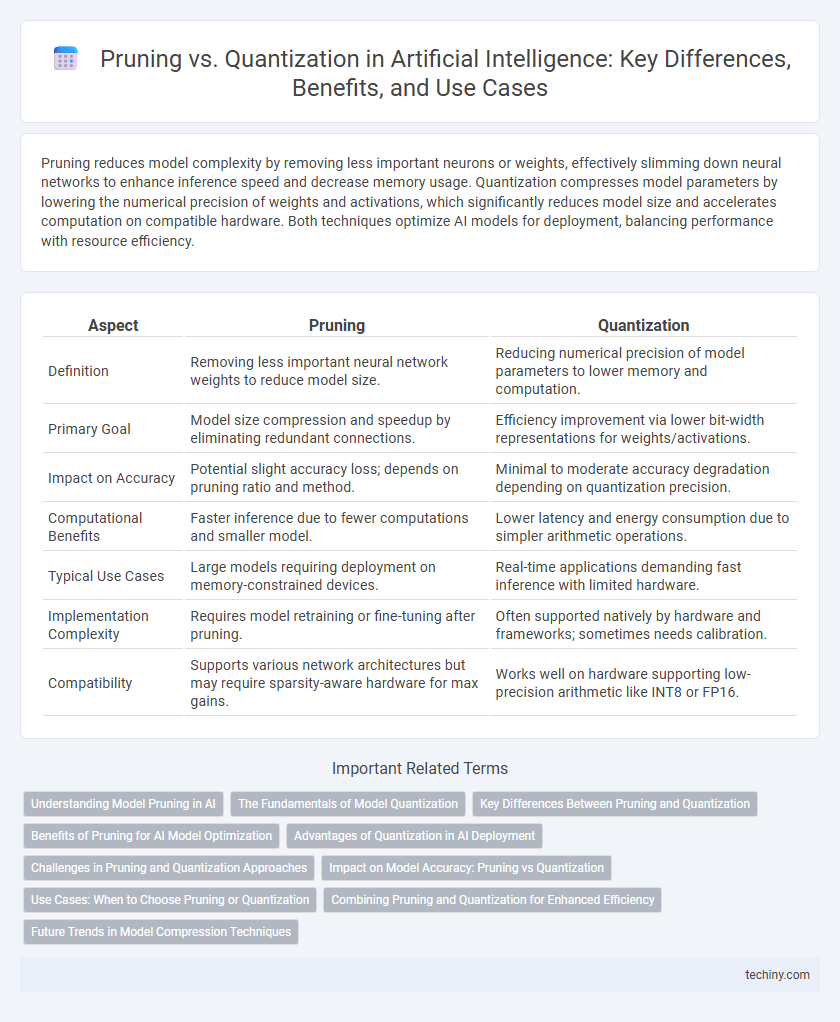
| Aspect | Pruning | Quantization |
|---|---|---|
| Definition | Removing less important neural network weights to reduce model size. | Reducing numerical precision of model parameters to lower memory and computation. |
| Primary Goal | Model size compression and speedup by eliminating redundant connections. | Efficiency improvement via lower bit-width representations for weights/activations. |
| Impact on Accuracy | Potential slight accuracy loss; depends on pruning ratio and method. | Minimal to moderate accuracy degradation depending on quantization precision. |
| Computational Benefits | Faster inference due to fewer computations and smaller model. | Lower latency and energy consumption due to simpler arithmetic operations. |
| Typical Use Cases | Large models requiring deployment on memory-constrained devices. | Real-time applications demanding fast inference with limited hardware. |
| Implementation Complexity | Requires model retraining or fine-tuning after pruning. | Often supported natively by hardware and frameworks; sometimes needs calibration. |
| Compatibility | Supports various network architectures but may require sparsity-aware hardware for max gains. | Works well on hardware supporting low-precision arithmetic like INT8 or FP16. |
Understanding Model Pruning in AI
Model pruning in AI involves reducing the number of parameters in a neural network by selectively removing less important neurons or connections to improve efficiency without severely impacting accuracy. This technique helps decrease model size and computational requirements, making deployment on edge devices more feasible. Pruning methods vary from structured to unstructured, with structured pruning providing hardware-friendly model compression.
The Fundamentals of Model Quantization
Model quantization reduces the precision of neural network weights and activations from floating-point to lower bit-width representations such as int8 or int16, significantly decreasing model size and improving inference speed. This process maintains acceptable accuracy by carefully calibrating quantized values, often using post-training quantization or quantization-aware training techniques. Quantization is especially effective in deploying AI models on edge devices with limited computational resources, enabling efficient performance without incurring high power consumption.
Key Differences Between Pruning and Quantization
Pruning reduces model size by removing less important neurons or weights, while quantization compresses models by lowering the precision of numerical values. Pruning targets model sparsity to improve computational efficiency, whereas quantization focuses on reducing memory usage and accelerating inference through lower bit-width representations. Both techniques enhance AI model deployment on resource-constrained devices but differ fundamentally in their approach to optimization.
Benefits of Pruning for AI Model Optimization
Pruning significantly reduces AI model complexity by eliminating redundant neurons and connections, leading to lower memory usage and faster inference times. This optimization enhances model efficiency without substantially sacrificing accuracy, making it ideal for deploying AI on resource-constrained devices. By simplifying model architecture, pruning also facilitates easier model compression and improved energy efficiency in real-time AI applications.
Advantages of Quantization in AI Deployment
Quantization significantly reduces the model size and inference latency by converting high-precision weights to lower-precision formats, making AI deployment on edge devices more efficient. It enables real-time processing with lower power consumption, which is crucial for mobile and IoT applications. Furthermore, quantization maintains comparable accuracy to full-precision models while drastically improving computational performance.
Challenges in Pruning and Quantization Approaches
Pruning techniques in artificial intelligence face challenges such as identifying the optimal sparsity level without sacrificing model accuracy and managing the uneven distribution of pruned connections, which can lead to irregular memory access patterns. Quantization approaches struggle with maintaining precision, especially in lower bit-widths, which often results in significant accuracy degradation for models with sensitive parameters. Both methods require careful calibration and hardware-aware optimization to balance efficiency gains with model performance in deployment scenarios.
Impact on Model Accuracy: Pruning vs Quantization
Pruning reduces model complexity by removing redundant parameters, which can slightly degrade accuracy if not carefully tuned, particularly in deep neural networks. Quantization compresses model weights by reducing numerical precision, often preserving accuracy near floating-point levels while enabling faster inference and lower memory usage. Empirical studies show that combining pruning with quantization can maintain competitive accuracy while significantly improving model efficiency for edge deployment.
Use Cases: When to Choose Pruning or Quantization
Pruning is ideal for use cases requiring reduced model size with minimal impact on accuracy, such as deploying deep neural networks on resource-constrained devices like mobile phones or embedded systems. Quantization excels in scenarios demanding faster inference and lower power consumption, making it suitable for real-time applications like speech recognition or autonomous driving. Choosing pruning or quantization depends on whether preserving model precision or optimizing computational efficiency is the priority in the deployment environment.
Combining Pruning and Quantization for Enhanced Efficiency
Combining pruning and quantization in artificial intelligence models significantly enhances computational efficiency and reduces memory usage by eliminating redundant weights and representing parameters with lower precision. This integrated approach maintains model accuracy while enabling faster inference and deployment on resource-constrained devices such as edge AI platforms and mobile systems. Research shows that joint application can achieve up to 70% reduction in model size with minimal performance degradation, optimizing AI model scalability and operational cost.
Future Trends in Model Compression Techniques
Future trends in model compression techniques focus on hybrid approaches combining pruning and quantization to maximize efficiency without sacrificing accuracy. Advances in dynamic pruning algorithms and mixed-precision quantization enable adaptive model optimization tailored to hardware constraints and real-time applications. Emerging research emphasizes automated compression pipelines leveraging reinforcement learning and neural architecture search for scalable and generalized AI model deployment.
Pruning vs Quantization Infographic