Federation distributes data across multiple independent systems, enabling real-time access and query processing without duplication, which enhances scalability and fault tolerance. Replication creates copies of data across different storage nodes, ensuring data availability and redundancy but increasing storage costs and synchronization complexity. Choosing federation over replication depends on the need for data consistency, latency requirements, and infrastructure capabilities in managing Big Data pet environments.
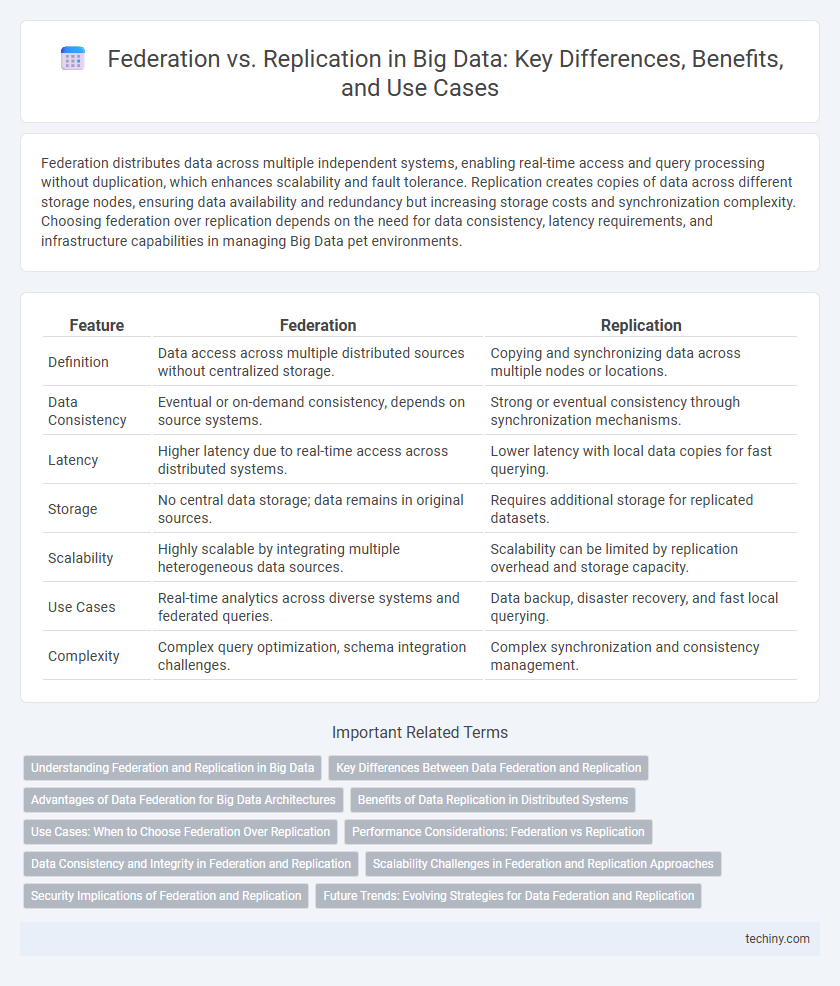
Table of Comparison
| Feature | Federation | Replication |
|---|---|---|
| Definition | Data access across multiple distributed sources without centralized storage. | Copying and synchronizing data across multiple nodes or locations. |
| Data Consistency | Eventual or on-demand consistency, depends on source systems. | Strong or eventual consistency through synchronization mechanisms. |
| Latency | Higher latency due to real-time access across distributed systems. | Lower latency with local data copies for fast querying. |
| Storage | No central data storage; data remains in original sources. | Requires additional storage for replicated datasets. |
| Scalability | Highly scalable by integrating multiple heterogeneous data sources. | Scalability can be limited by replication overhead and storage capacity. |
| Use Cases | Real-time analytics across diverse systems and federated queries. | Data backup, disaster recovery, and fast local querying. |
| Complexity | Complex query optimization, schema integration challenges. | Complex synchronization and consistency management. |
Understanding Federation and Replication in Big Data
Federation in Big Data refers to the integration of data from multiple autonomous sources, enabling unified query access without moving the data physically. Replication involves copying data across different nodes or clusters to enhance availability, fault tolerance, and load balancing. Understanding these concepts is crucial for designing scalable data architectures that balance consistency, latency, and resource utilization.
Key Differences Between Data Federation and Replication
Data federation provides a virtual integration layer that allows real-time querying across multiple heterogeneous sources without physically moving data, while data replication creates and maintains copies of data at different locations to ensure data availability and redundancy. Federation enables unified access and reduces storage costs by avoiding data duplication, whereas replication improves data locality and fault tolerance by synchronizing datasets across systems. Key differences include federation's emphasis on real-time data access versus replication's focus on data consistency and disaster recovery.
Advantages of Data Federation for Big Data Architectures
Data federation in big data architectures allows for real-time access to multiple heterogeneous data sources without physical data movement, enhancing agility and reducing storage costs. It enables unified querying across distributed datasets, improving data consistency and simplifying governance. This approach supports scalability and flexibility, making it ideal for complex analytics and dynamic business environments.
Benefits of Data Replication in Distributed Systems
Data replication in distributed systems enhances data availability by creating multiple copies across different nodes, minimizing downtime during failures. It improves read performance by enabling parallel access to data, reducing latency for end-users. Replication also strengthens fault tolerance and disaster recovery strategies, ensuring data integrity even when individual components fail.
Use Cases: When to Choose Federation Over Replication
Federation is ideal for use cases requiring real-time data access across distributed systems without duplicating data, such as in multi-cloud environments or global enterprises with strict data sovereignty policies. Replication suits scenarios demanding high availability and disaster recovery by maintaining multiple copies of data across locations. Choose federation when minimizing data redundancy and ensuring up-to-date information access are priorities, especially where consistent query performance across heterogeneous data sources is essential.
Performance Considerations: Federation vs Replication
Federation improves performance by distributing query loads across multiple autonomous databases, reducing bottlenecks and enabling parallel processing. Replication enhances read performance by duplicating data across nodes, but it can introduce latency during synchronization and increase storage overhead. Choosing between federation and replication depends on workload patterns, with federation excelling in complex queries requiring data integration and replication favored for high availability and fast read access.
Data Consistency and Integrity in Federation and Replication
Federation in big data systems enhances data consistency by enabling distributed queries across multiple databases while maintaining data integrity through synchronized schemas and controlled data access. Replication improves data availability and fault tolerance by copying data across nodes, but it requires robust conflict resolution mechanisms to preserve consistency and avoid data anomalies. Both approaches demand tailored consistency models--federated systems often use eventual consistency with synchronized schema management, whereas replication relies on strong consistency protocols or eventual consistency depending on the replication strategy.
Scalability Challenges in Federation and Replication Approaches
Federation in big data architectures faces scalability challenges due to the complexity of managing distributed data sources, which can lead to increased latency and inconsistent query performance as the number of nodes grows. Replication approaches improve read scalability by duplicating data across multiple servers, but they introduce challenges related to data synchronization, network overhead, and eventual consistency. Balancing these trade-offs requires advanced coordination mechanisms and optimized data partitioning strategies to maintain high availability and efficient query execution.
Security Implications of Federation and Replication
Federation in big data environments enhances security by enabling decentralized control, reducing single points of failure and limiting access to localized data domains, which minimizes exposure of sensitive information. Replication increases data availability and fault tolerance but can expand the attack surface by creating multiple copies, necessitating robust encryption and synchronization mechanisms to ensure data consistency and integrity across nodes. Implementing federation demands stringent access controls and identity management, while replication requires comprehensive auditing and secure data transmission protocols to mitigate potential breaches.
Future Trends: Evolving Strategies for Data Federation and Replication
Future trends in Big Data highlight a shift towards hybrid models combining federation and replication to optimize data accessibility and consistency. Advances in AI-driven orchestration enable dynamic data placement, reducing latency and improving resource allocation across distributed systems. Enhanced security protocols and real-time analytics integration are evolving strategies, ensuring scalable, efficient, and secure data management frameworks.
Federation vs Replication Infographic