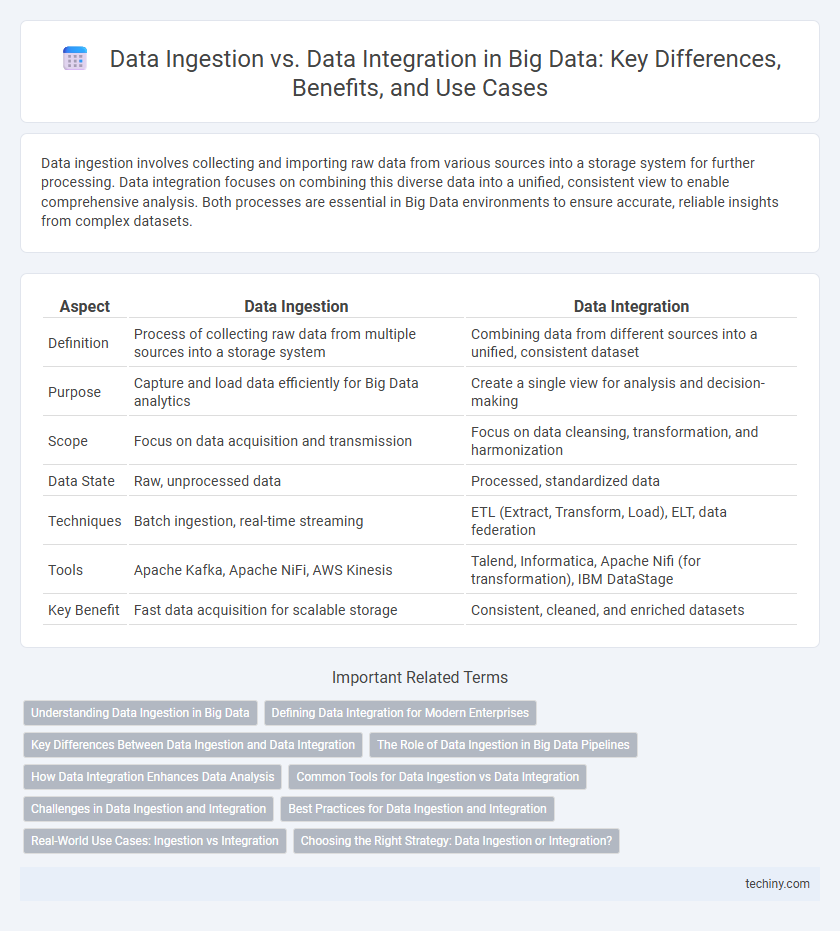
Data ingestion involves collecting and importing raw data from various sources into a storage system for further processing. Data integration focuses on combining this diverse data into a unified, consistent view to enable comprehensive analysis. Both processes are essential in Big Data environments to ensure accurate, reliable insights from complex datasets.
Table of Comparison
| Aspect | Data Ingestion | Data Integration |
|---|---|---|
| Definition | Process of collecting raw data from multiple sources into a storage system | Combining data from different sources into a unified, consistent dataset |
| Purpose | Capture and load data efficiently for Big Data analytics | Create a single view for analysis and decision-making |
| Scope | Focus on data acquisition and transmission | Focus on data cleansing, transformation, and harmonization |
| Data State | Raw, unprocessed data | Processed, standardized data |
| Techniques | Batch ingestion, real-time streaming | ETL (Extract, Transform, Load), ELT, data federation |
| Tools | Apache Kafka, Apache NiFi, AWS Kinesis | Talend, Informatica, Apache Nifi (for transformation), IBM DataStage |
| Key Benefit | Fast data acquisition for scalable storage | Consistent, cleaned, and enriched datasets |
Understanding Data Ingestion in Big Data
Data ingestion in Big Data refers to the process of collecting and importing large volumes of diverse data from multiple sources into a centralized storage system for analysis. It involves real-time or batch processing methods to ensure continuous, efficient, and scalable data flow, handling structured, semi-structured, and unstructured data types. Effective data ingestion frameworks prioritize latency reduction, data quality, and schema evolution to support advanced analytics and decision-making processes.
Defining Data Integration for Modern Enterprises
Data integration in modern enterprises involves combining data from diverse sources to provide a unified view, enabling more accurate analytics and decision-making. It encompasses processes such as data cleansing, transformation, and consolidation to ensure consistency and reliability across business systems. Effective data integration supports real-time access and enhances operational efficiency by breaking down data silos within organizations.
Key Differences Between Data Ingestion and Data Integration
Data ingestion involves the process of collecting raw data from various sources and loading it into a storage system, whereas data integration focuses on combining and transforming this ingested data to create a unified, consistent view for analysis. Key differences include ingestion handling the volume and velocity of incoming data streams, while integration emphasizes data quality, schema mapping, and resolving discrepancies across multiple datasets. Effective big data architectures rely on seamless coordination between data ingestion pipelines and integration frameworks to enable accurate analytics and actionable insights.
The Role of Data Ingestion in Big Data Pipelines
Data ingestion is the critical first step in big data pipelines, responsible for collecting raw data from diverse sources such as IoT devices, social media, and enterprise databases. This process ensures the continuous and real-time flow of high-volume, high-velocity data into storage systems like Hadoop Distributed File System (HDFS) or cloud-based data lakes. Efficient data ingestion lays the foundation for subsequent data integration, enabling accurate and timely data processing, analytics, and decision-making in big data environments.
How Data Integration Enhances Data Analysis
Data integration consolidates diverse data sources into a unified view, enabling more comprehensive and accurate data analysis compared to data ingestion, which primarily focuses on data collection. By harmonizing structured and unstructured data from various platforms, data integration improves data quality, consistency, and accessibility for advanced analytics. This enhancement allows organizations to derive deeper insights, improve decision-making, and leverage predictive analytics effectively.
Common Tools for Data Ingestion vs Data Integration
Common tools for data ingestion include Apache Kafka, Apache Flume, and Amazon Kinesis, which efficiently capture and stream large volumes of real-time data from diverse sources. In contrast, data integration tools such as Talend, Informatica PowerCenter, and Microsoft Azure Data Factory focus on transforming, consolidating, and loading data into unified repositories or data warehouses. Leveraging the right combination of ingestion and integration tools enhances data pipeline efficiency and ensures high-quality, consolidated datasets for advanced analytics.
Challenges in Data Ingestion and Integration
Data ingestion faces challenges such as handling high-velocity data streams, ensuring data quality, and managing heterogeneous data sources in real-time environments. Data integration struggles with harmonizing diverse data formats, resolving schema mismatches, and maintaining data consistency across distributed systems. Both processes demand robust scalability, fault tolerance, and effective metadata management to support seamless analytics and decision-making.
Best Practices for Data Ingestion and Integration
Efficient data ingestion requires automation tools that support real-time processing and batch loading to ensure high throughput and minimal latency. Data integration best practices emphasize schema harmonization, data quality validation, and utilizing unified data platforms to maintain consistency across diverse sources. Leveraging metadata management and incremental data updates optimizes synchronization between ingestion pipelines and integration workflows for scalable big data environments.
Real-World Use Cases: Ingestion vs Integration
Data ingestion involves collecting raw data from various sources such as IoT devices, social media, and enterprise systems for immediate processing or storage in data lakes. Data integration focuses on combining and transforming this ingested data from disparate formats and sources into unified, consistent datasets for advanced analytics and business intelligence. In real-world use cases, organizations ingest streaming sensor data for real-time monitoring while using data integration to create holistic customer profiles by merging CRM, transactional, and web data.
Choosing the Right Strategy: Data Ingestion or Integration?
Selecting the appropriate strategy between data ingestion and data integration depends on organizational needs and data workflows. Data ingestion emphasizes efficiently importing raw, diverse datasets into storage systems like data lakes or Hadoop clusters for subsequent analysis. In contrast, data integration focuses on merging and transforming data from multiple sources into a unified, consistent format, typically suited for real-time analytics and business intelligence platforms.
Data Ingestion vs Data Integration Infographic