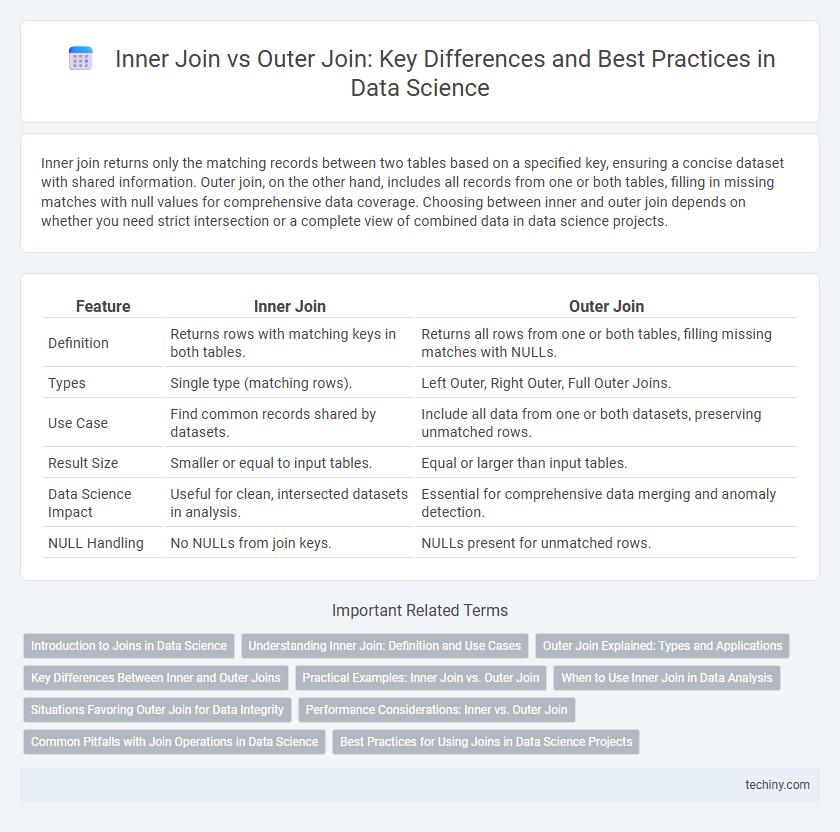
Inner join returns only the matching records between two tables based on a specified key, ensuring a concise dataset with shared information. Outer join, on the other hand, includes all records from one or both tables, filling in missing matches with null values for comprehensive data coverage. Choosing between inner and outer join depends on whether you need strict intersection or a complete view of combined data in data science projects.
Table of Comparison
| Feature | Inner Join | Outer Join |
|---|---|---|
| Definition | Returns rows with matching keys in both tables. | Returns all rows from one or both tables, filling missing matches with NULLs. |
| Types | Single type (matching rows). | Left Outer, Right Outer, Full Outer Joins. |
| Use Case | Find common records shared by datasets. | Include all data from one or both datasets, preserving unmatched rows. |
| Result Size | Smaller or equal to input tables. | Equal or larger than input tables. |
| Data Science Impact | Useful for clean, intersected datasets in analysis. | Essential for comprehensive data merging and anomaly detection. |
| NULL Handling | No NULLs from join keys. | NULLs present for unmatched rows. |
Introduction to Joins in Data Science
Inner join returns only the matching rows between two datasets based on a specified key, ensuring analysis of intersecting information. Outer join combines all records from both datasets, including non-matching rows, preserving complete data for comprehensive insights. Understanding these join types enhances data integration and quality in data science workflows.
Understanding Inner Join: Definition and Use Cases
Inner join combines rows from two tables based on matching values in specified columns, returning only the common records where the keys exist in both datasets. It is essential for tasks like filtering data sets to find intersections, matching customer IDs with transaction records, or merging product details with sales data when exact matches are required. Common use cases include relational database queries in SQL, data cleaning workflows, and correlating data points across multiple sources to enhance analysis accuracy.
Outer Join Explained: Types and Applications
Outer join merges datasets by including all records from one or both tables, filling with NULLs where no match exists, enhancing data completeness in analyses. Types of outer joins include left outer join, right outer join, and full outer join, each catering to different use cases in data integration and reporting. Applications of outer joins are crucial in scenarios like combining customer data with purchase history or merging incomplete survey datasets to preserve all information points.
Key Differences Between Inner and Outer Joins
Inner joins return only the rows with matching keys in both tables, filtering out non-matching data and ensuring a strict intersection of datasets. Outer joins include all rows from one or both tables, filling in missing values with nulls, which helps preserve unmatched data for comprehensive analysis. Choosing between inner and outer joins impacts data completeness and accuracy in predictive modeling and data integration workflows.
Practical Examples: Inner Join vs. Outer Join
Inner join retrieves records with matching values in both tables, such as merging customer orders with customer details where only customers with orders appear. Outer join returns all records from one or both tables, including unmatched entries, like listing all customers with their orders if available, filling missing data with NULL. Practical scenarios include reporting sales where inner join filters active transactions, while outer join highlights customers without purchases for targeted marketing.
When to Use Inner Join in Data Analysis
Inner join is ideal in data analysis when combining datasets with matching keys to extract only the relevant intersecting records, ensuring clean and focused results. It is frequently used in scenarios such as customer purchase analysis, where only customers with transactions are needed, or in fraud detection to link suspicious activities across related tables. This join type enhances performance by minimizing dataset size and eliminating null values from unmatched records.
Situations Favoring Outer Join for Data Integrity
Outer join is favored when maintaining complete data integrity across multiple datasets is crucial, especially in scenarios involving missing or incomplete records. It ensures inclusion of all entries from one or both tables, capturing unmatched rows that inner join would exclude. This is essential for comprehensive data analysis, such as detecting discrepancies or validating data completeness in big data environments.
Performance Considerations: Inner vs. Outer Join
Inner joins generally offer better performance than outer joins because they process fewer rows, focusing only on matching records between tables. Outer joins require scanning and combining all rows, including non-matching entries, which increases computational overhead and memory usage. Optimizing query execution plans and indexing key columns can mitigate the performance gap, but inner joins typically remain more efficient for large datasets.
Common Pitfalls with Join Operations in Data Science
Common pitfalls with join operations in data science include unintentionally duplicating rows due to many-to-many relationships and missing data when using inner joins that exclude non-matching records. Outer joins help retain unmatched rows, but they can introduce null values that require careful handling to avoid misleading analysis. Understanding the data's structure and selecting the appropriate join type is crucial to maintaining data integrity and analytical accuracy.
Best Practices for Using Joins in Data Science Projects
When performing joins in data science projects, prioritize using inner joins to merge datasets when matching records only are required, ensuring cleaner and more relevant data outputs. Use outer joins strategically to retain all records from one or both tables, which is essential for comprehensive analysis where missing data points must be identified or preserved. Optimize join operations by indexing key columns and filtering datasets early to improve performance and reduce computational overhead in large-scale data processing workflows.
inner join vs outer join Infographic