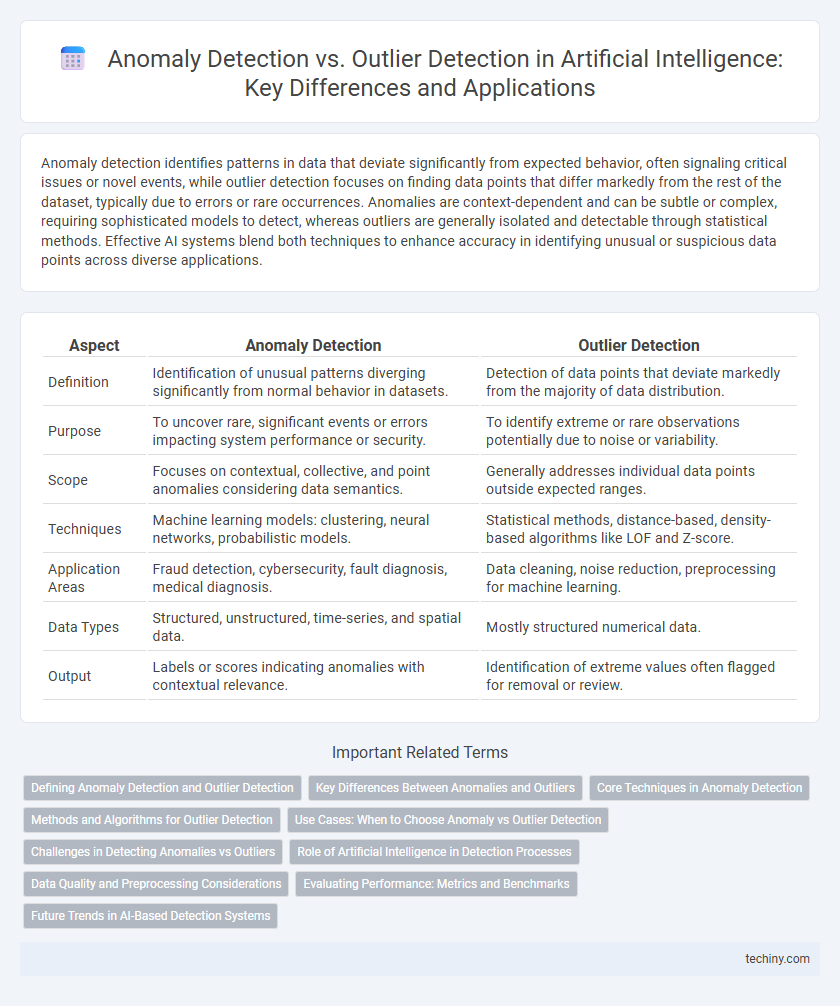
Anomaly detection identifies patterns in data that deviate significantly from expected behavior, often signaling critical issues or novel events, while outlier detection focuses on finding data points that differ markedly from the rest of the dataset, typically due to errors or rare occurrences. Anomalies are context-dependent and can be subtle or complex, requiring sophisticated models to detect, whereas outliers are generally isolated and detectable through statistical methods. Effective AI systems blend both techniques to enhance accuracy in identifying unusual or suspicious data points across diverse applications.
Table of Comparison
| Aspect | Anomaly Detection | Outlier Detection |
|---|---|---|
| Definition | Identification of unusual patterns diverging significantly from normal behavior in datasets. | Detection of data points that deviate markedly from the majority of data distribution. |
| Purpose | To uncover rare, significant events or errors impacting system performance or security. | To identify extreme or rare observations potentially due to noise or variability. |
| Scope | Focuses on contextual, collective, and point anomalies considering data semantics. | Generally addresses individual data points outside expected ranges. |
| Techniques | Machine learning models: clustering, neural networks, probabilistic models. | Statistical methods, distance-based, density-based algorithms like LOF and Z-score. |
| Application Areas | Fraud detection, cybersecurity, fault diagnosis, medical diagnosis. | Data cleaning, noise reduction, preprocessing for machine learning. |
| Data Types | Structured, unstructured, time-series, and spatial data. | Mostly structured numerical data. |
| Output | Labels or scores indicating anomalies with contextual relevance. | Identification of extreme values often flagged for removal or review. |
Defining Anomaly Detection and Outlier Detection
Anomaly detection identifies patterns in data that deviate significantly from expected behavior, often signaling rare or suspicious events such as fraud or system faults. Outlier detection specifically targets individual data points that differ markedly from the rest of a dataset, which may indicate measurement errors or novel phenomena. Both techniques are critical in machine learning for enhancing data quality and improving predictive model accuracy.
Key Differences Between Anomalies and Outliers
Anomalies refer to patterns in data that significantly deviate from expected behavior, often indicating critical issues or rare events, while outliers are individual data points that fall far from the rest of the dataset, usually due to noise or measurement errors. Anomaly detection focuses on identifying unusual data patterns that may signal fraud, system failures, or cybersecurity threats, whereas outlier detection primarily targets irregular data points that can distort statistical analysis. Understanding these key differences helps improve machine learning models by tailoring detection techniques to either broader unusual behaviors or isolated data deviations.
Core Techniques in Anomaly Detection
Core techniques in anomaly detection involve statistical methods, machine learning algorithms, and deep learning models designed to identify patterns that deviate significantly from the norm. Statistical approaches such as Gaussian mixture models and hypothesis testing detect anomalies based on probability distributions. Machine learning techniques include clustering, nearest neighbor algorithms, and ensemble methods that learn normal behavior to flag anomalies in complex datasets.
Methods and Algorithms for Outlier Detection
Outlier detection methods primarily include statistical techniques such as Z-score and Modified Z-score, clustering-based approaches like DBSCAN and K-means, and machine learning algorithms such as Isolation Forest, One-Class SVM, and Autoencoders. These algorithms identify data points that significantly deviate from the majority by modeling normal behavior or density estimation, enabling high accuracy in uncovering rare or novel anomalies. Advanced approaches often combine multiple algorithms to improve robustness and reduce false positives in complex datasets.
Use Cases: When to Choose Anomaly vs Outlier Detection
Anomaly detection excels in identifying subtle, context-dependent deviations in time-series data for applications like fraud detection and predictive maintenance. Outlier detection is more effective for spotting isolated, extreme values in static datasets, often used in data cleaning and quality control. Choosing between them depends on whether the goal is to uncover unusual patterns over time or to find irregular data points in a single dataset snapshot.
Challenges in Detecting Anomalies vs Outliers
Detecting anomalies in Artificial Intelligence involves identifying patterns that deviate significantly from expected behavior, often requiring sophisticated models to handle dynamic and complex data distributions. Outlier detection typically targets isolated data points that diverge from the norm but may be less context-sensitive, posing challenges in distinguishing genuine anomalies from noise. The key difficulty lies in balancing sensitivity to rare events against the risk of false positives, especially in high-dimensional spaces with evolving data streams.
Role of Artificial Intelligence in Detection Processes
Artificial Intelligence enhances anomaly detection by leveraging machine learning algorithms to identify patterns and deviations in large datasets, enabling real-time and adaptive detection of unusual events. In outlier detection, AI models analyze data distributions to distinguish rare but significant data points from noise, improving accuracy and reducing false positives. The integration of AI in detection processes facilitates scalability, deeper insights, and automation across various domains such as cybersecurity, finance, and healthcare.
Data Quality and Preprocessing Considerations
Anomaly detection emphasizes identifying patterns that deviate from expected behavior, often requiring advanced preprocessing techniques such as normalization, imputation, and feature scaling to enhance data quality. Outlier detection focuses on pinpointing data points that differ significantly from the majority, relying heavily on data cleaning steps like noise reduction and handling missing values to improve accuracy. Both methodologies demand robust data preprocessing pipelines to mitigate the impact of poor data quality on model performance and ensure reliable, actionable insights.
Evaluating Performance: Metrics and Benchmarks
Evaluating performance in anomaly detection and outlier detection relies heavily on metrics such as precision, recall, F1-score, and Area Under the Curve (AUC) to measure the accuracy and robustness of models. Benchmark datasets like KDD Cup 1999, NAB, and UCI anomaly detection collections provide standardized environments to compare algorithm effectiveness. Understanding the differences in metric sensitivity and dataset characteristics is crucial for selecting appropriate evaluation strategies in AI-driven anomaly and outlier detection tasks.
Future Trends in AI-Based Detection Systems
Future trends in AI-based detection systems emphasize enhanced accuracy and real-time processing capabilities by leveraging deep learning and advanced neural networks. Integration of explainable AI (XAI) techniques aims to improve transparency in anomaly and outlier detection results, facilitating better decision-making across industries. Continued development of hybrid models combining statistical methods with AI promises to address complex data patterns and evolving threats in cybersecurity, finance, and IoT environments.
Anomaly Detection vs Outlier Detection Infographic