Transformers outperform LSTMs in handling long-range dependencies due to their self-attention mechanism, enabling parallel processing and improved scalability for large datasets. Unlike LSTMs, which process sequential data step-by-step, transformers capture global context more effectively, leading to superior performance in natural language understanding tasks. This architectural advantage has driven their dominance in state-of-the-art AI models for language translation, text generation, and beyond.
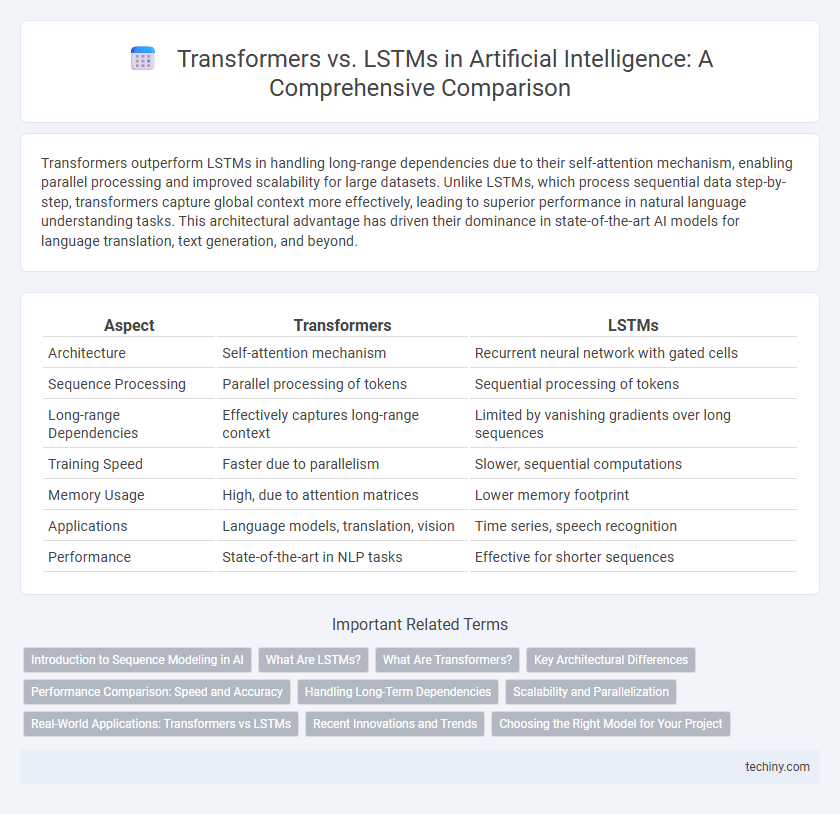
Table of Comparison
| Aspect | Transformers | LSTMs |
|---|---|---|
| Architecture | Self-attention mechanism | Recurrent neural network with gated cells |
| Sequence Processing | Parallel processing of tokens | Sequential processing of tokens |
| Long-range Dependencies | Effectively captures long-range context | Limited by vanishing gradients over long sequences |
| Training Speed | Faster due to parallelism | Slower, sequential computations |
| Memory Usage | High, due to attention matrices | Lower memory footprint |
| Applications | Language models, translation, vision | Time series, speech recognition |
| Performance | State-of-the-art in NLP tasks | Effective for shorter sequences |
Introduction to Sequence Modeling in AI
Transformers revolutionize sequence modeling by using self-attention mechanisms to capture long-range dependencies in data more effectively than LSTMs, which rely on gated recurrent units to process sequences sequentially. Unlike LSTMs, Transformers enable parallel processing of sequence data, significantly improving training speed and scalability. This advancement is critical for natural language processing tasks, where understanding context over long text spans enhances model accuracy and comprehension.
What Are LSTMs?
Long Short-Term Memory networks (LSTMs) are a type of recurrent neural network (RNN) designed to overcome the vanishing gradient problem, enabling the model to learn long-term dependencies in sequential data. LSTMs use memory cells with gates--input, forget, and output gates--that regulate the flow of information, making them effective for tasks like speech recognition, time series prediction, and language modeling. Despite their ability to handle sequences, LSTMs have limitations in parallelization and capturing global context compared to Transformers.
What Are Transformers?
Transformers are advanced deep learning models designed for processing sequential data, primarily in natural language processing tasks. Unlike LSTMs, which rely on recurrent structures, Transformers utilize self-attention mechanisms to capture long-range dependencies efficiently and enable parallelization. This architecture significantly improves performance in language translation, text generation, and other AI applications by handling context more effectively than traditional recurrent neural networks.
Key Architectural Differences
Transformers utilize self-attention mechanisms to process entire input sequences simultaneously, enabling parallel computation and capturing long-range dependencies more effectively than LSTMs. In contrast, LSTMs rely on sequential processing through gated recurrent units that maintain memory over time, which can limit parallelization and make training slower. The absence of recurrence in Transformers results in better scalability and improved performance on tasks involving large datasets and complex contextual understanding.
Performance Comparison: Speed and Accuracy
Transformers outperform LSTMs in speed due to their parallel processing capabilities, enabling faster training times on large datasets. In terms of accuracy, Transformers excel in capturing long-range dependencies, resulting in superior performance on complex language tasks compared to LSTMs. Benchmark results consistently show Transformers achieving higher accuracy rates in natural language processing applications while reducing computational costs.
Handling Long-Term Dependencies
Transformers excel in handling long-term dependencies by utilizing self-attention mechanisms that capture relationships across entire sequences without the limitations of fixed-size memory cells. In contrast, LSTMs rely on gated recurrent units to manage temporal dependencies but often struggle with vanishing gradients in very long sequences. This architectural difference enables Transformers to perform more effectively in tasks requiring the integration of extensive contextual information, such as natural language understanding and machine translation.
Scalability and Parallelization
Transformers outperform LSTMs in scalability due to their ability to process input data in parallel, leveraging self-attention mechanisms rather than sequential steps. This parallelization enables faster training on large datasets and improves efficiency in handling long-range dependencies in natural language processing tasks. LSTMs, reliant on sequential processing, face limitations in scaling and slower computation speeds compared to the transformer architecture.
Real-World Applications: Transformers vs LSTMs
Transformers excel in real-world applications such as natural language processing, machine translation, and image recognition due to their ability to handle long-range dependencies with parallel processing. LSTMs remain effective for sequential data like time series forecasting and speech recognition but often struggle with scalability and training times compared to Transformers. Industry adoption increasingly favors Transformers for tasks requiring large-scale data and complex pattern recognition, highlighting their superior performance in diverse AI-driven solutions.
Recent Innovations and Trends
Transformers have revolutionized natural language processing by enabling parallel processing and attention mechanisms, outperforming LSTMs in tasks requiring long-range dependencies and scalability. Recent innovations such as the development of efficient Transformer architectures like Transformers with sparse attention and adaptive computation have further enhanced performance and reduced computational costs. Trends indicate a growing dominance of Transformers in AI research and applications, driven by advancements in self-supervised learning and large-scale pretraining.
Choosing the Right Model for Your Project
Transformers excel in handling long-range dependencies in complex datasets, making them ideal for natural language processing tasks requiring context understanding and parallel processing efficiency. LSTMs remain valuable for sequential data with temporal dependencies, especially in projects with limited computational resources or where real-time processing is critical. Selecting the right model depends on factors like dataset size, computational capacity, and the specific nature of the task, with Transformers favored for scalability and LSTMs for simpler, time-sensitive applications.
Transformers vs LSTMs Infographic