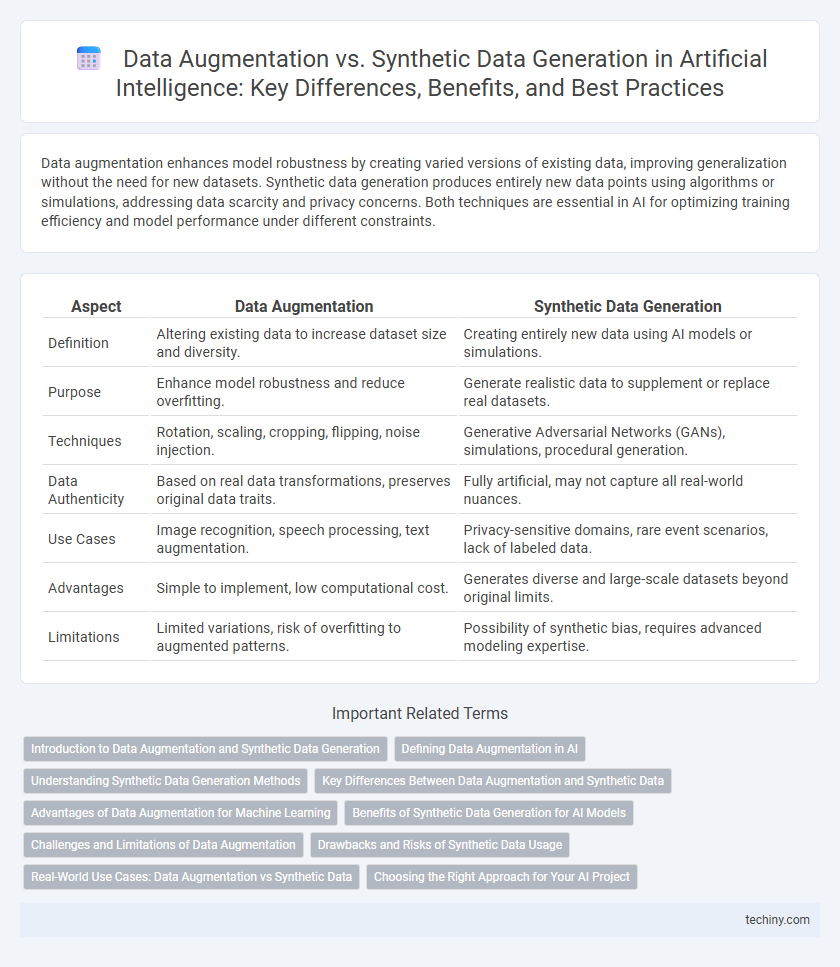
Data augmentation enhances model robustness by creating varied versions of existing data, improving generalization without the need for new datasets. Synthetic data generation produces entirely new data points using algorithms or simulations, addressing data scarcity and privacy concerns. Both techniques are essential in AI for optimizing training efficiency and model performance under different constraints.
Table of Comparison
| Aspect | Data Augmentation | Synthetic Data Generation |
|---|---|---|
| Definition | Altering existing data to increase dataset size and diversity. | Creating entirely new data using AI models or simulations. |
| Purpose | Enhance model robustness and reduce overfitting. | Generate realistic data to supplement or replace real datasets. |
| Techniques | Rotation, scaling, cropping, flipping, noise injection. | Generative Adversarial Networks (GANs), simulations, procedural generation. |
| Data Authenticity | Based on real data transformations, preserves original data traits. | Fully artificial, may not capture all real-world nuances. |
| Use Cases | Image recognition, speech processing, text augmentation. | Privacy-sensitive domains, rare event scenarios, lack of labeled data. |
| Advantages | Simple to implement, low computational cost. | Generates diverse and large-scale datasets beyond original limits. |
| Limitations | Limited variations, risk of overfitting to augmented patterns. | Possibility of synthetic bias, requires advanced modeling expertise. |
Introduction to Data Augmentation and Synthetic Data Generation
Data augmentation enhances machine learning models by artificially increasing training data diversity through transformations like rotation, scaling, and flipping of existing datasets. Synthetic data generation creates entirely new data points using algorithms such as GANs and variational autoencoders to simulate realistic datasets from scratch. Both techniques aim to address data scarcity and improve model robustness, with data augmentation modifying original samples and synthetic generation fabricating new instances.
Defining Data Augmentation in AI
Data augmentation in AI involves artificially increasing the size and diversity of training datasets by applying transformations such as rotations, translations, and noise to existing data. This technique enhances model robustness and generalization without the need for additional real-world data collection. Common applications include image recognition, natural language processing, and speech recognition, where augmented data improves algorithm performance.
Understanding Synthetic Data Generation Methods
Synthetic data generation methods in artificial intelligence involve creating artificial datasets that simulate real-world data distributions to improve model training and validation. Techniques include generative adversarial networks (GANs), variational autoencoders (VAEs), and rule-based simulations, each offering specific advantages in generating diverse, high-quality samples. Unlike data augmentation, which transforms existing data, synthetic data generation builds entirely new data points, enhancing model robustness and mitigating privacy concerns.
Key Differences Between Data Augmentation and Synthetic Data
Data augmentation enhances existing datasets by applying transformations such as rotation, scaling, or cropping to original data, thereby increasing diversity without creating new data points. Synthetic data generation produces entirely new, artificial data samples using models like GANs or simulators, enabling the creation of data where real samples are scarce or sensitive. The key difference lies in augmentation modifying real data to improve robustness, while synthetic generation creates novel data to address data limitations and privacy concerns.
Advantages of Data Augmentation for Machine Learning
Data augmentation enhances machine learning by increasing the diversity and volume of training datasets without requiring additional data collection, improving model generalization and robustness. It is cost-effective and reduces overfitting by introducing variations such as rotations, translations, and noise to existing samples. This technique is particularly advantageous in scenarios with limited labeled data, enabling more effective training of deep learning models.
Benefits of Synthetic Data Generation for AI Models
Synthetic data generation enhances AI model training by creating diverse, large-scale datasets that overcome limitations of real-world data scarcity and privacy concerns. This approach improves model robustness and generalization by simulating rare or edge cases not captured in original datasets. Synthetic datasets also accelerate development cycles, reducing dependency on costly and time-consuming data collection processes.
Challenges and Limitations of Data Augmentation
Data augmentation faces challenges including the limited diversity of generated variations, which can lead to overfitting and reduced model generalization. It often struggles with complex data types like text and time-series, where meaningful transformations are difficult to design without introducing noise or bias. Moreover, excessive augmentation can increase computational costs and training times, hindering scalability in large-scale AI applications.
Drawbacks and Risks of Synthetic Data Usage
Synthetic data generation in artificial intelligence carries risks such as reduced model accuracy when synthetic datasets fail to capture real-world variability and complexities. There is also potential for bias amplification if the generative models reflect existing data prejudices, leading to skewed or unfair outcomes. Furthermore, privacy concerns arise when synthetic data inadvertently leaks sensitive information through reconstruction attacks targeting generative model training details.
Real-World Use Cases: Data Augmentation vs Synthetic Data
Data augmentation enhances AI models by applying transformations like rotation, scaling, and flipping to existing real-world datasets, improving robustness and generalization in image recognition and natural language processing. Synthetic data generation creates entirely new data points using techniques such as GANs or simulation, enabling training in scenarios where real data is scarce or privacy-sensitive, particularly in autonomous driving and healthcare diagnostics. Both methods address dataset limitations but differ in complexity and application scope, with data augmentation serving as a cost-effective enhancement and synthetic data enabling innovative use cases beyond real-world constraints.
Choosing the Right Approach for Your AI Project
Data augmentation enhances existing datasets by applying transformations such as rotation, scaling, or noise addition to improve model generalization without needing new data collection. Synthetic data generation creates entirely new data instances using AI-driven models like GANs or simulations, offering scalability and privacy advantages when real data is scarce or sensitive. Selecting the right approach depends on project goals, data availability, computational resources, and the required data diversity for effective model training.
Data Augmentation vs Synthetic Data Generation Infographic