Data mining involves extracting valuable patterns and knowledge from large datasets, while machine learning focuses on building models that learn from data to make predictions or decisions. Data mining relies heavily on statistical techniques to uncover hidden insights, whereas machine learning uses algorithms that improve their performance as they are exposed to more data. Both fields overlap in analyzing data, but machine learning emphasizes automation and prediction, whereas data mining prioritizes discovery and interpretation.
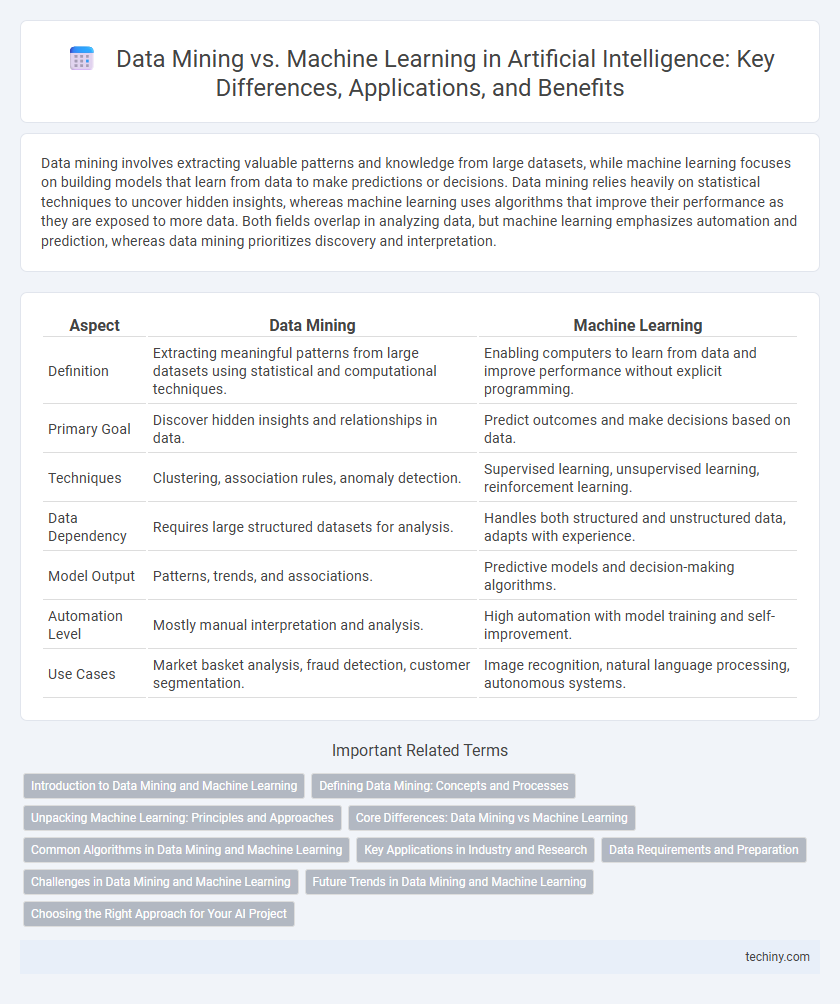
Table of Comparison
| Aspect | Data Mining | Machine Learning |
|---|---|---|
| Definition | Extracting meaningful patterns from large datasets using statistical and computational techniques. | Enabling computers to learn from data and improve performance without explicit programming. |
| Primary Goal | Discover hidden insights and relationships in data. | Predict outcomes and make decisions based on data. |
| Techniques | Clustering, association rules, anomaly detection. | Supervised learning, unsupervised learning, reinforcement learning. |
| Data Dependency | Requires large structured datasets for analysis. | Handles both structured and unstructured data, adapts with experience. |
| Model Output | Patterns, trends, and associations. | Predictive models and decision-making algorithms. |
| Automation Level | Mostly manual interpretation and analysis. | High automation with model training and self-improvement. |
| Use Cases | Market basket analysis, fraud detection, customer segmentation. | Image recognition, natural language processing, autonomous systems. |
Introduction to Data Mining and Machine Learning
Data mining involves extracting valuable patterns and knowledge from large datasets using statistical analysis, clustering, and classification techniques, while machine learning focuses on developing algorithms that enable computers to learn from and make predictions or decisions based on data. Key methods in data mining include association rule learning and anomaly detection, which uncover hidden relationships within data. Machine learning encompasses supervised, unsupervised, and reinforcement learning, emphasizing model training and evaluation to improve performance on specific tasks.
Defining Data Mining: Concepts and Processes
Data mining involves extracting valuable patterns and knowledge from large datasets using statistical, mathematical, and machine learning techniques. Key processes include data cleaning, integration, selection, transformation, pattern evaluation, and knowledge presentation. Unlike machine learning, which focuses on algorithmic model training and prediction, data mining emphasizes discovery and interpretation of meaningful data structures.
Unpacking Machine Learning: Principles and Approaches
Machine learning, a subset of artificial intelligence, focuses on developing algorithms that allow computers to learn from and make predictions based on data, contrasting with data mining which primarily extracts patterns and knowledge from large datasets. Core principles of machine learning include supervised learning, unsupervised learning, and reinforcement learning, each leveraging different approaches to model training and outcome prediction. Techniques such as neural networks, decision trees, and support vector machines exemplify approaches that optimize performance through iterative data processing and pattern recognition.
Core Differences: Data Mining vs Machine Learning
Data mining focuses on discovering hidden patterns and extracting valuable insights from large datasets through techniques like clustering, classification, and association rule mining. Machine learning emphasizes building predictive models that learn from data to make decisions or predictions, relying heavily on algorithms such as neural networks, support vector machines, and decision trees. The core difference lies in data mining's goal of knowledge extraction and pattern recognition versus machine learning's objective of enabling systems to improve performance on tasks through experience.
Common Algorithms in Data Mining and Machine Learning
Data mining commonly employs algorithms such as decision trees, k-means clustering, and association rule mining to uncover patterns and relationships in large datasets. Machine learning leverages algorithms including neural networks, support vector machines, and gradient boosting to enable predictive modeling and automated decision-making. Both fields utilize classification, clustering, and regression techniques, but machine learning often emphasizes continuous learning and model optimization through training on labeled data.
Key Applications in Industry and Research
Data mining excels in extracting patterns from large datasets, supporting industries like finance for fraud detection and marketing for customer segmentation. Machine learning drives predictive analytics and automation, crucial in healthcare for disease diagnosis and in autonomous vehicles for real-time decision-making. Both techniques enhance research by enabling knowledge discovery and improving model accuracy across scientific disciplines.
Data Requirements and Preparation
Data mining requires structured and clean datasets to efficiently extract meaningful patterns, emphasizing extensive data preprocessing including cleaning, integration, and transformation. Machine learning relies on large, high-quality labeled datasets for training models, necessitating rigorous data preparation stages such as normalization, feature selection, and augmentation. Both fields demand significant data curation efforts, but machine learning often requires more sophisticated feature engineering to optimize predictive accuracy.
Challenges in Data Mining and Machine Learning
Data mining faces challenges such as handling large volumes of complex, unstructured data and ensuring data quality and integration from diverse sources. Machine learning struggles with model overfitting, limited labeled data for training, and the interpretability of complex algorithms. Both fields require advanced techniques to address scalability, noise reduction, and the evolving nature of data patterns.
Future Trends in Data Mining and Machine Learning
Future trends in data mining emphasize the integration of advanced machine learning algorithms to enhance pattern recognition and predictive analytics across big data environments. Machine learning is evolving towards automated model generation and real-time decision-making capabilities, leveraging edge computing and neural network advancements. The convergence of explainable AI with data mining techniques will drive transparency and trustworthiness in AI applications, fostering broader adoption in industries such as healthcare, finance, and autonomous systems.
Choosing the Right Approach for Your AI Project
Data mining focuses on extracting valuable patterns from large datasets through statistical analysis, while machine learning emphasizes building predictive models that improve with experience. Selecting the right approach depends on project goals: use data mining for uncovering insights and trends, and machine learning for developing adaptive algorithms that enable automation and decision-making. Understanding the dataset size, complexity, and desired outcome is crucial to optimize AI project success.
Data Mining vs Machine Learning Infographic