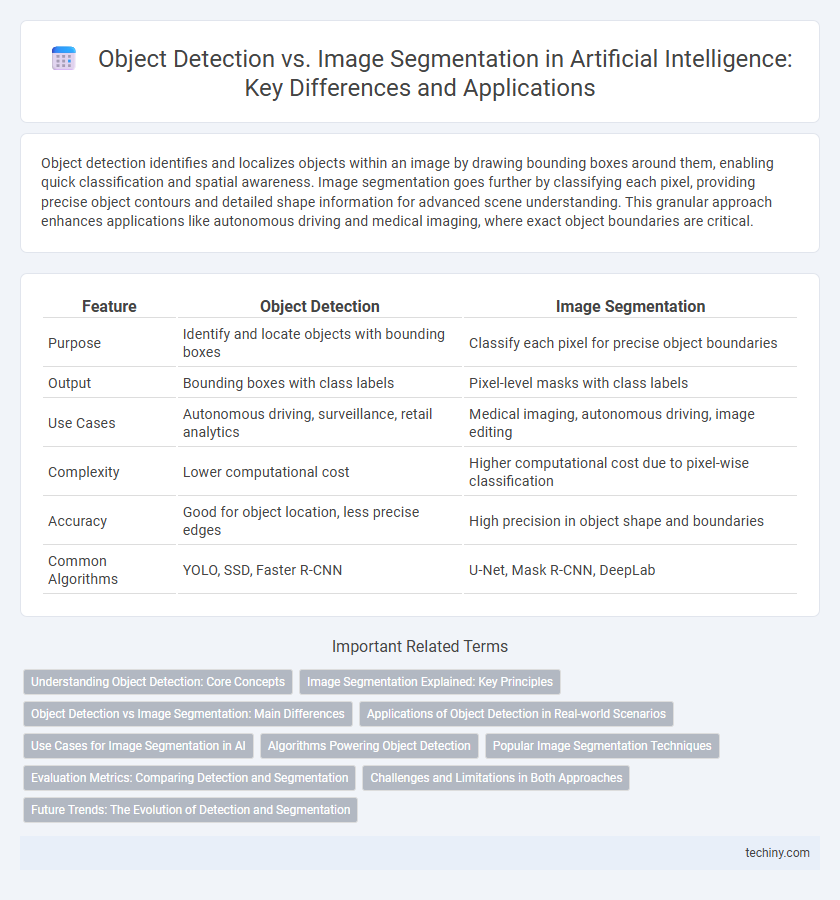
Object detection identifies and localizes objects within an image by drawing bounding boxes around them, enabling quick classification and spatial awareness. Image segmentation goes further by classifying each pixel, providing precise object contours and detailed shape information for advanced scene understanding. This granular approach enhances applications like autonomous driving and medical imaging, where exact object boundaries are critical.
Table of Comparison
| Feature | Object Detection | Image Segmentation |
|---|---|---|
| Purpose | Identify and locate objects with bounding boxes | Classify each pixel for precise object boundaries |
| Output | Bounding boxes with class labels | Pixel-level masks with class labels |
| Use Cases | Autonomous driving, surveillance, retail analytics | Medical imaging, autonomous driving, image editing |
| Complexity | Lower computational cost | Higher computational cost due to pixel-wise classification |
| Accuracy | Good for object location, less precise edges | High precision in object shape and boundaries |
| Common Algorithms | YOLO, SSD, Faster R-CNN | U-Net, Mask R-CNN, DeepLab |
Understanding Object Detection: Core Concepts
Object detection involves identifying and locating objects within an image by drawing bounding boxes around them, enabling machines to recognize multiple instances and categories simultaneously. This technique relies on algorithms such as YOLO, SSD, and Faster R-CNN, which balance accuracy and processing speed for real-time applications. Core concepts include feature extraction, classification, and localization, crucial for applications like autonomous driving, surveillance, and medical imaging.
Image Segmentation Explained: Key Principles
Image segmentation divides an image into meaningful regions or segments, assigning a label to every pixel to distinguish objects distinctly. It leverages deep learning models like U-Net and Mask R-CNN, which enhance precision by capturing spatial hierarchies and object boundaries more effectively than traditional object detection. This pixel-level classification enables applications in medical imaging, autonomous driving, and environmental monitoring by providing detailed structural understanding beyond bounding box identification.
Object Detection vs Image Segmentation: Main Differences
Object detection identifies and localizes objects within an image by drawing bounding boxes around them, while image segmentation classifies each pixel to delineate exact object shapes. Object detection focuses on detecting multiple objects and their locations, whereas image segmentation provides precise boundaries and detailed object masks. These fundamental differences influence their applications; object detection suits tasks like counting or locating objects, while image segmentation is essential for detailed scene understanding and pixel-level analysis.
Applications of Object Detection in Real-world Scenarios
Object detection plays a crucial role in autonomous driving by enabling vehicles to identify pedestrians, other cars, and traffic signs, enhancing safety and navigation. In retail, it supports inventory management and checkout automation by detecting products on shelves and in shopping carts. Security systems utilize object detection to monitor surveillance footage for unauthorized access or unusual behavior, improving threat detection and response times.
Use Cases for Image Segmentation in AI
Image segmentation in AI excels in medical imaging by enabling precise tumor boundary identification, enhancing diagnostic accuracy and treatment planning. It is crucial in autonomous driving for distinguishing road elements such as vehicles, pedestrians, and traffic signs, improving safety and navigation. Furthermore, image segmentation supports agricultural monitoring through detailed crop and weed differentiation, optimizing yield management and resource allocation.
Algorithms Powering Object Detection
Object detection relies on algorithms such as YOLO (You Only Look Once), SSD (Single Shot MultiBox Detector), and Faster R-CNN, which enable real-time identification and localization of objects within images. These algorithms utilize convolutional neural networks (CNNs) to extract hierarchical features, allowing for efficient bounding box prediction and class labeling. Advances in anchor-free models and transformer-based approaches are further enhancing the precision and speed of object detection tasks.
Popular Image Segmentation Techniques
Popular image segmentation techniques in Artificial Intelligence include Fully Convolutional Networks (FCNs), U-Net, and Mask R-CNN, which enable pixel-level classification for precise object boundary delineation. Unlike object detection that identifies bounding boxes, these methods generate detailed masks that improve accuracy in medical imaging, autonomous driving, and scene understanding. Advances such as DeepLab and Pyramid Scene Parsing Network (PSPNet) enhance contextual information capture, boosting segmentation performance in complex visual environments.
Evaluation Metrics: Comparing Detection and Segmentation
Object detection evaluation relies heavily on Intersection over Union (IoU) to measure the overlap between predicted bounding boxes and ground truth, with metrics such as mean Average Precision (mAP) summarizing performance. In contrast, image segmentation evaluation emphasizes pixel-wise accuracy and Dice coefficient, assessing how well pixel classifications align with true object boundaries. Both tasks leverage IoU but differ in granularity, as detection focuses on bounding box localization while segmentation requires precise per-pixel delineation, making metrics like Boundary F-measure crucial for segmentation quality.
Challenges and Limitations in Both Approaches
Object detection struggles with accurately localizing overlapping or small objects, often leading to missed detections and false positives due to bounding box limitations. Image segmentation faces challenges in computational complexity and fine-grained boundary delineation, especially in cluttered or low-contrast scenes, which can cause inaccurate pixel classification. Both approaches are limited by the availability of large, annotated datasets and the difficulty in generalizing models to diverse, real-world environments.
Future Trends: The Evolution of Detection and Segmentation
Future trends in object detection and image segmentation emphasize integration with deep learning architectures like transformers for enhanced accuracy and efficiency. Advances in real-time processing and edge computing are driving the deployment of hybrid models that combine detection and segmentation for comprehensive scene understanding. Emerging applications in autonomous systems and medical imaging demand adaptive algorithms capable of continuous learning and multi-modal data fusion.
Object Detection vs Image Segmentation Infographic