Weak supervision leverages noisy, limited, or imprecise labeled data to train models, enabling faster and more scalable machine learning without the need for extensive manual annotation. Strong supervision relies on accurately labeled datasets, providing high-quality, precise information that enhances model performance but requires significant time and resources to obtain. Balancing the trade-offs between weak and strong supervision is essential for optimizing model accuracy and efficiency in AI applications.
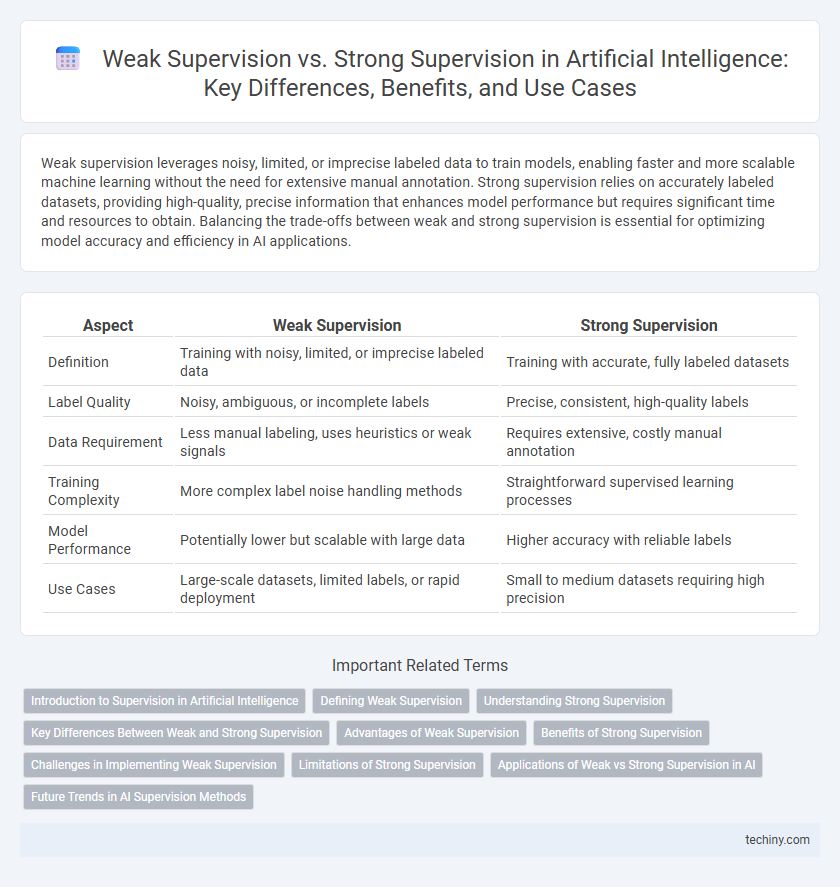
Table of Comparison
| Aspect | Weak Supervision | Strong Supervision |
|---|---|---|
| Definition | Training with noisy, limited, or imprecise labeled data | Training with accurate, fully labeled datasets |
| Label Quality | Noisy, ambiguous, or incomplete labels | Precise, consistent, high-quality labels |
| Data Requirement | Less manual labeling, uses heuristics or weak signals | Requires extensive, costly manual annotation |
| Training Complexity | More complex label noise handling methods | Straightforward supervised learning processes |
| Model Performance | Potentially lower but scalable with large data | Higher accuracy with reliable labels |
| Use Cases | Large-scale datasets, limited labels, or rapid deployment | Small to medium datasets requiring high precision |
Introduction to Supervision in Artificial Intelligence
Supervision in Artificial Intelligence refers to the process of guiding machine learning models through labeled data to improve their predictive performance. Weak supervision utilizes limited, noisy, or imprecise labels, making it suitable for scenarios with scarce annotated data, whereas strong supervision relies on large amounts of high-quality, accurately labeled datasets. Understanding the differences between weak and strong supervision is crucial for selecting appropriate training strategies in AI model development.
Defining Weak Supervision
Weak supervision refers to training machine learning models using limited, noisy, or imprecise labeled data instead of fully annotated datasets. It leverages sources such as heuristic rules, crowdsourced labels, or external knowledge bases to generate approximate labels for training. This approach enables efficient model training when acquiring high-quality, strongly supervised data is costly or impractical.
Understanding Strong Supervision
Strong supervision in artificial intelligence involves training models using accurately labeled datasets where each input is paired with a precise output, enabling high-quality learning outcomes. This method relies on comprehensive, manually annotated data that guides algorithms to recognize patterns with greater accuracy and reliability. Strong supervision is preferred in scenarios demanding precise predictions and robust model performance, despite the higher cost and effort involved in data labeling.
Key Differences Between Weak and Strong Supervision
Weak supervision uses limited, noisy, or imprecise labels to train AI models, often relying on heuristics, crowd-sourced labels, or incomplete data. Strong supervision involves fully labeled datasets with accurate and comprehensive annotations, enabling precise model training and higher performance. The key difference lies in data quality and labeling accuracy, impacting model reliability and scalability.
Advantages of Weak Supervision
Weak supervision offers scalable data labeling by leveraging noisy, limited, or imprecise sources, significantly reducing the reliance on large volumes of fully annotated data. This approach accelerates model training in resource-constrained environments and enhances adaptability across diverse applications without extensive manual intervention. Weak supervision enables rapid experimentation and iterative improvements, making it cost-effective for developing AI solutions in real-world scenarios.
Benefits of Strong Supervision
Strong supervision in artificial intelligence ensures higher accuracy and reliability by leveraging precisely labeled datasets, which drive models to learn detailed feature representations. This approach enables faster convergence during training, reducing errors and improving overall model performance on complex tasks. Strong supervision also facilitates better generalization to unseen data, enhancing robustness in real-world applications.
Challenges in Implementing Weak Supervision
Implementing weak supervision in artificial intelligence presents significant challenges such as managing noisy and imprecise labels that can degrade model performance and require sophisticated noise-robust algorithms. Data integration complexities arise when combining multiple weak signals from diverse sources, demanding advanced aggregation and conflict resolution techniques. Ensuring scalability and generalizability across domains remains difficult due to the variability in weak supervision quality and the lack of standardized frameworks.
Limitations of Strong Supervision
Strong supervision in artificial intelligence relies heavily on large amounts of accurately labeled data, which is often costly and time-consuming to obtain. This dependency limits scalability and restricts model training in domains with scarce or expensive annotations. Moreover, strong supervision models may suffer from reduced generalization when exposed to noisy or out-of-distribution data.
Applications of Weak vs Strong Supervision in AI
Weak supervision enables AI models to learn from limited or noisy labeled data, making it ideal for applications such as natural language processing, image recognition, and medical diagnosis where obtaining large labeled datasets is challenging. Strong supervision relies on fully labeled, high-quality datasets, which enhances accuracy in tasks like autonomous driving, fraud detection, and speech recognition that require precise and reliable predictions. Leveraging weak supervision accelerates development in emerging fields by reducing the dependency on costly manual labeling, while strong supervision remains essential for high-stakes environments demanding stringent validation.
Future Trends in AI Supervision Methods
Future trends in AI supervision methods emphasize hybrid approaches combining weak supervision's cost-efficiency with strong supervision's accuracy to optimize large-scale data labeling. Advances in self-supervised and semi-supervised learning are expected to reduce dependency on fully annotated datasets while enhancing model generalization. Emerging techniques leveraging synthetic data generation and transfer learning will further transform the landscape of AI training by improving scalability and robustness in diverse applications.
Weak Supervision vs Strong Supervision Infographic