KNN (K-Nearest Neighbors) is a supervised learning algorithm used for classification and regression by identifying the closest labeled data points to predict the target value. KMeans is an unsupervised clustering algorithm that groups data points into distinct clusters based on their feature similarity without prior labels. While KNN relies on labeled data for prediction accuracy, KMeans focuses on finding inherent patterns and structures within unlabeled datasets.
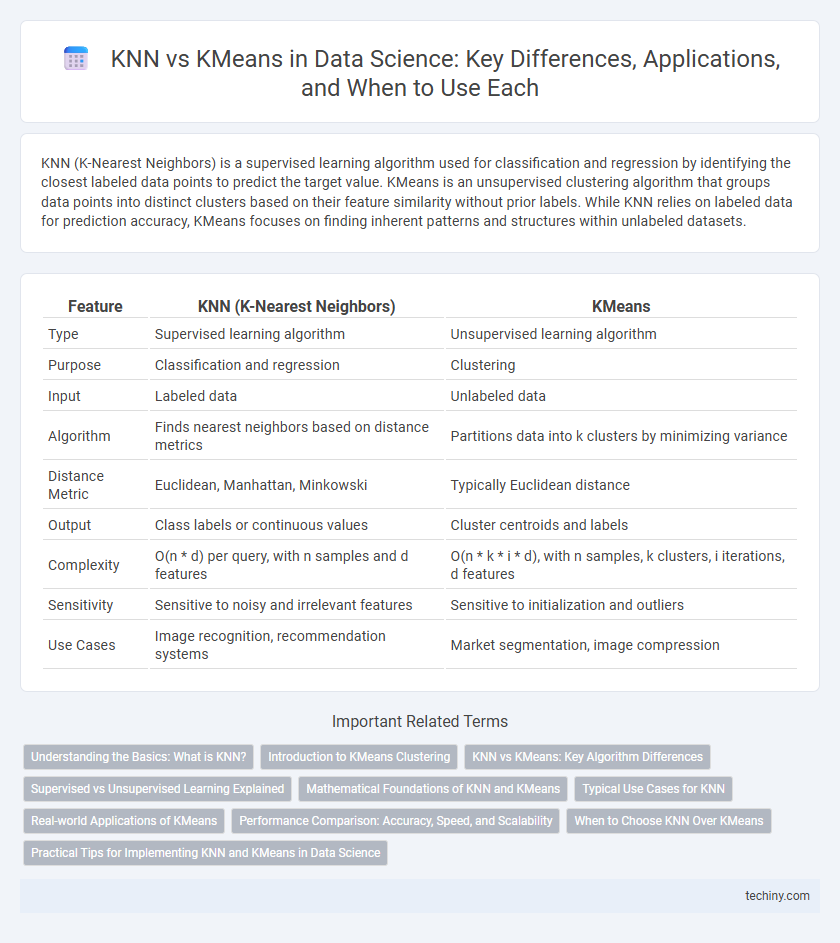
Table of Comparison
| Feature | KNN (K-Nearest Neighbors) | KMeans |
|---|---|---|
| Type | Supervised learning algorithm | Unsupervised learning algorithm |
| Purpose | Classification and regression | Clustering |
| Input | Labeled data | Unlabeled data |
| Algorithm | Finds nearest neighbors based on distance metrics | Partitions data into k clusters by minimizing variance |
| Distance Metric | Euclidean, Manhattan, Minkowski | Typically Euclidean distance |
| Output | Class labels or continuous values | Cluster centroids and labels |
| Complexity | O(n * d) per query, with n samples and d features | O(n * k * i * d), with n samples, k clusters, i iterations, d features |
| Sensitivity | Sensitive to noisy and irrelevant features | Sensitive to initialization and outliers |
| Use Cases | Image recognition, recommendation systems | Market segmentation, image compression |
Understanding the Basics: What is KNN?
K-Nearest Neighbors (KNN) is a supervised machine learning algorithm used for classification and regression by identifying the closest data points in the feature space based on distance metrics like Euclidean distance. KNN assigns labels to new data points by analyzing the majority class among its k closest neighbors, making it effective for pattern recognition and anomaly detection. Unlike KMeans clustering, which is unsupervised and groups data into clusters, KNN relies on labeled training data to make predictions.
Introduction to KMeans Clustering
KMeans clustering is an unsupervised machine learning algorithm that partitions data into k distinct clusters based on feature similarity, minimizing intra-cluster variance. Each data point is assigned to the nearest cluster centroid by calculating Euclidean distance, allowing the algorithm to iteratively update centroids until convergence. Unlike KNN, which is a supervised classification algorithm, KMeans focuses on discovering inherent groupings in unlabeled datasets, making it essential for exploratory data analysis and pattern recognition.
KNN vs KMeans: Key Algorithm Differences
K-Nearest Neighbors (KNN) is a supervised learning algorithm used for classification and regression by assigning labels based on the closest training examples in feature space, while KMeans is an unsupervised clustering algorithm that partitions data into K distinct clusters by minimizing intra-cluster variance. KNN relies on distance metrics such as Euclidean or Manhattan to identify neighbors, whereas KMeans iteratively updates centroids to optimize cluster assignments. The primary difference lies in KNN's use of labeled data for prediction and KMeans' role in discovering inherent data groupings without labels.
Supervised vs Unsupervised Learning Explained
K-Nearest Neighbors (KNN) is a supervised learning algorithm used for classification and regression tasks by labeling data points based on the majority class of their nearest neighbors. KMeans, on the other hand, is an unsupervised learning algorithm that clusters data into k groups by minimizing intra-cluster variance without using labeled outputs. The key distinction lies in KNN requiring labeled training data to make predictions, whereas KMeans identifies patterns and structures from unlabeled data through iterative centroid optimization.
Mathematical Foundations of KNN and KMeans
K-Nearest Neighbors (KNN) relies on distance metrics such as Euclidean or Manhattan distance to classify data points based on the proximity to its k closest neighbors in a feature space. KMeans clustering employs an iterative algorithm that minimizes the within-cluster sum of squares (WCSS) by updating cluster centroids to optimize the partitioning of data points into k clusters. Both methods utilize vector space representations and geometric distance computations, but KNN focuses on supervised classification, whereas KMeans addresses unsupervised clustering through centroid optimization.
Typical Use Cases for KNN
KNN (K-Nearest Neighbors) excels in supervised learning tasks such as classification and regression, where labeled training data guides prediction of unseen instances. It is widely applied in image recognition, recommendation systems, and anomaly detection due to its simplicity and effectiveness in identifying local patterns. KNN's distance-based approach makes it ideal for scenarios requiring instance-based learning and real-time decision-making.
Real-world Applications of KMeans
KMeans excels in customer segmentation, enabling businesses to tailor marketing strategies by grouping customers based on purchasing behavior and demographics. It is widely used in image compression, where it reduces the number of colors by clustering similar pixels, optimizing storage and processing. Furthermore, KMeans facilitates anomaly detection in network security by identifying clusters of normal activity and flagging outliers as potential threats.
Performance Comparison: Accuracy, Speed, and Scalability
K-Nearest Neighbors (KNN) excels in accuracy for small to medium-sized labeled datasets but suffers from slower prediction speeds due to its instance-based nature, making it less scalable for large datasets. K-Means clustering, an unsupervised learning algorithm, offers faster execution and better scalability by iteratively updating centroids, but it may sacrifice accuracy, especially when clusters are not well-separated or data is high-dimensional. In performance-sensitive applications, KNN is preferred for tasks requiring precise classification, whereas K-Means is optimal for large-scale clustering with speed constraints.
When to Choose KNN Over KMeans
KNN is preferred over KMeans when the task involves supervised learning with labeled data, such as classification or regression, where the goal is to predict the class or value of a new data point based on its nearest neighbors. KMeans, an unsupervised clustering algorithm, is suited for discovering inherent groupings in unlabeled datasets but does not perform classification. KNN excels when precise class boundaries are needed and the dataset has a clear distribution of labels, while KMeans is ideal for segmenting data into clusters without prior knowledge of categories.
Practical Tips for Implementing KNN and KMeans in Data Science
When implementing KNN, normalize features and choose an appropriate k value to balance bias and variance while considering computational cost for large datasets. For KMeans, initialize centroids using methods like k-means++ to improve convergence and evaluate cluster quality with metrics such as silhouette score or inertia. Both algorithms benefit from careful feature scaling and dimensionality reduction techniques like PCA to enhance performance and interpretability in data science projects.
KNN vs KMeans Infographic