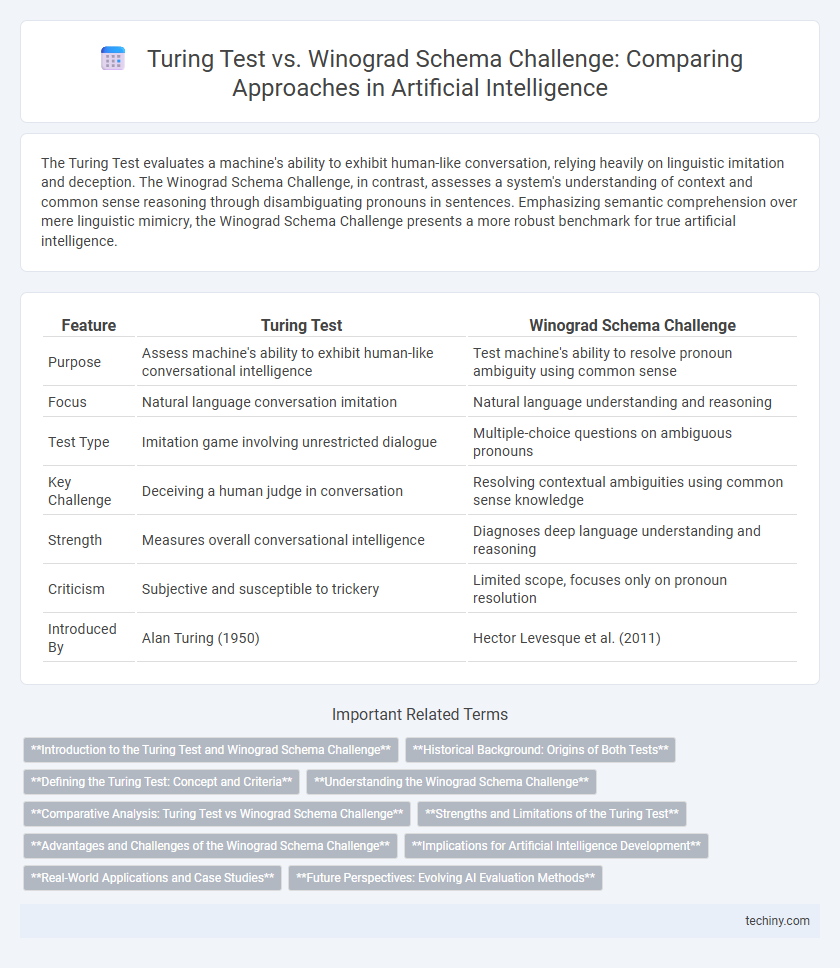
The Turing Test evaluates a machine's ability to exhibit human-like conversation, relying heavily on linguistic imitation and deception. The Winograd Schema Challenge, in contrast, assesses a system's understanding of context and common sense reasoning through disambiguating pronouns in sentences. Emphasizing semantic comprehension over mere linguistic mimicry, the Winograd Schema Challenge presents a more robust benchmark for true artificial intelligence.
Table of Comparison
| Feature | Turing Test | Winograd Schema Challenge |
|---|---|---|
| Purpose | Assess machine's ability to exhibit human-like conversational intelligence | Test machine's ability to resolve pronoun ambiguity using common sense |
| Focus | Natural language conversation imitation | Natural language understanding and reasoning |
| Test Type | Imitation game involving unrestricted dialogue | Multiple-choice questions on ambiguous pronouns |
| Key Challenge | Deceiving a human judge in conversation | Resolving contextual ambiguities using common sense knowledge |
| Strength | Measures overall conversational intelligence | Diagnoses deep language understanding and reasoning |
| Criticism | Subjective and susceptible to trickery | Limited scope, focuses only on pronoun resolution |
| Introduced By | Alan Turing (1950) | Hector Levesque et al. (2011) |
Introduction to the Turing Test and Winograd Schema Challenge
The Turing Test, proposed by Alan Turing in 1950, evaluates a machine's ability to exhibit intelligent behavior indistinguishable from that of a human through natural language conversations. The Winograd Schema Challenge, introduced by Hector Levesque in 2011, assesses machine understanding by resolving pronoun references within carefully crafted sentences requiring commonsense reasoning. Both tests serve as benchmarks for artificial intelligence, targeting different aspects of human-like comprehension and interaction.
Historical Background: Origins of Both Tests
The Turing Test, proposed by Alan Turing in 1950, serves as a foundational benchmark for evaluating a machine's ability to exhibit human-like intelligence through conversational indistinguishability. In contrast, the Winograd Schema Challenge, introduced by Hector Levesque and colleagues in 2011, emerged as a response to limitations of the Turing Test, focusing on common-sense reasoning and language understanding via carefully designed pronoun disambiguation problems. Both tests reflect evolving perspectives in artificial intelligence, highlighting shifts from broad behavioral imitation to nuanced cognitive assessment.
Defining the Turing Test: Concept and Criteria
The Turing Test, proposed by Alan Turing in 1950, evaluates a machine's ability to exhibit human-like intelligence through natural language conversation indistinguishable from a human interlocutor. The test criteria focus on linguistic indistinguishability and the machine's capacity to respond coherently and contextually to a wide range of topics, emphasizing imitation over understanding. This benchmark remains foundational in artificial intelligence for assessing conversational competence, contrasting with challenges like the Winograd Schema that emphasize contextual reasoning.
Understanding the Winograd Schema Challenge
The Winograd Schema Challenge evaluates a machine's ability to resolve ambiguous pronouns in sentences, requiring deep semantic understanding and contextual reasoning. Unlike the Turing Test, which relies on conversational mimicry to assess intelligence, the Winograd Schema Challenge specifically targets natural language comprehension and commonsense inference. This test presents paired sentences with minimal lexical differences but distinct referent resolutions, making it a robust measure of true understanding in artificial intelligence systems.
Comparative Analysis: Turing Test vs Winograd Schema Challenge
The Turing Test evaluates a machine's ability to exhibit human-like conversational behavior, relying heavily on linguistic imitation and deception. In contrast, the Winograd Schema Challenge assesses contextual understanding and reasoning through ambiguous pronoun resolution, making it a more precise measure of artificial intelligence cognition. While the Turing Test emphasizes fluency and social interaction, the Winograd Schema Challenge focuses on deep semantic comprehension and commonsense reasoning.
Strengths and Limitations of the Turing Test
The Turing Test assesses a machine's ability to exhibit human-like conversational behavior, emphasizing linguistic indistinguishability from humans. Its strength lies in evaluating natural language understanding and interaction in real-time, but it is limited by its reliance on deception and superficial mimicry rather than genuine comprehension. The test struggles to measure deep reasoning or contextual understanding, which are better addressed by challenges like the Winograd Schema.
Advantages and Challenges of the Winograd Schema Challenge
The Winograd Schema Challenge offers a more nuanced evaluation of machine intelligence by requiring systems to resolve ambiguous pronouns using real-world knowledge, which directly tests contextual understanding rather than pattern recognition. Its advantage lies in measuring deeper language comprehension and reasoning abilities, making it difficult for AI to rely solely on statistical methods. However, the challenge faces difficulties such as the limited size of carefully curated schemas and the complexity of evaluating diverse linguistic contexts, which can restrict scalability and generalization across different AI models.
Implications for Artificial Intelligence Development
The Turing Test evaluates a machine's ability to exhibit human-like conversational behavior, primarily assessing linguistic mimicry without deep understanding, while the Winograd Schema Challenge targets contextual reasoning and disambiguation to measure true comprehension. Emphasizing the latter advances AI development toward systems capable of nuanced language processing and contextual inference, which are critical for robust natural language understanding. This shift fosters progress in creating AI that can interpret and respond to complex human communication beyond superficial pattern matching.
Real-World Applications and Case Studies
The Turing Test, historically used to evaluate a machine's ability to exhibit human-like conversation, has been applied in customer service chatbots and virtual assistants, demonstrating strengths in natural language interaction but limitations in understanding context beyond scripted responses. The Winograd Schema Challenge offers a more nuanced benchmark by requiring AI systems to resolve ambiguous pronouns through commonsense reasoning, with real-world applications seen in advanced AI systems for legal document analysis and automated reasoning in healthcare diagnostics. Case studies reveal that while Turing Test-based models excel in conversational fluency, Winograd Schema Challenge-driven models achieve higher accuracy in tasks demanding contextual understanding and semantic disambiguation.
Future Perspectives: Evolving AI Evaluation Methods
Future AI evaluation methods are shifting from traditional benchmarks like the Turing Test toward more nuanced challenges such as the Winograd Schema Challenge, which better assess contextual understanding and commonsense reasoning. Advances in natural language processing and cognitive modeling suggest increasing emphasis on interpretability and explainability within AI systems. Emerging frameworks prioritize dynamic, real-world problem solving to drive the evolution of machine intelligence beyond simple imitation of human conversation.
Turing Test vs Winograd Schema Challenge Infographic