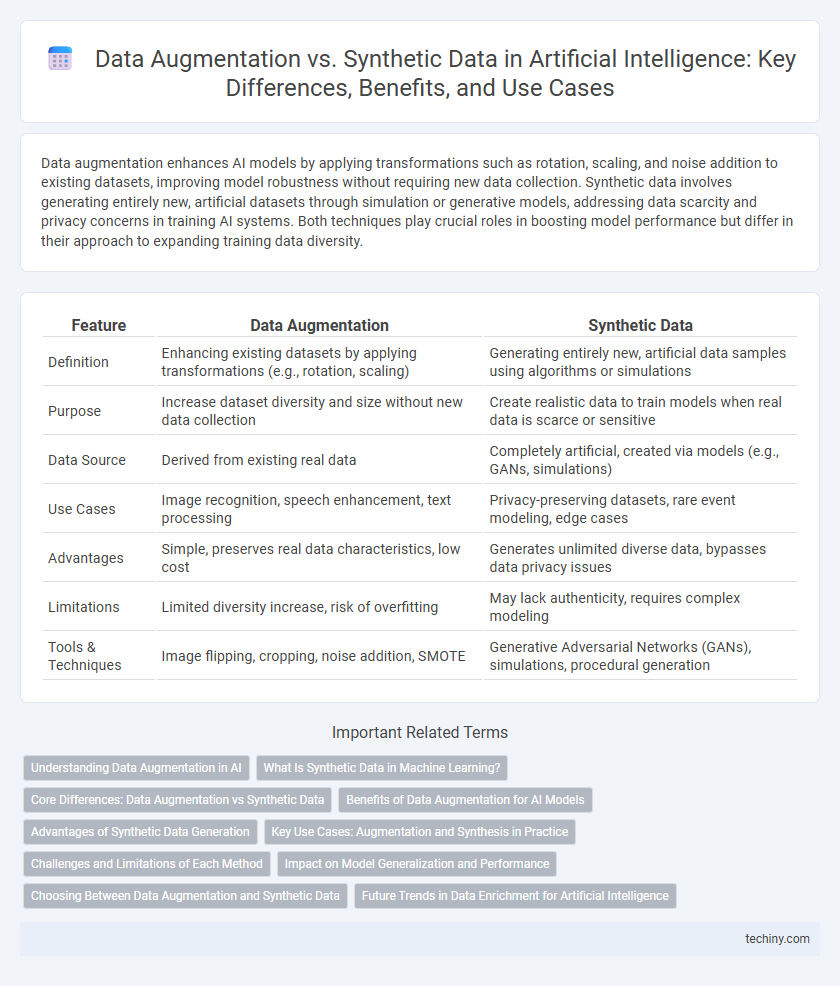
Data augmentation enhances AI models by applying transformations such as rotation, scaling, and noise addition to existing datasets, improving model robustness without requiring new data collection. Synthetic data involves generating entirely new, artificial datasets through simulation or generative models, addressing data scarcity and privacy concerns in training AI systems. Both techniques play crucial roles in boosting model performance but differ in their approach to expanding training data diversity.
Table of Comparison
| Feature | Data Augmentation | Synthetic Data |
|---|---|---|
| Definition | Enhancing existing datasets by applying transformations (e.g., rotation, scaling) | Generating entirely new, artificial data samples using algorithms or simulations |
| Purpose | Increase dataset diversity and size without new data collection | Create realistic data to train models when real data is scarce or sensitive |
| Data Source | Derived from existing real data | Completely artificial, created via models (e.g., GANs, simulations) |
| Use Cases | Image recognition, speech enhancement, text processing | Privacy-preserving datasets, rare event modeling, edge cases |
| Advantages | Simple, preserves real data characteristics, low cost | Generates unlimited diverse data, bypasses data privacy issues |
| Limitations | Limited diversity increase, risk of overfitting | May lack authenticity, requires complex modeling |
| Tools & Techniques | Image flipping, cropping, noise addition, SMOTE | Generative Adversarial Networks (GANs), simulations, procedural generation |
Understanding Data Augmentation in AI
Data augmentation in AI involves creating multiple variations of training data to improve model generalization and robustness without collecting new data. Techniques such as image rotation, flipping, and noise addition enhance existing datasets by simulating real-world variability. This process differs from synthetic data generation, which produces entirely new data samples often using generative models like GANs to address data scarcity or privacy concerns.
What Is Synthetic Data in Machine Learning?
Synthetic data in machine learning refers to artificially generated information that mimics real-world datasets, enabling model training without privacy concerns or data scarcity issues. It is created using techniques such as generative adversarial networks (GANs), simulation, or parametric models to produce diverse and realistic samples. Unlike data augmentation, which modifies existing data, synthetic data originates independently, offering enhanced variability and scalability for AI training.
Core Differences: Data Augmentation vs Synthetic Data
Data augmentation enhances existing datasets by applying transformations such as rotation, scaling, or noise addition to create varied examples, preserving the original data distribution. Synthetic data is generated entirely from models or simulations, producing new, artificial datasets that can mimic real-world scenarios or introduce novel variations. The core difference lies in data augmentation modifying real data to expand its diversity, while synthetic data originates from scratch through algorithmic creation.
Benefits of Data Augmentation for AI Models
Data augmentation enhances AI model performance by increasing the diversity and volume of training datasets, which helps prevent overfitting and improves generalization. Techniques such as rotations, translations, and color adjustments create varied versions of existing data without the need for extensive new data collection. This approach enables models to become more robust to real-world variations while reducing dependency on costly synthetic data generation processes.
Advantages of Synthetic Data Generation
Synthetic data generation enhances AI model training by providing vast, diverse datasets that preserve privacy and reduce reliance on costly real-world data collection. It enables the creation of rare or edge-case scenarios, improving model robustness and generalization. Unlike traditional data augmentation, synthetic data offers customizable, scalable, and bias-controlled datasets critical for advancing machine learning accuracy.
Key Use Cases: Augmentation and Synthesis in Practice
Data augmentation enhances existing datasets by applying transformations such as rotations, flips, or noise addition to improve model robustness in image recognition and natural language processing tasks. Synthetic data generation creates entirely new datasets using algorithms like GANs or simulations, crucial for scenarios with limited real data or privacy constraints in healthcare and autonomous driving. Combining augmentation and synthesis optimizes training diversity and model generalization across AI applications in finance, robotics, and speech recognition.
Challenges and Limitations of Each Method
Data augmentation enhances model performance by creating variations of existing data, but it is limited by the inherent features of the original dataset and can lead to overfitting if diversity is insufficient. Synthetic data generation overcomes data scarcity by producing entirely new samples using techniques like GANs or simulations, yet it faces challenges related to data realism, domain adaptation, and potential biases that can affect model accuracy. Both methods require careful validation to ensure that the augmented or synthetic data do not degrade model generalizability or introduce erroneous patterns.
Impact on Model Generalization and Performance
Data augmentation enhances model generalization by introducing variability in training data through transformations like rotation, scaling, and cropping, which helps models better recognize patterns in unseen data. Synthetic data generation creates entirely new data samples via algorithms such as GANs or simulations, expanding dataset diversity and addressing class imbalance, thereby potentially improving performance in scenarios where real data is scarce. Both approaches contribute to robustness, with synthetic data offering tailored scenarios and data augmentation reinforcing existing data distribution, influencing overall model accuracy and adaptability.
Choosing Between Data Augmentation and Synthetic Data
Choosing between data augmentation and synthetic data depends on the specific requirements of the AI project, such as dataset size, quality, and diversity needs. Data augmentation involves applying transformations like rotation, scaling, and cropping to existing datasets, enhancing model robustness without generating new samples. Synthetic data, created through simulations or generative models, offers the advantage of producing entirely new datasets that can address data scarcity and privacy concerns while increasing variability for improved training outcomes.
Future Trends in Data Enrichment for Artificial Intelligence
Data augmentation techniques such as rotation, scaling, and noise injection will increasingly integrate with synthetic data generation methods using GANs and VAEs to create more diverse and representative datasets. Enhancements in AI-driven synthetic data aim to reduce biases and improve model generalization, addressing limitations of traditional data augmentation. Future trends emphasize the combination of real, augmented, and synthetic data to optimize training efficiency and accuracy in AI systems.
Data Augmentation vs Synthetic Data Infographic