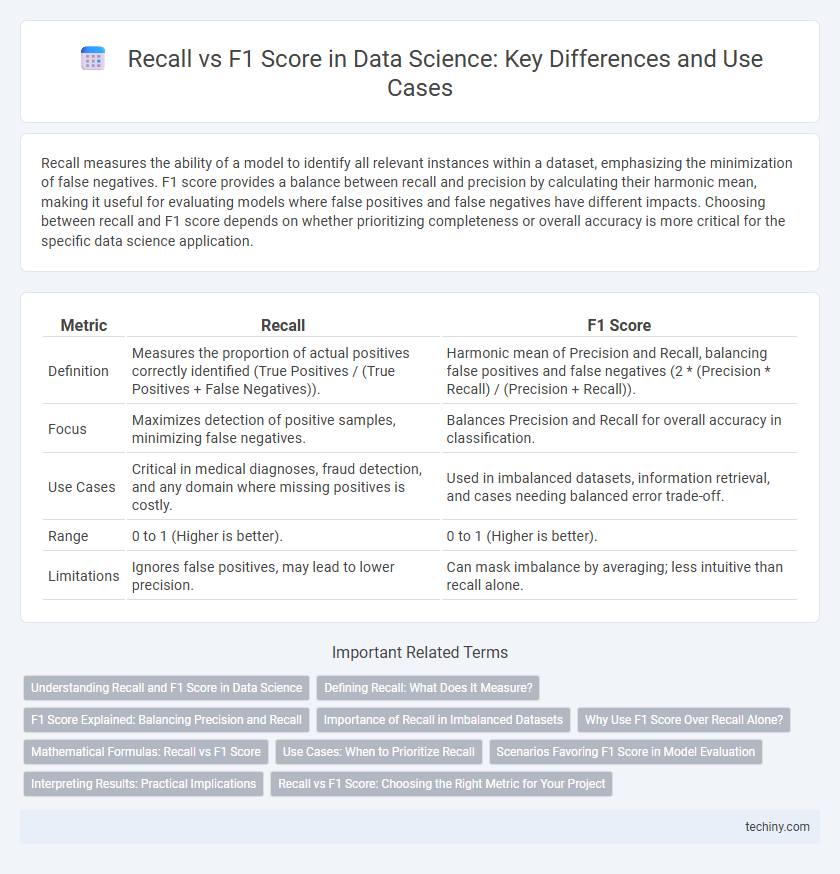
Recall measures the ability of a model to identify all relevant instances within a dataset, emphasizing the minimization of false negatives. F1 score provides a balance between recall and precision by calculating their harmonic mean, making it useful for evaluating models where false positives and false negatives have different impacts. Choosing between recall and F1 score depends on whether prioritizing completeness or overall accuracy is more critical for the specific data science application.
Table of Comparison
| Metric | Recall | F1 Score |
|---|---|---|
| Definition | Measures the proportion of actual positives correctly identified (True Positives / (True Positives + False Negatives)). | Harmonic mean of Precision and Recall, balancing false positives and false negatives (2 * (Precision * Recall) / (Precision + Recall)). |
| Focus | Maximizes detection of positive samples, minimizing false negatives. | Balances Precision and Recall for overall accuracy in classification. |
| Use Cases | Critical in medical diagnoses, fraud detection, and any domain where missing positives is costly. | Used in imbalanced datasets, information retrieval, and cases needing balanced error trade-off. |
| Range | 0 to 1 (Higher is better). | 0 to 1 (Higher is better). |
| Limitations | Ignores false positives, may lead to lower precision. | Can mask imbalance by averaging; less intuitive than recall alone. |
Understanding Recall and F1 Score in Data Science
Recall in data science measures the proportion of actual positive cases correctly identified by a model, emphasizing the ability to minimize false negatives. The F1 score balances recall and precision, providing a harmonic mean that reflects both false positives and false negatives, making it especially useful for imbalanced datasets. Understanding the trade-offs between recall and F1 score is critical for optimizing model performance based on specific problem requirements.
Defining Recall: What Does It Measure?
Recall measures the ability of a data science model to correctly identify all relevant instances in a dataset, emphasizing true positives over false negatives. It quantifies the proportion of actual positive cases that are accurately detected by the model, providing critical insight into sensitivity in classification tasks. High recall is essential in applications like medical diagnosis and fraud detection where missing positive cases can have severe consequences.
F1 Score Explained: Balancing Precision and Recall
The F1 score is a crucial metric in data science that balances precision and recall to evaluate classification models, especially when dealing with imbalanced datasets. By calculating the harmonic mean of precision and recall, the F1 score provides a single value that reflects both false positives and false negatives, making it more informative than accuracy in many scenarios. This balance helps optimize models for applications like fraud detection or medical diagnosis, where both types of classification errors have significant consequences.
Importance of Recall in Imbalanced Datasets
Recall plays a critical role in imbalanced datasets by measuring the proportion of true positive instances correctly identified, which is essential when missing positive cases carries significant consequences. High recall ensures that minority class examples, often underrepresented and crucial, are captured effectively, reducing false negatives that could lead to costly errors in applications like fraud detection or medical diagnosis. While the F1 score balances recall and precision, prioritizing recall in highly skewed datasets is vital to mitigate bias against the minority class and improve overall model reliability.
Why Use F1 Score Over Recall Alone?
Using the F1 score over recall alone provides a balanced evaluation by combining both precision and recall, which is crucial in data science tasks where false positives and false negatives have significant impacts. Unlike recall, which only measures the ability to identify true positives, the F1 score accounts for precision, reflecting the accuracy of positive predictions. This balance ensures a more robust metric for model performance, especially in imbalanced datasets where relying solely on recall could lead to misleading conclusions.
Mathematical Formulas: Recall vs F1 Score
Recall, defined as TP / (TP + FN), measures the proportion of true positives identified out of all actual positives, emphasizing sensitivity in classification tasks. The F1 score, calculated as 2 * (Precision * Recall) / (Precision + Recall), represents the harmonic mean of precision and recall, balancing false positives and false negatives. These formulas highlight recall's focus on detecting all positive instances while the F1 score provides a single metric that balances accuracy and completeness in predictive modeling.
Use Cases: When to Prioritize Recall
Recall is critical in scenarios like medical diagnosis or fraud detection where missing a positive case has severe consequences, ensuring fewer false negatives. Prioritizing recall is essential in safety-critical applications, such as identifying defective products in manufacturing or detecting cyber-attacks, to capture as many true positives as possible. While the F1 score balances precision and recall, recall-focused models are preferred when the cost of overlooking positive instances outweighs false positives.
Scenarios Favoring F1 Score in Model Evaluation
F1 score excels in scenarios where balancing precision and recall is critical, such as imbalanced datasets or fraud detection, where missing positive cases and false alarms both carry significant consequences. Its harmonic mean approach provides a more comprehensive evaluation than recall alone, especially in applications like medical diagnostics and spam detection. Optimizing for F1 score ensures models effectively minimize both false negatives and false positives, enhancing overall reliability in predictive performance.
Interpreting Results: Practical Implications
Recall measures the ability to identify all relevant positive cases, making it crucial in situations where missing true positives has significant consequences, such as medical diagnostics or fraud detection. F1 score balances recall and precision, providing a single metric to evaluate overall model performance when both false positives and false negatives carry costs. In practical applications, prioritizing recall may lead to more false alarms, while a higher F1 score ensures a trade-off that maintains both sensitivity and specificity for balanced decision-making.
Recall vs F1 Score: Choosing the Right Metric for Your Project
Recall measures the proportion of true positive instances correctly identified, making it critical in scenarios where missing positive cases is costly, such as medical diagnosis or fraud detection. F1 Score balances precision and recall, providing a single metric that is especially useful when the class distribution is imbalanced and both false positives and false negatives carry significant consequences. Selecting between recall and F1 Score depends on the specific project goals, the relative importance of false negatives versus false positives, and the trade-offs acceptable in the application domain.
recall vs F1 score Infographic