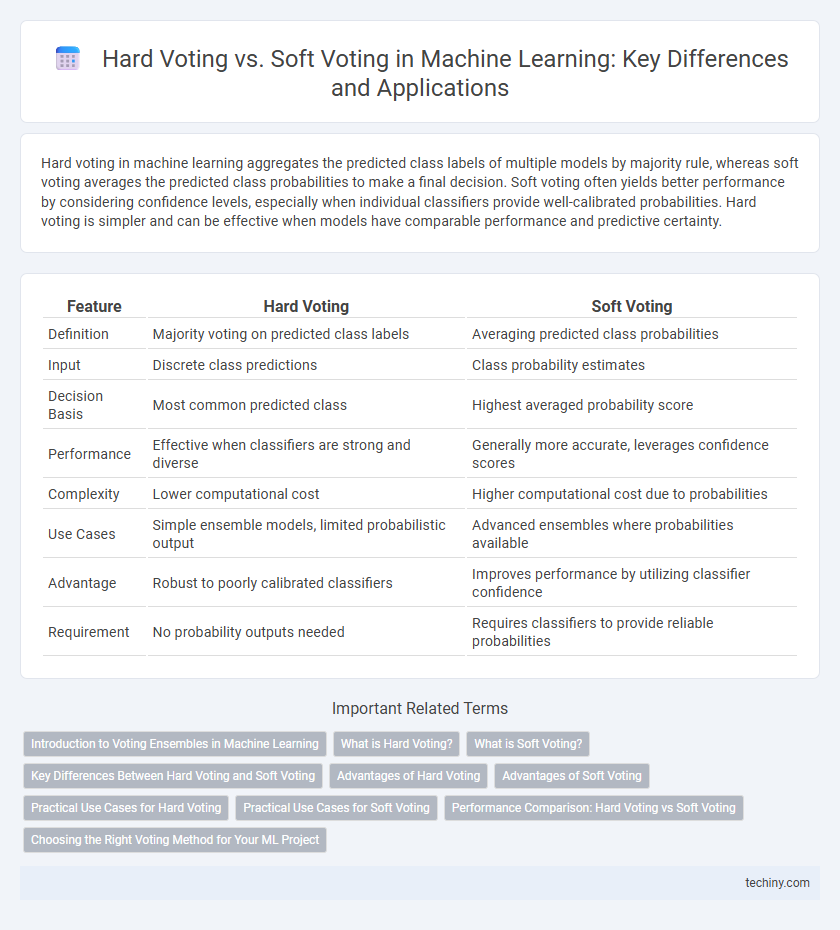
Hard voting in machine learning aggregates the predicted class labels of multiple models by majority rule, whereas soft voting averages the predicted class probabilities to make a final decision. Soft voting often yields better performance by considering confidence levels, especially when individual classifiers provide well-calibrated probabilities. Hard voting is simpler and can be effective when models have comparable performance and predictive certainty.
Table of Comparison
| Feature | Hard Voting | Soft Voting |
|---|---|---|
| Definition | Majority voting on predicted class labels | Averaging predicted class probabilities |
| Input | Discrete class predictions | Class probability estimates |
| Decision Basis | Most common predicted class | Highest averaged probability score |
| Performance | Effective when classifiers are strong and diverse | Generally more accurate, leverages confidence scores |
| Complexity | Lower computational cost | Higher computational cost due to probabilities |
| Use Cases | Simple ensemble models, limited probabilistic output | Advanced ensembles where probabilities available |
| Advantage | Robust to poorly calibrated classifiers | Improves performance by utilizing classifier confidence |
| Requirement | No probability outputs needed | Requires classifiers to provide reliable probabilities |
Introduction to Voting Ensembles in Machine Learning
Voting ensembles in machine learning combine predictions from multiple models to improve overall accuracy and robustness. Hard voting aggregates discrete class labels by majority rule, while soft voting averages predicted probabilities to make a final decision. Using voting ensembles leverages the strengths of diverse classifiers, reducing individual model biases and variance.
What is Hard Voting?
Hard voting in machine learning is an ensemble technique where multiple classifiers predict class labels independently, and the final prediction is determined by majority voting. Each base model casts a single vote for the predicted class, and the class with the most votes is selected as the ensemble's output. This method is effective for classification tasks by leveraging diverse models to improve overall accuracy and robustness.
What is Soft Voting?
Soft voting in machine learning ensemble methods refers to combining the predicted class probabilities from multiple classifiers to make a final prediction, rather than relying solely on the predicted classes. This approach aggregates the probability scores for each class and selects the class with the highest average probability, which often leads to improved accuracy and robustness. Soft voting is particularly effective when individual classifiers output well-calibrated probabilities, enhancing performance in diverse classification tasks.
Key Differences Between Hard Voting and Soft Voting
Hard voting aggregates the most common predicted class from multiple classifiers, making it a majority-rule approach ideal for discrete output scenarios. Soft voting averages the predicted class probabilities from all classifiers and selects the class with the highest average probability, providing a nuanced decision based on confidence levels. Key differences include hard voting's reliance on discrete class labels versus soft voting's use of probabilistic outputs, which often leads to improved accuracy in soft voting due to its consideration of prediction uncertainty.
Advantages of Hard Voting
Hard voting combines predictions from multiple classifiers by selecting the most frequent class, enhancing model robustness and reducing overfitting risks. It simplifies decision-making through majority rule, making it computationally efficient and easier to interpret. This method performs well in diverse datasets where individual classifiers have varying strengths, often leading to improved accuracy and stability.
Advantages of Soft Voting
Soft voting leverages predicted class probabilities from multiple classifiers, leading to more nuanced decision-making and improved accuracy compared to hard voting, which relies solely on majority class predictions. By weighting votes according to confidence levels, soft voting effectively reduces the risk of misclassification and enhances model robustness. This approach is especially advantageous in ensemble methods like Random Forests and Gradient Boosting, where probabilistic outputs provide richer information than categorical labels.
Practical Use Cases for Hard Voting
Hard voting excels in practical machine learning applications where interpretability and decisive class labeling are crucial, such as fraud detection systems and medical diagnosis tools. It aggregates the majority class predictions from diverse base classifiers, ensuring robustness against individual model errors and simplifying decision boundaries. This technique is effective in ensemble methods like random forests, where categorical outcomes must be clearly defined without probabilistic ambiguity.
Practical Use Cases for Soft Voting
Soft voting in machine learning excels in scenarios where prediction probabilities provide richer information than mere class counts, such as in ensemble methods combining classifiers with varying confidence levels. It is particularly useful in applications like fraud detection and medical diagnosis, where the weighted average of predicted probabilities enhances decision accuracy and reduces the risk of misclassification. Soft voting leverages the probabilistic outputs of base models, improving performance in complex classification tasks with imbalanced or overlapping classes.
Performance Comparison: Hard Voting vs Soft Voting
Soft voting generally yields higher predictive accuracy than hard voting by averaging the predicted probabilities of classifiers, allowing for more nuanced decision-making. Hard voting aggregates discrete class predictions, which may overlook the confidence levels of individual classifiers, often leading to less optimal performance. Empirical comparisons reveal soft voting's superiority in handling class imbalance and improving ensemble robustness in machine learning tasks.
Choosing the Right Voting Method for Your ML Project
Choosing the right voting method for your machine learning project depends on the specific task and dataset characteristics. Hard voting aggregates discrete class predictions from base models, making it suitable for scenarios requiring clear consensus and interpretability. Soft voting leverages predicted class probabilities, enhancing performance when models produce calibrated probabilities and probabilities reflect uncertainty accurately.
Hard Voting vs Soft Voting Infographic