Strong learners achieve high accuracy independently by capturing complex patterns in data, while weak learners perform slightly better than random guessing and typically require ensemble methods like boosting to improve performance. Combining multiple weak learners enhances model robustness and reduces overfitting, leveraging their collective strengths. Understanding the balance between these learners is crucial for designing efficient machine learning algorithms.
Table of Comparison
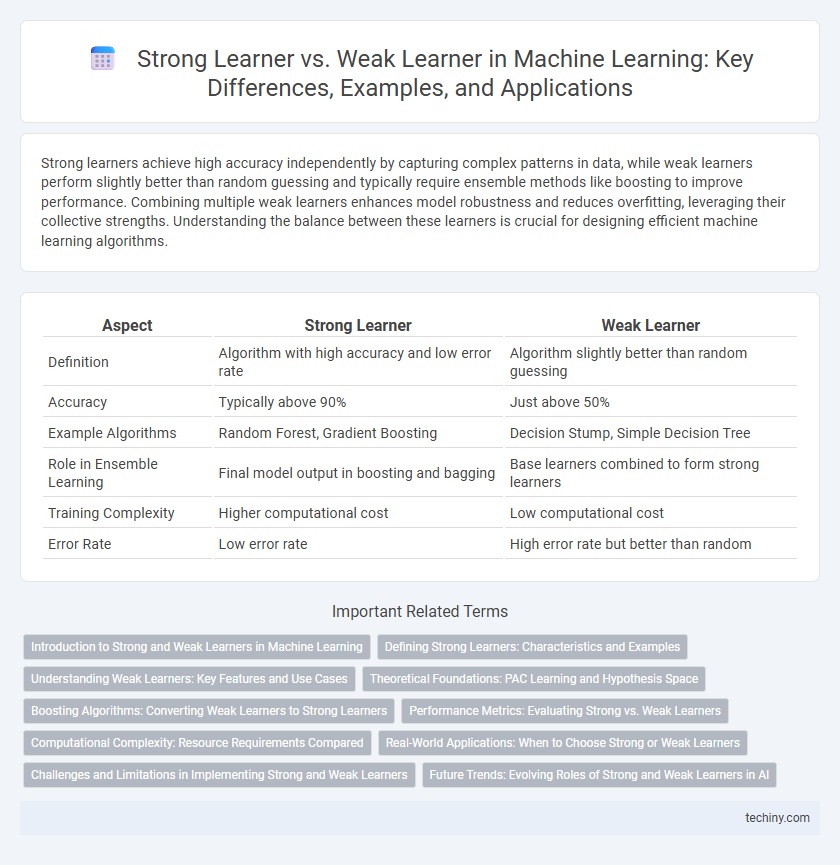
| Aspect | Strong Learner | Weak Learner |
|---|---|---|
| Definition | Algorithm with high accuracy and low error rate | Algorithm slightly better than random guessing |
| Accuracy | Typically above 90% | Just above 50% |
| Example Algorithms | Random Forest, Gradient Boosting | Decision Stump, Simple Decision Tree |
| Role in Ensemble Learning | Final model output in boosting and bagging | Base learners combined to form strong learners |
| Training Complexity | Higher computational cost | Low computational cost |
| Error Rate | Low error rate | High error rate but better than random |
Introduction to Strong and Weak Learners in Machine Learning
Strong learners in machine learning are models that achieve high accuracy by correctly classifying most training examples, often characterized by their low bias and robust generalization capabilities. Weak learners, in contrast, are only marginally better than random guessing and possess higher bias, but they serve as foundational components in ensemble methods like boosting to improve overall performance. Understanding the distinction between strong and weak learners is crucial for selecting appropriate algorithms and optimizing predictive models.
Defining Strong Learners: Characteristics and Examples
Strong learners in machine learning are algorithms that achieve high accuracy on both training and test datasets by effectively capturing complex patterns. These learners exhibit low bias, high variance control, and robust generalization capabilities, examples include Support Vector Machines (SVMs), deep neural networks, and gradient boosting machines. Their ability to minimize error and adapt to diverse data distributions distinguishes them from weak learners, which typically perform only slightly better than random guessing.
Understanding Weak Learners: Key Features and Use Cases
Weak learners are machine learning models that perform slightly better than random guessing, typically exhibiting high bias and low complexity. They serve as foundational components in ensemble methods like boosting, where multiple weak learners are combined to create a strong learner with improved accuracy. Common weak learners include decision stumps and shallow trees, which are preferred in scenarios requiring rapid training and reduced overfitting risks.
Theoretical Foundations: PAC Learning and Hypothesis Space
Strong learners in Machine Learning achieve arbitrarily low error rates given sufficient training data, as established by the Probably Approximately Correct (PAC) learning framework, which quantifies learnability in terms of hypothesis space complexity and sample efficiency. Weak learners, conversely, only guarantee performance marginally better than random guessing but can be boosted through ensemble methods to form strong learners. The size and structure of the hypothesis space directly influence the sample complexity and generalization bounds, critical parameters in designing learning algorithms under PAC assumptions.
Boosting Algorithms: Converting Weak Learners to Strong Learners
Boosting algorithms enhance predictive accuracy by sequentially combining weak learners, which perform slightly better than random guessing, into a strong learner with high overall performance. Each weak learner focuses on the errors of its predecessors, effectively reducing bias and variance in the aggregated model. This iterative process, exemplified by AdaBoost and Gradient Boosting, transforms weak individual classifiers into a robust ensemble capable of capturing complex data patterns.
Performance Metrics: Evaluating Strong vs. Weak Learners
Performance metrics such as accuracy, precision, recall, and F1-score critically differentiate strong learners from weak learners in machine learning models. Strong learners consistently achieve higher scores across these metrics, indicating superior generalization and robustness on unseen data. Weak learners show marginal improvements over random guessing and often require ensemble methods like boosting to enhance overall predictive performance.
Computational Complexity: Resource Requirements Compared
Strong learners require significantly higher computational resources due to their complex model architectures and extensive training data processing, resulting in increased memory usage and longer training times. Weak learners, such as simple decision stumps or small neural networks, have minimal computational overhead, making them suitable for scenarios with limited processing power or when fast training is essential. Ensemble methods like boosting combine multiple weak learners to achieve strong learner performance while balancing computational efficiency and accuracy.
Real-World Applications: When to Choose Strong or Weak Learners
Strong learners excel in complex real-world applications requiring high accuracy, such as medical diagnosis and fraud detection, due to their ability to model intricate patterns. Weak learners are preferred in ensemble methods like boosting, where combining multiple simple models improves performance while maintaining computational efficiency. Selecting between strong and weak learners depends on the trade-off between accuracy needs and resource constraints in practical deployments.
Challenges and Limitations in Implementing Strong and Weak Learners
Strong learners demand extensive computational resources and large labeled datasets, creating challenges in scalability and training time. Weak learners, while simpler and faster, often struggle with high bias and limited predictive accuracy, necessitating ensemble methods to boost performance. Balancing model complexity and generalization remains a significant limitation when implementing both strong and weak learners in practical machine learning applications.
Future Trends: Evolving Roles of Strong and Weak Learners in AI
Future trends in machine learning highlight the evolving roles of strong and weak learners in AI, where strong learners are increasingly integrated into complex systems requiring high accuracy and robustness, while weak learners remain vital in ensemble methods to boost predictive performance through diversity. Advances in meta-learning and federated learning frameworks leverage the complementary strengths of both learner types to enhance adaptability and privacy in real-world applications. Emerging AI architectures emphasize dynamic learner selection and hybrid models to optimize efficiency and scalability across diverse data environments.
Strong Learner vs Weak Learner Infographic