Support Vector Machines (SVM) excel in high-dimensional spaces and maintain robust performance with clear margin separation, making them ideal for complex classification tasks. Decision Trees offer intuitive interpretability and handle both numerical and categorical data efficiently but can suffer from overfitting without proper pruning. Choosing between SVM and Decision Trees depends on the dataset size, feature space, and the need for model transparency versus margin-based optimization.
Table of Comparison
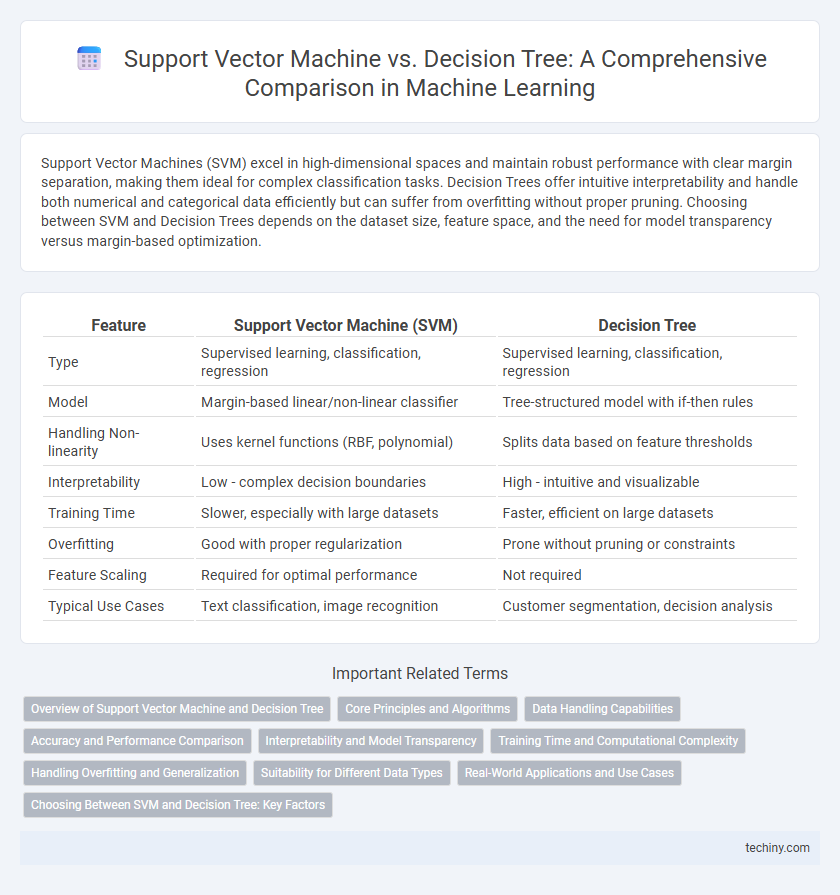
| Feature | Support Vector Machine (SVM) | Decision Tree |
|---|---|---|
| Type | Supervised learning, classification, regression | Supervised learning, classification, regression |
| Model | Margin-based linear/non-linear classifier | Tree-structured model with if-then rules |
| Handling Non-linearity | Uses kernel functions (RBF, polynomial) | Splits data based on feature thresholds |
| Interpretability | Low - complex decision boundaries | High - intuitive and visualizable |
| Training Time | Slower, especially with large datasets | Faster, efficient on large datasets |
| Overfitting | Good with proper regularization | Prone without pruning or constraints |
| Feature Scaling | Required for optimal performance | Not required |
| Typical Use Cases | Text classification, image recognition | Customer segmentation, decision analysis |
Overview of Support Vector Machine and Decision Tree
Support Vector Machine (SVM) is a supervised learning algorithm primarily used for classification and regression tasks, optimizing a hyperplane to maximize the margin between data classes. Decision Tree is a tree-structured model that splits data based on feature values, enabling easy interpretation and handling of both categorical and numerical data. SVM excels in high-dimensional spaces with clear margin separation, while Decision Trees offer flexibility and interpretability in complex hierarchical decision boundaries.
Core Principles and Algorithms
Support Vector Machines (SVM) operate by finding the optimal hyperplane that maximizes the margin between classes, leveraging kernel functions to handle non-linear separations. Decision Trees use a hierarchical structure based on feature splits, recursively partitioning data to minimize impurity measures like Gini index or entropy. Both algorithms employ distinct optimization strategies: SVMs solve convex quadratic programming problems, while Decision Trees apply greedy heuristics for feature selection during tree construction.
Data Handling Capabilities
Support Vector Machines (SVM) excel in handling high-dimensional data and are effective for complex classification tasks with clear margin separation, especially in sparse datasets. Decision Trees manage varied data types well and are robust to missing values, offering interpretable rules but may struggle with overfitting in high-dimensional spaces. SVM requires feature scaling and performs best with well-structured, clean data, while Decision Trees tolerate noisy data better without extensive preprocessing.
Accuracy and Performance Comparison
Support Vector Machines (SVM) generally achieve higher accuracy in high-dimensional spaces and are effective with clear margin separation, while Decision Trees excel in interpretability and faster training times on smaller datasets. SVM's performance can degrade with large datasets due to computational complexity, whereas Decision Trees scale more efficiently but risk overfitting without pruning techniques. Benchmark studies show SVM often outperforms Decision Trees in complex classification tasks, especially with non-linear boundaries, but Decision Trees provide competitive results for structured or categorical data.
Interpretability and Model Transparency
Support Vector Machines (SVM) offer strong classification performance but often lack interpretability due to the complexity of their kernel functions and high-dimensional decision boundaries. Decision Trees provide high model transparency by representing decisions as simple, visual if-then rules that are easily understood by humans. For applications requiring clear interpretability and straightforward decision explanations, Decision Trees are generally favored over SVMs.
Training Time and Computational Complexity
Support Vector Machines (SVM) typically exhibit higher training time and computational complexity, especially with large datasets, due to the quadratic optimization involved in finding the optimal hyperplane. Decision Trees generally have faster training times and lower computational costs, as their recursive partitioning approach scales more efficiently with data size. In scenarios requiring quick model updates, Decision Trees outperform SVMs in terms of computational resource utilization and training efficiency.
Handling Overfitting and Generalization
Support Vector Machines (SVM) effectively handle overfitting by maximizing the margin between classes and using kernel functions to map input data into higher-dimensional spaces, enhancing generalization on unseen data. Decision Trees are prone to overfitting due to their hierarchical structure but can improve generalization through pruning techniques and ensemble methods like Random Forests. SVMs generally provide better generalization in high-dimensional spaces, while Decision Trees excel in interpretability and dealing with categorical features.
Suitability for Different Data Types
Support Vector Machines (SVM) excel with high-dimensional, continuous data by finding optimal hyperplanes for classification, making them ideal for text and image recognition tasks. Decision Trees handle both categorical and continuous data effectively, providing clear interpretability and managing complex interactions and missing values well. SVM struggles with noisy, overlapping classes, whereas Decision Trees are better suited for heterogeneous data and datasets with mixed feature types.
Real-World Applications and Use Cases
Support Vector Machines (SVMs) excel in high-dimensional spaces, making them ideal for image classification, bioinformatics, and text categorization tasks where clear margin separation is crucial. Decision Trees provide interpretable models suited for credit scoring, customer segmentation, and medical diagnosis, handling categorical and numerical data effectively with straightforward rule extraction. Both algorithms demonstrate strong performance in fraud detection and predictive maintenance but differ fundamentally in model complexity and data assumptions.
Choosing Between SVM and Decision Tree: Key Factors
Choosing between Support Vector Machine (SVM) and Decision Tree depends primarily on data complexity and interpretability needs. SVM excels in high-dimensional spaces and complex boundary delineation, making it ideal for text classification or image recognition tasks. Decision Tree offers straightforward interpretability and faster computation, favored in scenarios requiring transparent decision-making and handling categorical variables.
Support Vector Machine vs Decision Tree Infographic