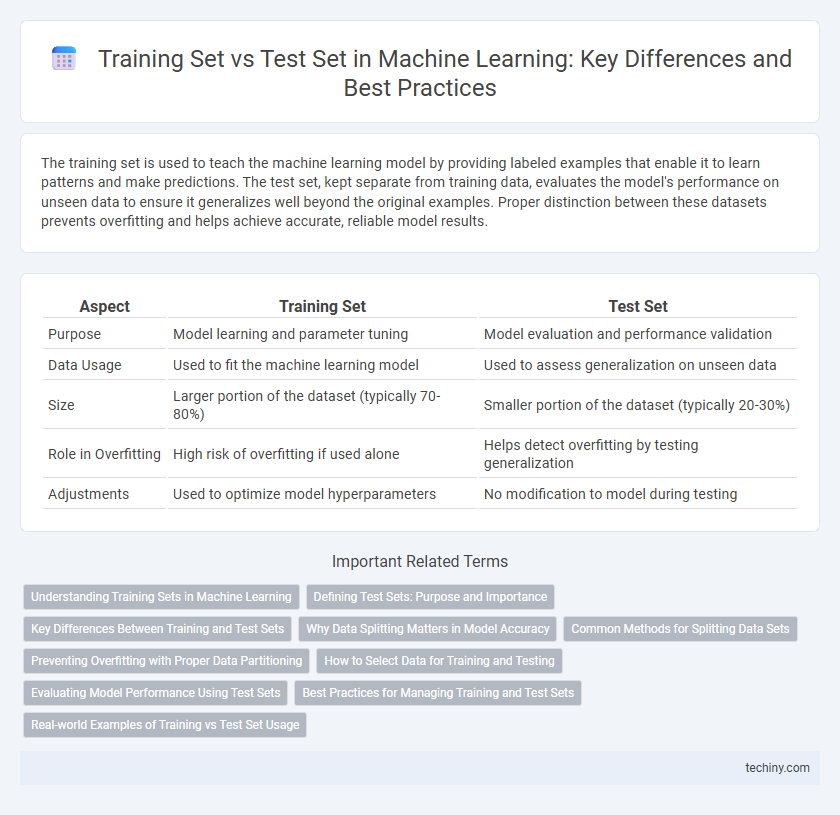
The training set is used to teach the machine learning model by providing labeled examples that enable it to learn patterns and make predictions. The test set, kept separate from training data, evaluates the model's performance on unseen data to ensure it generalizes well beyond the original examples. Proper distinction between these datasets prevents overfitting and helps achieve accurate, reliable model results.
Table of Comparison
| Aspect | Training Set | Test Set |
|---|---|---|
| Purpose | Model learning and parameter tuning | Model evaluation and performance validation |
| Data Usage | Used to fit the machine learning model | Used to assess generalization on unseen data |
| Size | Larger portion of the dataset (typically 70-80%) | Smaller portion of the dataset (typically 20-30%) |
| Role in Overfitting | High risk of overfitting if used alone | Helps detect overfitting by testing generalization |
| Adjustments | Used to optimize model hyperparameters | No modification to model during testing |
Understanding Training Sets in Machine Learning
Training sets in machine learning are crucial for enabling algorithms to learn patterns and make predictions by providing labeled data samples during the model's development phase. The quality and diversity of the training set directly influence the model's accuracy and generalization ability, ensuring it performs well on unseen data. Selecting representative and well-balanced training data reduces overfitting and enhances the robustness of machine learning models.
Defining Test Sets: Purpose and Importance
Test sets are crucial for evaluating the generalization ability of machine learning models by providing an unbiased assessment of performance on unseen data. Unlike training sets, which the model learns from, test sets simulate real-world scenarios to detect overfitting and ensure robustness. Properly defined test sets maintain data distribution consistency while excluding any overlap with training data to deliver accurate performance metrics.
Key Differences Between Training and Test Sets
Training sets contain labeled data used to teach machine learning models by allowing them to learn patterns and relationships, while test sets consist of unseen data used to evaluate model performance and generalization ability. Training sets influence model parameters through iterative optimization, whereas test sets provide an unbiased metric to assess accuracy, precision, recall, or other performance metrics. The distinction ensures models avoid overfitting by validating their predictive power on independent data not exposed during training.
Why Data Splitting Matters in Model Accuracy
Data splitting into training and test sets is crucial for unbiased model evaluation and generalization in machine learning. The training set enables the model to learn underlying patterns, while the test set provides an independent benchmark to assess performance on unseen data. Proper data splitting prevents overfitting and ensures the model's accuracy reflects real-world predictions, maintaining validity and robustness.
Common Methods for Splitting Data Sets
Common methods for splitting data sets in machine learning include holdout, k-fold cross-validation, and stratified sampling. The holdout method divides data into distinct training and test sets, typically using a 70-30 or 80-20 ratio. K-fold cross-validation enhances model evaluation by partitioning data into k subsets and iteratively using each subset as a test set while training on the remaining folds, improving reliability and reducing bias.
Preventing Overfitting with Proper Data Partitioning
Proper partitioning of data into training and test sets is crucial for preventing overfitting in machine learning models. Training sets enable the model to learn underlying patterns, while test sets provide unbiased evaluation to ensure generalization to unseen data. Maintaining a clear separation between these sets helps avoid data leakage and promotes model robustness across real-world applications.
How to Select Data for Training and Testing
Selecting data for training and testing involves ensuring the training set represents the full feature distribution to enable effective model learning, while the test set remains unseen to provide an unbiased evaluation of performance. Stratified sampling techniques maintain class balance across both datasets, reducing sampling bias and overfitting risks. Proper partitioning, typically using an 80/20 or 70/30 split, preserves data integrity and supports generalization by preventing data leakage between sets.
Evaluating Model Performance Using Test Sets
Evaluating model performance using test sets involves measuring accuracy, precision, recall, and F1 score on unseen data to ensure generalization beyond the training set. The test set acts as an unbiased benchmark, helping detect overfitting or underfitting by comparing predictions against actual outcomes. Reliable evaluation on the test set is crucial for selecting models that maintain robustness in real-world applications.
Best Practices for Managing Training and Test Sets
Effective management of training and test sets ensures reliable machine learning model evaluation and prevents data leakage. Best practices include maintaining strict separation between training and test data, using stratified sampling to preserve class distribution, and applying cross-validation techniques to enhance model generalization. Proper dataset partitioning, along with consistent preprocessing applied only to training data before testing, optimizes model performance and robustness.
Real-world Examples of Training vs Test Set Usage
In machine learning, the training set consists of labeled data used to teach algorithms patterns, while the test set evaluates model performance on unseen data to ensure generalization. For instance, in autonomous driving, training sets include diverse driving scenarios collected under varied weather and lighting conditions, whereas test sets focus on novel environments to assess robustness. Real-world applications like fraud detection rely on carefully partitioned training and test sets to detect patterns accurately and prevent overfitting.
training set vs test set Infographic